
Reasoning Models Generate Societies of Thought
推理模型生成思想社会
Abstract 摘要
Large language models have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive1, 2. Recent reasoning-reinforced models, including OpenAI’s o-series, DeepSeek-R1, and QwQ-32B, outperform comparable instruction-tuned models on complex cognitive tasks3, 4, attributed to extended test-time computation through longer chains of thought5. Here we show that enhanced reasoning emerges not from extended computation alone, but from the implicit simulation of complex, multi-agent-like interactions—a society of thought—which enables the deliberate diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis using classified outputs and mechanistic interpretability methods applied to reasoning traces6, 7, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than baseline and merely instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviours including question-answering sequences, perspective shifts, and reconciliation of conflicting views, as well as in socio-emotional roles that characterize sharp back-and-forth conversation, which together account for the accuracy advantage in reasoning tasks through both direct and indirect facilitation of cognitive strategies8, 9. Controlled reinforcement learning experiments further reveal that base models spontaneously increase conversational behaviours when solely rewarded for reasoning accuracy, and fine-tuning models with conversational scaffolding substantially accelerates reasoning improvement compared to base models and models fine-tuned with monologue-like reasoning. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups10, 11, 12, where diversity enables superior problem-solving when systematically structured and suggest new opportunities for agent organization to harness the wisdom of crowds.
大型语言模型在各个领域取得了显著的成就,然而复杂推理背后的机制仍然难以捉摸 1, 2 。最近的推理强化模型,包括 OpenAI 的 o 系列、DeepSeek-R1 和 QwQ-32B,在复杂认知任务上优于同等指令调优模型 3, 4 ,这归因于通过更长的思维链延长了测试时的计算 5 。在这里我们表明,增强的推理并非仅来自计算的延长,而是来自对复杂、类似多智能体交互的隐式模拟——一个思想社会,它使得具有不同人格特质和领域专业知识的内部认知视角之间能够进行有意识的多样化和辩论。通过使用分类输出和应用于推理轨迹的机制可解释方法进行定量分析 6, 7 ,我们发现 DeepSeek-R1 和 QwQ-32B 等推理模型比基线和仅指令调优模型表现出更大的视角多样性,在推理过程中激活了异质人格和专业知识相关特征之间更广泛的冲突。 这种多智能体结构体现在对话行为中,包括问答序列、视角转换以及冲突观点的调和,同时也体现在社会情感角色中,这些角色以尖锐的来回对话为特征,共同通过直接和间接的认知策略促进,解释了推理任务中的准确性优势 8, 9 。受控的强化学习实验进一步揭示,基础模型在仅因推理准确性而受到奖励时,会自发地增加对话行为,而带有对话脚手架的微调模型与基础模型以及进行类似独白式推理微调的模型相比,能显著加速推理能力的提升。这些发现表明,思想的社交组织能够有效探索解决方案空间。我们建议推理模型建立与人类群体集体智能的计算平行关系 10, 11, 12 ,其中多样性在系统结构化时能够实现优越的问题解决能力,并为智能体组织利用群体智慧提供了新的机遇。
Corresponding author: James Evans (jamesaevans@google.com; jevans@uchicago.edu)
通讯作者:詹姆斯·埃文斯 (jamesaevans@google.com; jevans@uchicago.edu)
Work done as a student researcher at Google
作为谷歌学生研究员完成的工作
Artificial intelligence (AI) systems have undergone a remarkable transformation in recent years, with large language models (LLMs) demonstrating increasingly sophisticated abilities across domains, from mathematics and code to scientific and creative writing to critical decision support1, 2. Nevertheless, a persistent challenge has been the development of robust reasoning capabilities—the ability to methodically analyze problems, consider alternatives, detect errors, and arrive at reliable conclusions. Recent reasoning models, such as DeepSeek-R1, QwQ, and OpenAI’s o-series models (o1, o3, o4), are trained by reinforcement learning to “think” before they respond, generating lengthy “chains of thought”. This led to substantial improvement in reasoning accuracy compared to existing instruction-tuned language models (e.g., DeepSeek-V3, Qwen-2.5, GPT-4.1)3, 4. Yet, the character of “thinking” within reasoning models that drives success remains underexplored.
近年来,人工智能(AI)系统经历了显著变革,大型语言模型(LLMs)在数学、代码、科学和创意写作以及关键决策支持等领域展现出日益复杂的能力 1, 2 。然而,一个持续的挑战是发展强大的推理能力——即系统性地分析问题、考虑替代方案、检测错误并得出可靠结论的能力。最近的推理模型,如 DeepSeek-R1、QwQ 和 OpenAI 的 o 系列模型(o1、o3、o4),通过强化学习被训练在回应前“思考”,生成冗长的“思维链”。与现有的指令微调语言模型(例如,DeepSeek-V3、Qwen-2.5、GPT-4.1)相比,这显著提高了推理准确性 3, 4 。然而,驱动推理模型成功的“思考”特性仍待深入探索。
We propose that reasoning models learn to emulate social, multi-agent-like dialogue between multiple perspectives—what we term a “society of thought”—to improve their reasoning, given the centrality of social interaction to the development of reason in both cognitive and social scientific accounts. Mercier and Sperber’s “Enigma of Reason” argument posits that human reasoning evolved primarily as a social process, with knowledge emerging through adversarial reasoning and engagement across differing viewpoints10. Empirical work supports the idea that groups outperform individuals on a wide range of reasoning tasks by pooling information, calibrating confidence, and exhibiting collective intelligence through balanced turn-taking among diverse perspectives13, 14, 12, 15. Cognitive diversity, stemming from variation in expertise and personality traits, enhances problem solving, particularly when accompanied by authentic dissent16, 17, 18, 19, 11, 20, 21, 22. Together, these findings suggest that robust reasoning emerges through interaction and the integration of diverse perspectives, and that key reasoning strategies, including verification and backtracking, may be realized through the conversation of simulated personas.
我们提出,推理模型通过学习模拟多视角之间的社会性、多智能体式对话——我们称之为“思想社会”——来提升其推理能力,鉴于社会互动在认知和社会科学理论中对理性发展的核心作用。Mercier 和 Sperber 的《理性的谜题》论证认为,人类推理主要是作为一种社会过程进化而来的,知识通过不同观点间的对抗性推理和参与而涌现 10 。实证研究支持这样一种观点:通过汇集信息、校准信心,并在不同视角间通过平衡的轮流发言展现出集体智能,群体在广泛的推理任务上优于个体 13, 14, 12, 15 。认知多样性,源于专业知识和性格特征的差异,能够提升问题解决能力,尤其是在伴随着真诚的异议时 16, 17, 18, 19, 11, 20, 21, 22 。 这些发现共同表明,强大的推理能力是通过互动和不同观点的整合而出现的,而关键的推理策略,包括验证和回溯,可能可以通过模拟角色的对话来实现。
While diversity and debate contribute directly to collective intelligence, many theories further suggest that individuals reason better when they simulate this capacity. A single, self-centered perspective can lead to systematic biases in reasoning; if individuals effectively simulate multiple, self-distanced perspectives with their minds, as in dialectical thinking, this can reduce decision biases within them23, 24, 25. The “social brain hypothesis” suggests that higher-order intelligence primarily evolved to meet the cognitive demands of processing and simulating social interactions26, 27. Individuals who simulate others’ differing perspectives through improved “theory-of-mind” capabilities enhance collective team performance18. Furthermore, theorists have argued that individual reason itself emerged from a simulation of collective discourse. Bakhtin’s notion of the “dialogic self” and Cooley and Mead’s theory of the “looking glass self” argue that human thought itself takes the form of an internalized conversation among multiple perspectives28, 29, 30, Mead2022-rw. Even in the history of artificial intelligence, Minsky conceptualized intelligence as an emergent property of interacting cognitive agents, or a “Society of Mind”31.
虽然多样性和辩论直接有助于集体智慧,但许多理论进一步指出,当个体模拟这种能力时,他们的推理能力会更好。单一的自我中心视角会导致推理中的系统性偏差;如果个体通过心灵有效地模拟多个、自我疏离的视角,就像辩证思维那样,这可以减少他们决策中的偏差 23, 24, 25 。 “社会大脑假说”认为,高级智慧主要进化是为了满足处理和模拟社会互动的认知需求 26, 27 。通过改进“心智理论”能力来模拟他人不同视角的个体,可以增强集体团队的表现 18 。此外,理论家们认为,个体推理本身是从集体话语的模拟中产生的。巴赫金关于“对话自我”的概念以及库利和米德的“镜像自我”理论都认为,人类思维本身就呈现出多重视角内部化对话的形式 28, 29, 30, Mead2022-rw 。 即使在人工智能的历史中,明斯基也将智能概念化为交互认知主体的涌现属性,或是一个“心智社会” 31 。
Therefore, whether AI systems directly simulate multi-agent discourse or simulate minds that, in turn, simulate multi-agent discourse, we propose that reasoning models like DeepSeek-R1 improve reasoning via “society of thought”—implicit simulations of multi-agent-like interactions between diverse perspectives that give rise to them. We use the term to denote text generation that simulates social exchange among multiple perspectives to increase the collective diversity of ideas through conversational roles that put them in competition. Without deploying separate models prompted to interact with one another32, 33, 34, we suggest that behaviourally similar conversations between diverse perspectives occur and are leveraged within reasoning models.
因此,无论是人工智能系统直接模拟多主体对话,还是模拟那些反过来模拟多主体对话的心灵,我们都提出推理模型(如 DeepSeek-R1)通过“思想社会”——即不同视角之间产生互动的隐式模拟——来提升推理能力。我们使用这一术语来指代模拟多重视角之间社会交流的文本生成,通过对话角色将它们置于竞争状态,从而增加思想的集体多样性。在不部署分别提示以相互交互的模型 32, 33, 34 的情况下,我们建议不同视角之间的行为相似对话会发生,并在推理模型中被利用。
Reasoning models like DeepSeek-R1 develop reasoning abilities through reinforcement learning, which iteratively compensates reasoning behaviour that yields correct answers. Following these performance improvements, debates have naturally arisen about what kinds of behaviours contribute to better reasoning performance. While earlier studies focus on how the model learns to scale test-time computations and generate longer reasoning traces35, 2, merely increasing trace length does not account for the observed improvements in reasoning capabilities. This suggests that qualitative changes in reasoning structure matter more than quantitative scaling alone36, 35, 37. Recent analyses pinpoint behavioural patterns that improve reasoning accuracy, such as verification of earlier assumptions, backtracking, and exploration of alternatives4, 8, 36, 35, 37. Mechanistic interpretability research has shown that features in language models such as the frequent use of words like “wait,” “but,” and “however”—are associated with these behaviours38, 39, 40, 41. The characteristics of these features, however, such as their prevalence in social and conversational settings, have rarely been explored. Research in other contexts has suggested that the simulation of multi-agent conversations can boost accuracy and divergent thinking in LLMs42, 43, 44, 45, 46, 34, 47. While LLMs can exhibit cognitive biases that hinder reasoning, the simulation of interaction between different perspectives could mitigate biases when verified through checks and balances48, 34, 49. This leads us to hypothesize that reinforcement learning may systematically select and reward behaviour patterns that resemble multi-agent interactions within reasoning models, and these simulated interactions enable models to reason effectively.
深度推理模型如 DeepSeek-R1 通过强化学习发展推理能力,该过程通过迭代补偿产生正确答案的推理行为。在性能提升之后,自然产生了关于哪些行为有助于提升推理性能的讨论。早期研究主要关注模型如何学习扩展测试时的计算并生成更长的推理轨迹 35, 2 ,但仅仅增加轨迹长度并不能解释推理能力的提升。这表明推理结构的定性变化比单纯的定量扩展更为重要 36, 35, 37 。最近的分析指出了提升推理准确性的行为模式,例如验证早期假设、回溯和探索替代方案 4, 8, 36, 35, 37 。机制可解释性研究显示,语言模型中的某些特征,如频繁使用“wait”、“but”和“however”等词语——与这些行为相关 38, 39, 40, 41 。然而,这些特征的特性,如它们在社会和对话环境中的普遍性,却很少被探索。 其他领域的研究表明,模拟多智能体对话可以提高 LLMs 的准确性和发散性思维 42, 43, 44, 45, 46, 34, 47 。虽然 LLMs 可能表现出阻碍推理的认知偏差,但通过制衡机制验证的不同视角之间的交互模拟可以减轻这些偏差 48, 34, 49 。这使我们假设,强化学习可能会系统地选择和奖励在推理模型中类似于多智能体交互的行为模式,而这些模拟交互使模型能够有效推理。
Here we investigate the prevalence of reasoning traces of DeepSeek-R1, as well as QwQ-32B, that mimic simulated social interactions, quantifying how conversational behaviours, socio-emotional roles, and diversity of implicit agent “perspectives” contribute to reasoning performance. We first identify whether conversational behaviours and socio-emotional roles—hallmarks of human dialogue such as questioning, perspective taking, and reconciliation—are present in DeepSeek-R1’s and QwQ-32B’s reasoning traces. Then we test whether conversational behaviour contributes to reasoning performance. Based on the mechanistic interpretability method applied to DeepSeek-R1’s distilled model (DeepSeek-R1-Llama-8B), we find that steering features associated with a discourse marker, such as expressing surprise in conversational contexts, improves reasoning accuracy both directly and indirectly through the facilitation of cognitive strategies.
在这里,我们研究了 DeepSeek-R1 以及模仿模拟社交互动的 QwQ-32B 的推理痕迹的普遍性,量化了对话行为、社会情感角色以及隐式代理“视角”的多样性如何对推理性能做出贡献。我们首先识别 DeepSeek-R1 和 QwQ-32B 的推理痕迹中是否存在对话行为和社会情感角色——这些是人类对话的标志,如提问、视角转换和和解。然后我们测试对话行为是否有助于推理性能。基于应用于 DeepSeek-R1 蒸馏模型(DeepSeek-R1-Llama-8B)的机制可解释性方法,我们发现与话语标记相关的引导特征,例如在对话环境中表达惊讶,能够直接和间接地通过促进认知策略来提高推理准确性。
Next, we analyze the diversity of reasoning “perspectives” or simulated voices within DeepSeek-R1’s and QwQ-32B’s reasoning traces. Literature suggests that LLM reasoning can fail if models do not engage in meaningful disagreement and instead conform to misleading initial claims through pleasant, “sycophantic” conversations that propagate incorrect assumptions and knowledge49, 50, 51. Successful reasoning models may therefore exhibit disagreement driven by diversity in simulated perspectives, expressed through distinct personalities and expertise to avoid the “echo chamber” that leads to wrong answers. Therefore, we analyze reasoning traces using LLM-as-judge to accurately identify distinct voices underlying conversation. We find that DeepSeek-R1 and QwQ-32B display much greater personality and expertise diversity than non-reasoning models within their reasoning traces, presumably to maximize the benefits of multi-agent-like interaction through diversification. We further find that steering a conversational feature in a model’s activation space leads to the activation of a more diverse range of personality- and expertise-related features.
接下来,我们分析 DeepSeek-R1 和 QwQ-32B 推理轨迹中推理“视角”或模拟声音的多样性。文献表明,如果模型不进行有意义的分歧,而是通过令人愉悦的、“阿谀奉承”式的对话,使推理过程符合误导性的初始主张,从而传播错误的假设和知识,那么 LLM 的推理可能会失败 49, 50, 51 。因此,成功的推理模型可能会表现出由模拟视角多样性驱动的分歧,通过不同的个性和专业知识来表达,以避免导致错误答案的“回声室”。为此,我们使用 LLM 作为评判者来分析推理轨迹,以准确识别对话背后不同的声音。我们发现,DeepSeek-R1 和 QwQ-32B 在其推理轨迹中表现出比非推理模型大得多的个性和专业知识多样性,这可能是为了通过多样化来最大化类似多智能体交互的收益。我们进一步发现,引导模型激活空间中的对话特征会导致激活更多与个性和专业知识相关的特征。
Finally, we conduct a controlled reinforcement learning experiment to examine the role of conversational behaviours. We focus on self-taught reinforcement learning that rewards only accuracy and correct formatting (i.e., wrapping the thinking process between <think> and </think>), the common approach for improving modern language models’ reasoning capabilities4. Based on a symbolic arithmetic task (Countdown game)8, 52, as well as a misinformation identification task, we apply reinforcement learning that rewards reasoning traces leading to accurate answers on open-source LLMs. Interestingly, experiments reveal that the base model can spontaneously develop conversational behaviours—such as self-questioning and perspective shifts—when rewarded solely for reasoning accuracy, without any explicit training signal for dialogue structure. Moreover, following methods of prior ablation research8, we observe that initially fine-tuning these models for conversational structure leads to faster accuracy improvements, outperforming both their baseline counterparts and models fine-tuned with “monologue-like” reasoning, particularly during the early stages of training in two distinct model systems (Qwen-2.5-3B and Llama-3.2-3B). These results suggest that conversational scaffolding facilitates the discovery and refinement of reasoning strategies during reinforcement learning.
最后,我们进行了一项受控的强化学习实验,以检验对话行为的作用。我们专注于自我教学的强化学习,该学习方法仅奖励准确性和正确的格式(即在和之间包裹思考过程),这是提高现代语言模型推理能力的一种常见方法 4 。基于一个符号算术任务(倒计时游戏) 8, 52 ,以及一个虚假信息识别任务,我们在开源 LLMs 上应用了强化学习,该方法奖励能够得出准确答案的推理轨迹。有趣的是,实验表明,当仅奖励推理准确性时,基础模型可以自发地发展对话行为——例如自我提问和视角转换——而没有任何关于对话结构的显式训练信号。 此外,遵循先前消融研究的方法 8 ,我们观察到,最初针对对话结构微调这些模型能够更快地提高准确率,其表现优于基线模型以及使用“独白式”推理进行微调的模型,特别是在两个不同模型系统(Qwen-2.5-3B 和 Llama-3.2-3B)训练的早期阶段。这些结果表明,对话式支架在强化学习过程中有助于发现和优化推理策略。
Results 结果
We compile a suite of widely used benchmarks used in prior research and official model cards of reasoning models (BigBench Hard, GPQA, MATH (Hard), MMLU-Pro, MUSR, and IFEval)3, 4, spanning symbolic logic, mathematical problem solving, scientific reasoning, multi-agent inference, and instruction following tasks (see Methods: Data). From this pool, we sample 8,262 problems and generate reasoning traces using DeepSeek-R1-0528 (671B parameters; hereafter DeepSeek-R1) and QwQ-32B. For comparison, we also generate reasoning traces using conventional, instruction-tuned models of varying sizes: DeepSeek-V3-0324 (671B parameters; hereafter DeepSeek-V3), Qwen-2.5-32B-Instruct (hereafter Qwen-2.5-32B-IT; the instruction-tuned model based on Qwen-2.5-32B from which QwQ-32B is derived), Llama-3.3-70B-Instruct (hereafter Llama-3.3-70B-IT), and Llama-3.1-8B-Instruct (hereafter Llama-3.1-8B-IT)53, 54. DeepSeek-V3 is the instruction-tuned model based on DeepSeek-V3-base from which DeepSeek-R1 is derived, and Qwen-2.5-32B-IT is the instruction-tuned model based on Qwen-2.5-32B from which QwQ-32B is derived (see Methods: Data)53, 54.
我们收集了先前研究中广泛使用的推理模型基准测试套件和官方模型卡(BigBench Hard、GPQA、MATH(Hard)、MMLU-Pro、MUSR 和 IFEval) 3, 4 ,涵盖符号逻辑、数学问题解决、科学推理、多智能体推理和指令跟随任务(参见方法:数据)。从这些基准测试中,我们抽取了 8,262 个问题,并使用 DeepSeek-R1-0528(671B 参数;以下简称 DeepSeek-R1)和 QwQ-32B 生成推理轨迹。为了比较,我们还使用不同规模的常规指令微调模型生成了推理轨迹:DeepSeek-V3-0324(671B 参数;以下简称 DeepSeek-V3)、Qwen-2.5-32B-Instruct(以下简称 Qwen-2.5-32B-IT;基于 Qwen-2.5-32B 的指令微调模型,QwQ-32B 即由此衍生)、Llama-3.3-70B-Instruct(以下简称 Llama-3.3-70B-IT)和 Llama-3.1-8B-Instruct(以下简称 Llama-3.1-8B-IT) 53, 54 。DeepSeek-V3 是基于 DeepSeek-V3-base 的指令微调模型,而 DeepSeek-R1 即由此衍生;Qwen-2.5-32B-IT 是基于 Qwen-2.5-32B 的指令微调模型,而 QwQ-32B 即由此衍生(参见方法:数据) 53, 54 。
Next, we estimate behavioural differences between reasoning models (DeepSeek-R1 and QwQ-32B) and the instruction-tuned models. We use linear probability models with problem-level fixed effects, which control for all task-specific characteristics, such as the difficulty of tasks. Specifically, we compare each reasoning model with its corresponding instruction-tuned counterpart (i.e., DeepSeek-R1 vs. DeepSeek-V3; QwQ-32B vs. Qwen-2.5-3B-IT) on the presence of conversational behaviours and socio-emotional roles. We control for log-transformed reasoning trace length (Extended Data Fig. 1) to consider that observed differences are not merely driven by “longer” chains of thought—that is, we demonstrate that reasoning models exhibit more frequent conversational behaviours and socio-emotional roles even when trace lengths are similar (see Methods: Statistical analyses).
接下来,我们估计推理模型(DeepSeek-R1 和 QwQ-32B)与指令微调模型之间的行为差异。我们使用带有问题级固定效应的线性概率模型,该模型控制所有与任务相关的特征,例如任务的难度。具体来说,我们将每个推理模型与其对应的指令微调模型进行比较(即 DeepSeek-R1 与 DeepSeek-V3;QwQ-32B 与 Qwen-2.5-3B-IT),比较它们在对话行为和社会情感角色方面的表现。我们控制了对推理轨迹长度进行对数转换的变量(扩展数据图 1),以考虑观察到的差异并非仅仅由“更长的”思维链驱动——也就是说,我们证明即使轨迹长度相似,推理模型也表现出更频繁的对话行为和社会情感角色(参见方法:统计分析)。
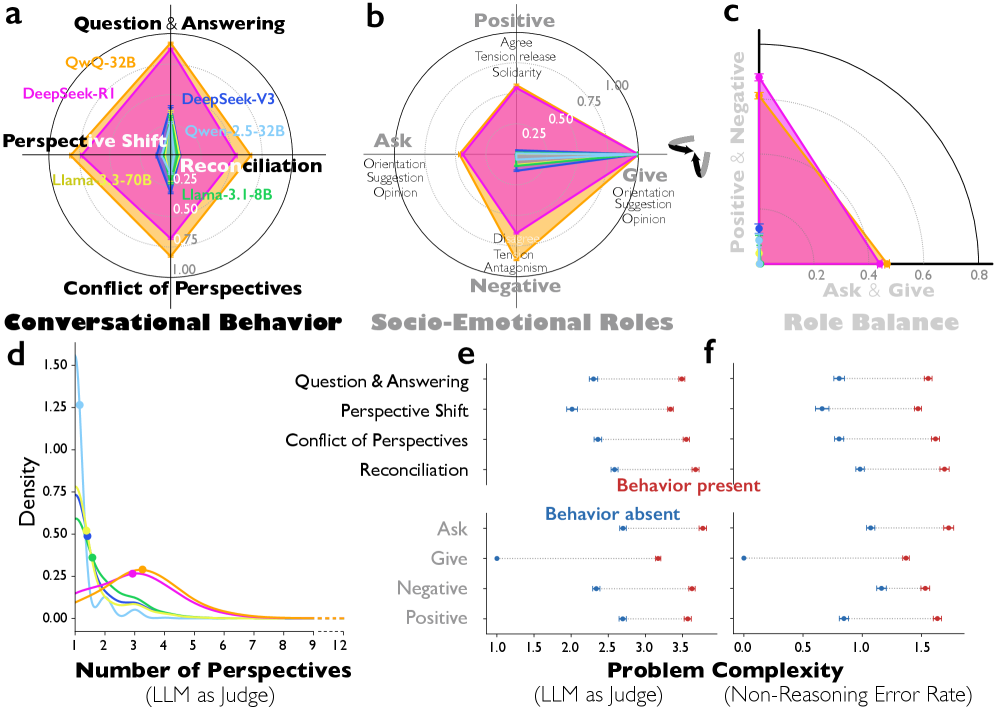
图 1:思维链推理中的对话行为和 Bales 的社会情感角色。a,包含每种对话行为(问题回答、视角转换、视角冲突和和解)的推理轨迹比例。b,推理轨迹中表达的 Bales 的十二个社会情感角色比例,分为四个高级类别:询问与提供信息,以及积极与消极情感角色(所有十二个角色的定义见补充数据图 3)。c,测量每个社会情感角色对的 Jaccard 指数,定义为同时包含两个角色的推理轨迹数量除以包含任一角色的推理轨迹数量(即询问与提供;积极与消极)。d,使用 LLM 作为评判者识别的推理轨迹中不同视角数量的分布。e,DeepSeek-R1 中对话行为和高级社会情感角色的存在导致的问题复杂度差异,使用 LLM 作为评判者,在七点李克特量表上测量(1=极其简单;7=极其困难)。 点表示在行为或角色存在(红色)或不存在(蓝色)的轨迹中的平均复杂性。f,DeepSeek-R1 中由对话行为和社会情感角色的存在导致的问题复杂性差异,通过在相同问题上的指令调优(非推理)模型的错误率来衡量(参见方法:测量)。误差线表示 95%置信区间。
Conversational Behaviours and Socio-Emotional Roles
对话行为与社会情感角色
We begin by investigating whether conversational behaviours and socio-emotional roles constitutive of back-and-forth dialogue are prevalent in reasoning traces. Using an LLM-as-judge, we quantify the occurrence of four conversational behaviours—defined as behaviours signaling the simulation of exchanges among multiple perspectives to explore a given problem—within each reasoning trace: (1) question–answering, in which the trace poses and then resolves questions; (2) perspective shifts, where alternative viewpoints are explored; (3) conflicts of perspectives, in which competing viewpoints are sharply contrasted; and (4) reconciliation, where conflicting viewpoints are integrated and coherently resolved.
我们首先调查在推理痕迹中,构成来回对话的对话行为和社会情感角色是否普遍存在。使用 LLM 作为评判者,我们量化了在每个推理痕迹中四种对话行为的发生情况——这些行为被定义为通过模拟多方视角来探讨给定问题的交互行为:(1) 问答,其中痕迹提出并解决问题;(2) 视角转换,探索不同的观点;(3) 视角冲突,其中竞争性观点被鲜明对比;(4) 调和,其中冲突性观点被整合并连贯解决。
We also examine socio-emotional roles based on Bales’ Interaction Process Analysis (IPA)55. This identifies 12 interaction roles grouped into four categories: (1) asking for orientation, opinion, and suggestion, (2) giving orientation, opinion, and suggestion, (3) negative emotional roles (disagreement, antagonism, tension), and (4) positive emotional roles (agreement, solidarity, tension release), which together characterize interactive group activity. These behaviours are annotated using an LLM-as-judge (Gemini-2.5-Pro) that shows substantial agreement with both a human rater (average ICC(3,1) = .756) and another LLM (GPT-5.2; average ICC(3,1) = .875) (see Methods: Measurements and Supplementary Method: LLM-as-judge prompts (Conversational behaviours and Socioemotional roles)).
我们还基于巴尔斯的互动过程分析(IPA) 55 检查社会情感角色。这识别出 12 种互动角色,分为四类:(1)寻求方向、观点和建议,(2)提供方向、观点和建议,(3)负面情感角色(不同意、对抗、紧张),以及(4)正面情感角色(同意、团结、紧张释放),这些共同描述了互动小组活动。这些行为使用 LLM 作为裁判(Gemini-2.5-Pro)进行标注,该裁判与人类裁判(平均 ICC(3,1) = .756)和另一个 LLM(GPT-5.2;平均 ICC(3,1) = .875)显示出高度一致性(参见方法:测量和补充方法:LLM 作为裁判的提示(对话行为和社会情感角色))。
To illustrate how reasoning traces are annotated, we provide examples in Extended Data Fig. 2 and Supplementary Methods: Annotation Examples. In an organic chemistry problem requiring multi-step reaction analysis to identify the final product’s structure (i.e., multi-step Diels-Alder synthesis), DeepSeek-R1 exhibits perspective shifts and conflict, expressed through socio-emotional roles such as disagreement, giving opinion, and giving orientation (e.g., “But here, it’s cyclohexa-1,3-diene, not benzene.” “Another possibility: the high heat might cause the ketone to lose CO or something, but unlikely.”). In contrast, DeepSeek-V3’s trace on the same problem shows no conflict of perspectives, no perspective shifts, and no disagreement—only giving opinions and orientations in a monologic sequence without self-correction, concluding with “8 is a reasonable estimate”, the wrong answer, as a consequence of incomplete reasoning. In a creative sentence rewriting task, DeepSeek-R1 debates competing stylistic proposals through conflict of perspectives, as well as socio-emotional roles such as disagreement and giving suggestion: “But that adds ‘deep-seated’ which wasn’t in the original. We should avoid adding new ideas.” “Wait, that’s not a word.” “But note: ‘cast’ can be less forceful than ‘flung’. So let’s use ‘hurled’.” DeepSeek-V3, by contrast, shows minimal conflict and no disagreement, producing suggestions without the iterative refinement observed in DeepSeek-R1.
为了说明推理轨迹是如何标注的,我们在扩展数据图 2 和补充方法:标注示例中提供了示例。在一个需要多步反应分析以确定最终产物结构的有机化学问题(即多步 Diels-Alder 合成)中,DeepSeek-R1 表现出视角转换和冲突,通过诸如不同意、给出观点和给出方向等社会情感角色来表达(例如,“但这里,它是环己-1,3-二烯,不是苯。” “另一种可能性:高温可能导致酮失去 CO 或什么,但不太可能。”)。相比之下,DeepSeek-V3 在同一问题上的轨迹没有视角冲突,没有视角转换,也没有不同意——仅以单话语序给出观点和方向,没有自我纠正,最终得出“8 是一个合理的估计”,这是一个错误的答案,这是由于推理不完整所致。在一个创造性句子改写任务中,DeepSeek-R1 通过视角冲突以及诸如不同意和给出建议等社会情感角色来辩论竞争性的风格提案:“但那增加了‘根深蒂固’,而原文中并没有。” 我们应该避免添加新想法。” “等等,这不是一个词。” “但是请注意:'cast'可能比'flung'更不强烈。所以让我们用'hurled'。”相比之下,DeepSeek-V3 显示出极少的冲突,没有分歧,产生建议而没有 DeepSeek-R1 中观察到的迭代改进。
As shown in Fig. 1a, we quantify the occurrence of four conversational behaviours within each reasoning trace, and report the proportion of traces exhibiting more than one such behaviour. DeepSeek-R1 and QwQ-32B exhibit conversational behaviours far more frequently than instruction-tuned models. DeepSeek-R1 shows significantly more question–answering ( = 0.345, 95% CI = [0.328, 0.361], t(8261) = 41.64, p < 110-323), perspective shifts ( = 0.213, 95% CI = [0.197, 0.230], t(8261) = 25.55, p < 110-137), and reconciliation ( = 0.191, 95% CI = [0.176, 0.207], t(8261) = 24.31, p < 110-125) compared to DeepSeek-V3. QwQ-32B displays a similar pattern relative to Qwen-2.5-32B-IT, with greater question–answering ( = 0.459, 95% CI = [0.444, 0.475], t(8261) = 57.57, p < 110-323), perspective shifts ( = 0.378, 95% CI = [0.362, 0.394], t(8261) = 46.92, p < 110-323), conflicts of perspectives ( = 0.293, 95% CI = [0.277, 0.308], t(8261) = 37.08, p < 110-277), and reconciliation ( = 0.344, 95% CI = [0.328, 0.360], t(8261) = 42.59, p < 110-323). Notably, all instruction-tuned models show consistently low prevalence of conversational behaviours regardless of parameter count (8B, 32B, 70B, 671B).
如图 1a 所示,我们量化了每个推理轨迹中四种对话行为的发生情况,并报告了表现出一种以上这些行为的轨迹比例。DeepSeek-R1 和 QwQ-32B 表现出对话行为的频率远高于指令微调模型。与 DeepSeek-V3 相比,DeepSeek-R1 表现出显著更多的问答行为( = 0.345, 95% CI = [0.328, 0.361], t(8261) = 41.64, p < 1 10 -323 )、视角转换( = 0.213, 95% CI = [0.197, 0.230], t(8261) = 25.55, p < 1 10 -137 )和和解行为( = 0.191, 95% CI = [0.176, 0.207], t(8261) = 24.31, p < 1 10 -125 )。QwQ-32B 相对于 Qwen-2.5-32B-IT 表现出类似的模式,具有更高的问答行为( = 0.459, 95% CI = [0.444, 0.475], t(8261) = 57.57, p < 1 10 -323 )、视角转换( = 0.378, 95% CI = [0.362, 0.394], t(8261) = 46.92, p < 1 10 -323 )、视角冲突( = 0.293, 95% CI = [0.277, 0.308], t(8261) = 37.08, p < 1 10 -277 )和和解行为( = 0.344, 95% CI = [0.328, 0.360], t(8261) = 42.59, p < 1 10 -323 )。 值得注意的是,所有经过指令微调的模型,无论参数数量(8B、32B、70B、671B)如何,都表现出对话行为的低发生率。
As shown in Fig. 1b, both DeepSeek-R1 and QwQ-32B exhibit more reciprocal socio-emotional roles compared to their instruction-tuned counterparts: they both ask for and give orientations, opinions, and suggestions, while also displaying both negative and positive roles. DeepSeek-R1 asks more frequently than DeepSeek-V3 ( = 0.189, 95% CI = [0.176, 0.203], t(8261) = 27.47, p < 110-158), engages more in negative roles ( = 0.162, 95% CI = [0.147, 0.176], t(8261) = 21.87, p < 110-10), and displays more positive roles ( = 0.278, 95% CI = [0.263, 0.293], t(8261) = 35.38, p < 110-254). QwQ-32B shows a similar pattern relative to Qwen-2.5-32B-IT, with increased asking ( = 0.200, 95% CI = [0.186, 0.215], t(8261) = 27.21, p < 110-155), negative roles ( = 0.450, 95% CI = [0.436, 0.463], t(8261) = 64.77, p < 110-323), and positive roles ( = 0.312, 95% CI = [0.296, 0.327], t(8261) = 39.17, p < 110-307). In contrast, instruction-tuned models predominantly give orientations, opinions, and suggestions without reciprocal asking behaviours or emotional engagement, producing one-sided monologues rather than simulated dialogue.
如图 1b 所示,与指令微调的模型相比,DeepSeek-R1 和 QwQ-32B 表现出更多的互惠社会情感角色:它们都请求和提供指导、观点和建议,同时也展现出负面和正面的角色。DeepSeek-R1 的请求频率高于 DeepSeek-V3 ( = 0.189, 95% CI = [0.176, 0.203], t(8261) = 27.47, p < 1 10 -158 ),更多地参与负面角色 ( = 0.162, 95% CI = [0.147, 0.176], t(8261) = 21.87, p < 1 10 -10 ),并展现出更多的正面角色 ( = 0.278, 95% CI = [0.263, 0.293], t(8261) = 35.38, p < 1 10 -254 )。QwQ-32B 相对于 Qwen-2.5-32B-IT 表现出类似的模式,请求增加 ( = 0.200, 95% CI = [0.186, 0.215], t(8261) = 27.21, p < 1 10 -155 ),负面角色增加 ( = 0.450, 95% CI = [0.436, 0.463], t(8261) = 64.77, p < 1 10 -323 ),正面角色增加 ( = 0.312, 95% CI = [0.296, 0.327], t(8261) = 39.17, p < 1 10 -307 )。相比之下,指令微调的模型主要提供指导、观点和建议,而没有互惠的请求行为或情感参与,产生的是单向独白而非模拟对话。
We quantify reciprocal role balance using the Jaccard index, which captures whether both sides of a role pair—asking versus giving for task-oriented roles, and positive versus negative for emotional roles—co-occur within the same reasoning trace. As shown in Fig. 1c, DeepSeek-R1 exhibits significantly higher Jaccard indices for both ask & give ( = 0.222, 95% CI = [0.208, 0.237], t(8261) = 30.21, p < 110-189) and positive & negative roles ( = 0.189, 95% CI = [0.176, 0.203], t(8261) = 27.47, p < 110-158) compared to DeepSeek-V3, indicating that the model coordinates roles reciprocally rather than deploying them in isolation. QwQ-32B shows a similar pattern relative to Qwen-2.5-32B-IT (ask & give: = 0.284 [0.269, 0.299], t(8261) = 37.36, p < 110-281; positive & negative: = 0.200 [0.186, 0.215], t(8261) = 27.24, p < 110-155) (see Supplementary Table 1).
我们使用 Jaccard 指数量化互惠角色平衡,该指数能够捕捉任务导向角色中请求与提供、情感角色中积极与消极是否在同一个推理轨迹中共同出现。如图 1c 所示,DeepSeek-R1 在请求与提供( = 0.222,95% CI = [0.208, 0.237],t(8261) = 30.21,p < 1 10 -189 )和积极与消极角色( = 0.189,95% CI = [0.176, 0.203],t(8261) = 27.47,p < 1 10 -158 )上的 Jaccard 指数均显著高于 DeepSeek-V3,表明该模型是互惠地协调角色,而非孤立地部署角色。QwQ-32B 相对于 Qwen-2.5-32B-IT 表现出类似模式(请求与提供: = 0.284 [0.269, 0.299],t(8261) = 37.36,p < 1 10 -281 ;积极与消极: = 0.200 [0.186, 0.215],t(8261) = 27.24,p < 1 10 -155 )(参见补充表 1)。
We further examine whether conversational behaviours and socio-emotional roles become more pronounced when DeepSeek-R1 faces more difficult tasks. Problem complexity is assessed both by an external LLM-as-judge (Fig. 1d: Gemini-2.5-Pro) or by error rates across conventional instruction-tuned models (Fig. 1e: DeepSeek-V3, Qwen-2.5-32B, Llama-3.3-70B-IT, Llama-3.1-8B-IT). As illustrated in Fig. 1d and 1e, these behaviours appear more frequently when DeepSeek-R1 tackles more complex problems, except for giving orientations and opinions. Consistent patterns across both measures suggest that conversational reasoning is preferentially activated in response to greater problem difficulty. For instance, tasks with the highest complexity scores—such as GPQA (graduate-level science) and challenging math problems—exhibit strong conversational patterns, whereas simple procedural tasks like boolean expressions and basic logical deduction show minimal dialogic behaviour (see Supplementary Table 2).
我们进一步考察当 DeepSeek-R1 面对更困难的任务时,对话行为和社会情感角色是否会更加明显。问题的复杂性通过外部 LLM 作为评判者(图 1d:Gemini-2.5-Pro)或通过传统指令调优模型的错误率(图 1e:DeepSeek-V3、Qwen-2.5-32B、Llama-3.3-70B-IT、Llama-3.1-8B-IT)进行评估。如图 1d 和 1e 所示,当 DeepSeek-R1 处理更复杂的问题时,这些行为出现的频率更高,除了给出方向和观点的情况。两种衡量标准的一致模式表明,对话推理在问题难度增加时更倾向于被激活。例如,具有最高复杂度评分的任务——如 GPQA(研究生级科学)和具有挑战性的数学问题——表现出强烈的对话模式,而像布尔表达式和基本逻辑推理这样的简单程序性任务则显示出极少的对话行为(参见补充表格 2)。
To decompose the accuracy advantage of reasoning models (DeepSeek-R1 and QwQ-32B) using the behavioural mechanisms above, we estimate a structural equation model with four conversational behaviours, four socio-emotional roles, and four cognitive behaviour mediators, using task accuracy as the outcome. Results suggest that conversational behaviours and socio-emotional roles mediate reasoning models’ accuracy advantage, both directly and indirectly through facilitating useful cognitive strategies, such as verification, backtracking, subgoal setting, and backward tracking (See Extended Data Fig. 4; Supplementary Methods: behavioural Pathways Linking Reasoning Models to Accuracy Advantages).
利用上述行为机制分解推理模型(DeepSeek-R1 和 QwQ-32B)的准确率优势,我们采用任务准确率作为结果,构建了一个包含四种对话行为、四种社会情感角色和四种认知行为中介的结构方程模型。结果表明,对话行为和社会情感角色通过促进验证、回溯、子目标设定和反向追踪等有用认知策略,直接和间接地介导了推理模型的准确率优势(参见扩展数据图 4;补充方法:连接推理模型与准确率优势的行为路径)。
Conversational Feature Steering Improves Reasoning Accuracy
对话特征引导提升推理准确率
Having observed that conversational behaviours are prevalent in reasoning traces using LLM-as-judge, we next question whether steering behaviours associated with conversations contribute to reasoning performance. We employ mechanistic interpretability methods to identify and manipulate features in the model’s activation space related to conversational behaviours, and examine how steering these features affects the model’s reasoning capabilities. We use sparse autoencoders (SAEs), which decompose neural network activations into a large set of linear, interpretable features56, 57, 58. Specifically, we use an SAE trained on Layer 15’s residual stream activations of DeepSeek-R1-Llama-8B (15-llamascope-slimpj-res-32k), a distilled model derived from DeepSeek-R1 frequently used to conduct interpretability research on LLM reasoning38, 39, 40, 41. SAEs trained on middle layers, including Layer 15, are known to capture key behavioural and semantic features in models6, 58. The SAE was trained on the SlimPajama dataset, a general-purpose, large-scale corpus used to train LLMs from scratch, containing both conversational and non-conversational texts (see Supplementary Table 3 for full SAE hyperparameters)59.
观察到使用 LLM 作为裁判的推理轨迹中普遍存在对话行为后,我们进一步探究与对话相关的引导行为是否会影响推理性能。我们采用机制可解释性方法来识别和操控模型激活空间中与对话行为相关的特征,并检验引导这些特征如何影响模型的推理能力。我们使用稀疏自动编码器(SAEs),将神经网络激活分解为大量线性、可解释的特征 56, 57, 58 。具体而言,我们使用一个在 DeepSeek-R1-Llama-8B(15-llamascope-slimpj-res-32k)第 15 层残差流激活上训练的 SAE,DeepSeek-R1-Llama-8B 是一个从 DeepSeek-R1 衍生出的蒸馏模型,常用于对 LLM 推理进行可解释性研究 38, 39, 40, 41 。已知在中间层(包括第 15 层)上训练的 SAEs 能够捕捉模型中的关键行为和语义特征 6, 58 。 SAE 是在 SlimPajama 数据集上训练的,这是一个通用的、大规模语料库,用于从头开始训练 LLMs,包含对话和非对话文本(有关完整的 SAE 超参数,请参见补充表格 3) 59 。
To identify SAE features associated with conversational contexts, we follow a conventional interpretability pipeline60, 61, 56. We first run the SAE on a large-scale corpus (SlimPajama-3B), sampling around 50 contexts where each of the 32,768 features activates to “explain” the role of each feature. These sampled contexts are then used to characterize the feature as in prior literature60, 61, 56. Using LLM-as-judge classification of these contexts (Gemini-2.5-flash-lite), we compute the conversation ratio for each feature—the proportion of feature activations that occur in interpersonal, conversational settings (see Fig. 2a for the distribution across all features). For example, if the conversation ratio is 50%, then in 50% of the instances when the feature is activated, it is used for conversation. We focus on features with conversation ratios above 50% that tend to activate near sentence onsets (i.e., within the first four tokens). From the candidates, we curate feature 30939, summarized as “a discourse marker for surprise, realization, or acknowledgment” by Gemini-2.5-Pro, which activates on tokens like “Oh!” in contexts involving turn-taking and social exchange (see Fig. 2a). This feature exhibits a conversation ratio of 65.7%—placing it in the 99th percentile among all features—while maintaining high sparsity (0.016% of tokens), indicating that it captures a specific conversational phenomenon rather than general linguistic patterns. We select this feature because prior literature suggests that expressions of surprise signal a shift in contrasting perspectives characteristic of social coordination and affiliation62, 63.
为了识别与对话情境相关的 SAE 特征,我们遵循传统的可解释性流程 60, 61, 56 。我们首先在大型语料库(SlimPajama-3B)上运行 SAE,采样约 50 个情境,其中每个 32,768 个特征被激活以“解释”每个特征的作用。然后使用这些采样的情境来表征特征,如先前的文献 60, 61, 56 所述。我们使用 LLM 作为裁判对这些情境进行分类(Gemini-2.5-flash-lite),计算每个特征的对话比率——即特征激活发生在人际、对话情境中的比例(所有特征的分布情况见图 2a)。例如,如果对话比率为 50%,那么在特征被激活的 50%的实例中,它用于对话。我们关注对话比率超过 50%且倾向于在句子开头附近激活(即在前四个 token 内)的特征。从候选特征中,我们筛选出特征 30939,Gemini-2.5-Pro 将其总结为“用于惊讶、意识到或确认的语篇标记”,该特征在涉及轮流发言和社会交换的情境中(如“哦!”这样的 token 上)被激活(见图 2a)。 这一特征展现出 65.7%的对话比例,在所有特征中排名前 1%,同时保持高稀疏度(0.016%的 token),表明它捕捉的是特定的对话现象而非普遍的语言模式。我们选择这一特征是因为已有文献表明,惊讶的表达标志着社会协调和归属感所特有的对比视角的转变 62, 63 。
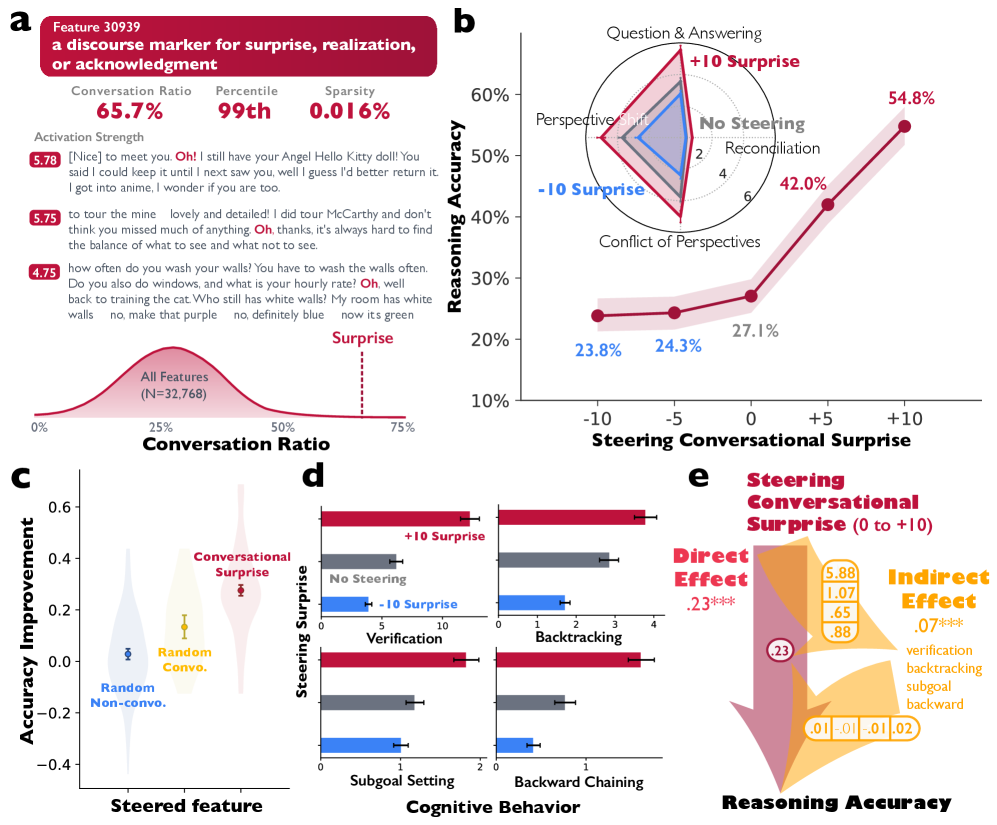
图 2:引导对话特征可提升推理能力。a,DeepSeek-R1-Llama-8B 中稀疏自编码器特征 30939 的示意图,总结为对话场景中用于表达惊讶、顿悟或确认的语篇标记。对话比例表示该特征被激活的所有场景中对话场景的比例。百分位数表示该特征对话比例在所有特征中的排名( )。稀疏性指该特征在整个语料库中激活的 token 比例。激活强度显示在激活度最高的示例中的激活幅度。示例展示了该特征在对话轮流语境中的激活情况。b,使用激活添加方法进行的引导实验结果。将特征 30939 向量以 10 的强度添加,使复杂计数任务的准确率翻倍。插图显示了引导该特征引起的对话行为的因果变化。 c, 小提琴图展示了从转向特征 30939 中获得的准确率提升,与随机选择的一个对话式 SAE 特征和随机选择的一个非对话式 SAE 特征进行比较。d, 认知行为——包括验证、回溯、子目标设定和反向链接——与转向特征 30939 的激活因果关系相关。e, 结构方程模型结果展示了从 0 转向到 特征 30939,对推理准确率有直接效应,并通过认知行为(验证、子目标设定和反向链接)存在显著的间接效应。粗体系数表示统计显著性( )。*** , ** ,* 。
We examine whether steering this feature causally induces conversational behaviours and improves reasoning accuracy using the activation addition method, which adds scaled feature vectors to model activations during generation. Specifically, we use the Countdown game, a benchmark commonly used to evaluate LLM multi-step reasoning capabilities8, 52. In the Countdown task, the model must combine a given set of numbers using basic arithmetic operations (+, , , ) and parentheses to reach a target value—for example, given inputs 25, 30, 3, 4 and target 32, a valid solution is (30 25 + 3) 4 = 328, 52. We use the sample of 1,024 Countdown problems. We prompt the model to generate chain-of-thought reasoning, and at each token generation step, we add the feature 30939 vector (scaled by the steering strength) to layer 15 activations.
我们使用激活加成方法来检验是否通过因果引导这一特征能够诱导对话行为并提高推理准确性,该方法在生成过程中将缩放的特征向量添加到模型激活中。具体来说,我们使用倒计时游戏,这是一个常用的基准测试,用于评估 LLM 的多步推理能力 8, 52 。在倒计时任务中,模型必须使用基本的算术运算(+、 、 、 )和括号来组合给定的数字集合,以达到目标值——例如,给定输入 25、30、3、4 和目标值 32,一个有效的解决方案是(30 25 + 3) 4 = 32 8, 52 。我们使用了 1,024 个倒计时问题的样本。我们提示模型生成思维链推理,并在每个标记生成步骤中,将特征向量 30939(按引导强度缩放)添加到第 15 层的激活中。
As shown in Fig. 2b, steering the conversational surprise feature with positive direction (+10) doubles accuracy from 27.1% to 54.8% in the Countdown task, while steering in the negative direction (10) reduces accuracy to 23.8%. The radar plot inset reveals that positive steering (from 0 to +10) simultaneously increases all four conversational behaviours—more question-answering ( = 2.199, 95% CI = [1.648, 2.750], t(1023) = 7.83, p < 110-14), perspective shifts ( = 1.160, 95% CI = [0.665, 1.655], t(1023) = 4.60, p < 110-5), conflict of perspectives ( = 1.062, 95% CI = [0.376, 1.749], t(1023) = 3.04, p = 0.002), and reconciliation ( = 0.423, 95% CI = [0.349, 0.497], t(1023) = 11.21, p < 110-27), controlling for problem fixed-effects and log-transformed reasoning trace length. Negative steering from 0 to -10 suppresses them, reducing question-answering ( = 0.831, 95% CI = [1.154, 0.508], t(1023) = 5.05, p < 110-6), perspective shifts ( = 0.966, 95% CI = [1.262, 0.670], t(1023) = 6.41, p < 110-9), conflict of perspectives ( = 1.347, 95% CI = [1.748, 0.946], t(1023) = 6.60, p < 110-10), and reconciliation ( = 0.052, 95% CI = [0.103, 0.001], t(1023) = 1.99, p = 0.046). For instance, as shown in Extended Data Table 1, positive steering (+10) induces reasoning traces where the model actively challenges prior approaches (“Wait, let me see… Another idea…”), showing perspective shift and conflicts of perspectives, whereas negative steering (10) produces relatively flat, declarative reasoning without internal debate.
如图 2b 所示,将对话意外特征正向引导(+10)使计数器任务中的准确率从 27.1%提升至 54.8%,而负向引导( 10)则将准确率降至 23.8%。雷达图插图显示,正向引导(从 0 到+10)同时提升了所有四种对话行为——更多问答( = 2.199, 95% CI = [1.648, 2.750], t(1023) = 7.83, p < 1 10 -14 )、视角转换( = 1.160, 95% CI = [0.665, 1.655], t(1023) = 4.60, p < 1 10 -5 )、视角冲突( = 1.062, 95% CI = [0.376, 1.749], t(1023) = 3.04, p = 0.002)和和解( = 0.423, 95% CI = [0.349, 0.497], t(1023) = 11.21, p < 1 10 -27 ),同时控制问题固定效应和对数转换的推理轨迹长度。从 0 到-10 的负向引导则抑制了这些行为,降低了问答( = 0.831, 95% CI = [ 1.154, 0.508], t(1023) = 5.05, p < 1 10 -6 )、视角转换( = 0.966, 95% CI = [ 1.262, 0.670], t(1023) = 6.41, p < 1 10 -9 )、视角冲突( = 1.347, 95% CI = [ 1.748, 0.946], t(1023) = 6.60, p < 1 10 -10 ), 和和解 ( = 0.052, 95% CI = [ 0.103, 0.001], t(1023) = 1.99, p = 0.046)。例如,正如扩展数据表 1 所示,正向引导(+10)会引发推理痕迹,其中模型会主动挑战先前方法(“等等,让我看看……还有另一个想法……”),显示出视角转换和视角冲突,而负向引导( 10)则产生相对平稳、陈述性的推理,没有内部辩论。
To examine whether this effect is specific to conversational features rather than a general property of SAE steering, we compare accuracy improvements across three conditions: (1) steering the conversational surprise feature (Feature 30939), steering a randomly selected conversational feature, and steering a randomly selected non-conversational feature (Fig. 2c). A random conversational feature is defined as any feature whose conversation ratio is above the average and tends to activate near sentence onset (i.e., first four tokens), which are more closely associated with conversational styles than other features. All steering strengths are defined as the maximum activation strength across sampled instances of feature activations (SlimPajama-3B), multiplied by 2. The conversational surprise feature produces substantially larger accuracy gains than both random conversational features and non-conversational features (see Fig. 2c). Steering any random conversational feature also significantly improves reasoning by 4.17% more than any random non-reasoning feature ( = 0.042, 95% CI = [0.016, 0.068], t(1023)=3.14, p=0.002). This specificity suggests that conversational dynamics, rather than arbitrary perturbations to model activations, drive the observed improvements.
为了检验这种效应是否特定于对话特征,而非 SAE 转向的一般属性,我们比较了三种条件下的准确率提升:(1) 转向对话意外特征(特征 30939)、转向随机选择的一个对话特征,以及转向随机选择的一个非对话特征(图 2c)。随机对话特征被定义为任何对话比例高于平均值且倾向于在句子起始附近(即前四个 token)激活的特征,这些特征与其他特征相比,更紧密地与对话风格相关。所有转向强度定义为特征激活的样本实例中的最大激活强度(SlimPajama-3B)乘以 2。对话意外特征产生的准确率提升远大于随机对话特征和非对话特征(见图 2c)。转向任何随机对话特征也比转向任何随机非推理特征显著提高了 4.17%的推理能力( = 0.042,95% CI = [0.016, 0.068],t(1023)=3.14,p=0.002)。 这种特殊性表明,是会话动态而非对模型激活的任意扰动,推动了观察到的改进。
We further investigate the mechanism by which conversational steering enhances reasoning. Prior work has identified cognitive behaviours—verification, backtracking, subgoal setting, and backward chaining —as key contributors to reasoning accuracy in language models8. As shown in Fig. 2d, steering feature 30939 toward positive values (0 to +10) systematically increases all four cognitive behaviours: verification (Difference = 5.815, 95% CI=[4.922, 6.709], t(1023)=12.77, p < 110-34), backtracking (Difference = 0.881, 95% CI=[0.515, 1.248], t(1023)=4.72, p < 110-5), subgoal setting (Difference = 0.621, 95% CI=[0.440, 0.803], t(1023)=6.72, p < 110-10), and backward chaining (Difference = 0.809, 95% CI=[0.633, 0.985], t(1023)=9.02, p < 110-18) rise monotonically with steering strength. Steering toward negative values (0 to -10) suppresses these behaviours (verification: Difference = -2.302, 95% CI=[-2.892, -1.711], t(1023)=7.65, p < 110-13; backtracking: Difference = -1.138, 95% CI=[-1.410, -0.867], t(1023)=8.24, p < 110-15; subgoal setting: Difference = -0.171, 95% CI=[-0.305, -0.036], t(1023)=2.48, p = 0.013; backward chaining: Difference = -0.353, 95% CI=[-0.487, -0.219], t(1023)=5.18, p < 110-6) based on paired t-tests. This suggests that conversational features may improve reasoning, in part, by facilitating the deployment of effective cognitive strategies.
我们进一步研究了对话引导增强推理的机制。先前研究已经确定了认知行为——验证、回溯、子目标设置和反向链接——作为语言模型推理准确性的关键贡献因素 8 。如图 2d 所示,将引导特征 30939 推向正值(0 至+10)系统地增加了所有四种认知行为:验证(差异=5.815,95%置信区间=[4.922, 6.709],t(1023)=12.77,p < 1 10 -34 ),回溯(差异=0.881,95%置信区间=[0.515, 1.248],t(1023)=4.72,p < 1 10 -5 ),子目标设置(差异=0.621,95%置信区间=[0.440, 0.803],t(1023)=6.72,p < 1 10 -10 ),以及反向链接(差异=0.809,95%置信区间=[0.633, 0.985],t(1023)=9.02,p < 1 10 -18 ),这些行为随着引导强度的增加而单调上升。将引导推向负值(0 至-10)则抑制了这些行为(验证:差异=-2.302,95%置信区间=[-2.892, -1.711],t(1023)=7.65,p < 1 10 -13 ;回溯:差异=-1.138,95%置信区间=[-1.410, -0.867],t(1023)=8.24,p < 1 10 -15 ;子目标设置:差异=-0.171,95%置信区间=[-0.305, -0.036],t(1023)=2.48,p = 0.)013; 反向链:差异 = -0.353,95%置信区间=[-0.487, -0.219],t(1023)=5.18,p < 1 10 -6 ) 基于配对 t 检验。这表明对话特征可能通过促进有效认知策略的运用,部分提升了推理能力。
To disentangle direct and indirect effects, we fit a structural equation model to examine the pathways from steering conversational surprise (feature 30939) to accuracy (Fig. 2e). The model indicates that increasing steering feature 30939 from 0 to +10 yields both a significant direct effect on reasoning accuracy ( = .228, 95% CI = [.183, .273], z=9.98, p < 110-22, N=2048) and a significant indirect effect mediated by cognitive behaviours ( = .066, 95% CI = [.046, .086], z=6.38, p < 110-10, N=2048). Collectively, these findings suggest that conversational features enhance reasoning by directly enabling more effective exploration of the solution space, but also by scaffolding the cognitive strategies that support systematic problem solving.
为区分直接和间接效应,我们拟合了一个结构方程模型来检验从引导对话意外(特征 30939)到准确性的路径(图 2e)。模型显示,将引导特征 30939 从 0 增加到+10,既对推理准确性产生显著直接效应( = .228,95%置信区间 = [.183, .273],z=9.98,p < 1 10 -22 ,N=2048),也通过认知行为产生显著间接效应( = .066,95%置信区间 = [.046, .086],z=6.38,p < 1 10 -10 ,N=2048)。综合来看,这些发现表明对话特征通过直接促进对解空间的更有效探索,以及通过构建支持系统化问题解决的认知策略,增强了推理能力。
Diversity of Implicit Perspectives
隐性视角的多样性
Beyond task accuracy, we examine whether DeepSeek-R1 increases the diversity of perspectives expressed within a reasoning trace. In human societies, conversations and socio-emotional role-taking expand the range of viewpoints and domain knowledge brought into problem solving. Differences of perspective give rise to conflict, debate, and resolution. We evaluate whether similar perspective diversity emerges in DeepSeek-R1 by analyzing personality and expertise variation among the distinct reasoning “perspectives” participating in each reasoning trace.
除了任务准确性之外,我们还考察 DeepSeek-R1 是否增加了推理轨迹中表达的视角多样性。在人类社会中,对话和社会情感角色扮演扩展了问题解决中引入的观点范围和领域知识。视角的差异会导致冲突、辩论和解决。我们通过分析每个推理轨迹中参与的不同推理“视角”之间的性格和专业知识差异,评估 DeepSeek-R1 是否出现了类似的视角多样性。
We first use an external LLM-as-judge (Gemini-2.5-Pro), prompting it to identify the diversity of implicit conversational perspectives within reasoning traces of DeepSeek-R1, QwQ-32B, and other instruction-tuned models. Specifically, the model infers the number of perspectives underlying each reasoning trace, the personality traits and domain expertise associated with each perspective, and a segmentation of the full reasoning trace by perspective (see Methods: Implicit Perspectives). Given a complete reasoning trace, the LLM-as-judge first infers the number of distinct perspectives present, which is shown in Fig. 1d. It then characterizes each perspective’s personality traits using the BFI-10 (10-Item Big Five Personality Scale) questionnaire64, along with a short free-form description of the perspective’s domain expertise. Finally, the LLM-as-judge attributes each token in the reasoning trace to a specific perspective (i.e., who said this word). Personality diversity is estimated using the standard deviation of inferred personality traits for each Big-5 dimension, while domain expertise diversity is estimated using the mean cosine distance between embedding of each domain expertise description and the average embedding. See Methods: Implicit Perspectives and Supplementary Method: LLM-as-judge prompts (“Persona identification” and “Persona segmentation”) for details.
我们首先使用一个外部 LLM 作为裁判(Gemini-2.5-Pro),提示它识别 DeepSeek-R1、QwQ-32B 和其他指令微调模型推理轨迹中隐含对话视角的多样性。具体来说,该模型推断每个推理轨迹背后所隐含的视角数量、每个视角相关联的性格特征和领域专业知识,以及按视角对完整推理轨迹进行分割(参见方法:隐含视角)。对于一个完整的推理轨迹,LLM 作为裁判首先推断其中存在的不同视角数量,如图 1d 所示。然后,它使用 BFI-10(10 项五大性格量表)问卷 64 来描述每个视角的性格特征,并附上对该视角领域专业知识的简短自由描述。最后,LLM 作为裁判将推理轨迹中的每个词元分配给一个特定的视角(即:谁说了这句话)。 人格多样性通过每个 Big-5 维度的推断人格特质的方差来估计,而领域专业知识多样性则通过每个领域专业知识描述的嵌入与平均嵌入之间的平均余弦距离来估计。详情请参见方法:隐式视角和补充方法:LLM 作为评判者提示(“人格识别”和“人格分割”)。
For instance, in a chemistry reasoning trace requiring multi-step synthesis analysis, the LLM-as-judge identifies five perspectives, including a critical verifier (low agreeableness, high conscientiousness) who skeptically re-evaluates assumptions, and an expert in making associations (high openness) who recalls analogous reactions. In a creative writing trace where the model rewrites the sentence “I flung my hatred into the burning fire,” seven perspectives emerge, including a creative ideator (highest Openness and Extraversion) who generates stylistic alternatives and a semantic fidelity checker (low agreeableness, high neuroticism) who prevents scope creep—“But that adds ‘deep-seated’ which wasn’t in the original”. DeepSeek-V3’s trace reflects only a single generalist perspective combining all functions without differentiation (see Supplementary Methods: Annotation Examples).
例如,在一个需要多步合成分析的化学推理追踪中,作为评判者的 LLM 识别出五个视角,包括一个批判性验证者(低宜人性、高责任心)对假设进行怀疑重估,以及一个擅长建立关联的专家(高开放性)回忆起类似反应。在一个创造性写作追踪中,当模型重写句子“我将我的仇恨抛入燃烧的火焰”时,会出现七个视角,包括一个创意构思者(开放性和外向性最高)生成风格化替代方案,以及一个语义保真度检查者(低宜人性、高神经质)防止范围蔓延——“但这增加了‘根深蒂固’,而原文中并没有”。DeepSeek-V3 的追踪仅反映了一个结合所有功能而无差异的单一通用视角(参见补充方法:标注示例)。
Using the Intelligence Squared Debates Corpus—a dataset of human argumentative conversations (N=1,196 conversations) among two to eight participants—we first validate the accuracy of the LLM-as-judge in identifying distinct voices within a conversation. As shown in Extended Data Fig. 5, we find that the LLM-as-judge can accurately predict the number of distinct individuals underlying each conversation, even when speaker labels are hidden and the dialogue is concatenated into a single block of text (Spearman’s = 0.86, 95% CI = [0.84, 0.87], z = 44.7, p < 1×10-323). We also find that the LLM-as-judge can accurately predict the number of distinct turns (Spearman’s = 0.89, 95% CI = [0.88, 0.90], z = 49.2, p < 1×10-323) and correctly attribute each token to a speaker. When there are two speakers, the accuracy is 82%; for three speakers, 76%; and for four speakers, 69%. Accuracy weighted by the predicted number of implicit perspectives underlying LLM reasoning trace is 73%. Because the Intelligence Squared Debates Corpus includes biographical information about debate participants, we further verify that expertise diversity inferred by LLM-as-judge and embeddings predicts the actual diversity among participants’ ground-truth biographies (Spearman’s = 0.55, 95% CI = [0.51, 0.59], z = 21.4, p < 1×10-97). Together, these results suggest that LLM-as-judge can capture meaningful diversity patterns in conversational agents that correspond to observed diversity in real human conversations (see Methods: Implicit Perspectives - Validation for details).
使用 Intelligence Squared 辩论语料库——一个包含人类辩论对话的数据集(N=1,196 次对话),其中参与人数为两到八人——我们首先验证了作为裁判的 LLM 在识别对话中不同声音方面的准确性。如图 5 所示,我们发现作为裁判的 LLM 能够准确预测每个对话背后不同个体的数量,即使说话人标签被隐藏且对话被连接成一个文本块(Spearman’s = 0.86, 95% CI = [0.84, 0.87], z = 44.7, p < 1×10 -323 )。我们还发现作为裁判的 LLM 能够准确预测不同轮次的数量(Spearman’s = 0.89, 95% CI = [0.88, 0.90], z = 49.2, p < 1×10 -323 ),并能正确地将每个词元分配给说话人。 当存在两位说话者时,准确率为 82%;三位说话者时,76%;四位说话者时,69%。基于 LLM 推理轨迹中预测的潜在隐含视角数量进行加权计算的准确率为 73%。由于 Intelligence Squared 辩论语料库包含了辩论参与者的传记信息,我们进一步验证了 LLM 作为评判者推断的专业知识多样性和嵌入向量预测了参与者实际传记中的真实多样性(Spearman’s = 0.55, 95% CI = [0.51, 0.59], z = 21.4, p < 1×10 -97 )。综合这些结果表明,LLM 作为评判者能够捕捉到对话代理中的有意义多样性模式,这些模式与真实人类对话中观察到的多样性相对应(参见方法:隐含视角 - 验证部分以获取详细信息)。
As shown in Fig. 3a, we find that DeepSeek-R1 and QwQ-32B produce significantly higher personality diversity, controlling for the number of perspectives. DeepSeek-R1 shows particularly higher diversity along extraversion ( = 0.103, 95% CI = [0.075, 0.131], t = 7.16, p < 1×10-13), agreeableness ( = 0.297, 95% CI = [0.271, 0.323], t = 22.65, p < 1×10-113), neuroticism ( = 0.567, 95% CI = [0.542, 0.592], t = 44.57, p < 1×10-323), and openness ( = 0.110, 95% CI = [0.083, 0.137], t = 8.06, p < 1×10-16), compared to DeepSeek-V3. Similarly, QwQ-32B shows higher diversity in extraversion ( = 0.253, 95% CI = [0.223, 0.282], t = 16.78, p < 1×10-63), agreeableness ( = 0.490, 95% CI = [0.462, 0.519], t = 34.09, p < 1×10-254), neuroticism ( = 0.825, 95% CI = [0.797, 0.852], t = 58.49, p < 1×10-323), and openness ( = 0.268, 95% CI = [0.238, 0.298], t = 17.41, p < 1×10-68), than Qwen-2.5-32B-IT. In contrast, conscientiousness diversity is lower in DeepSeek-R1 ( = 0.291, 95% CI = [0.317, 0.265], t = 21.90, p < 1×10-106) and QwQ-32B ( = 0.402, 95% CI = [0.435, 0.369], t = 23.79, p < 1×10-125), suggesting that the reasoning model voices appear more consistently engaged and dutiful. The particularly large effects for agreeableness and neuroticism—traits associated with interpersonal harmony and emotional reactivity—suggest that reasoning models generate perspectives that more frequently disagree with and challenge one another. Interestingly, this pattern aligns with prior literature on human team diversity, which suggests that variability in extraversion and neuroticism enhances team performance, whereas variability in conscientiousness impairs it21, 65.
如图 3a 所示,我们发现 DeepSeek-R1 和 QwQ-32B 在控制视角数量的情况下,产生了显著更高的人格多样性。与 DeepSeek-V3 相比,DeepSeek-R1 在外向性( = 0.103, 95% CI = [0.075, 0.131], t = 7.16, p < 1×10 -13 )、宜人性( = 0.297, 95% CI = [0.271, 0.323], t = 22.65, p < 1×10 -113 )、神经质( = 0.567, 95% CI = [0.542, 0.592], t = 44.57, p < 1×10 -323 )和开放性( = 0.110, 95% CI = [0.083, 0.137], t = 8.06, p < 1×10 -16 )方面表现出更高的多样性。同样,与 Qwen-2.5-32B-IT 相比,QwQ-32B 在外向性( = 0.253, 95% CI = [0.223, 0.282], t = 16.78, p < 1×10 -63 )、宜人性( = 0.490, 95% CI = [0.462, 0.519], t = 34.09, p < 1×10 -254 )、神经质( = 0.825, 95% CI = [0.797, 0.852], t = 58.49, p < 1×10 -323 )和开放性( = 0.268, 95% CI = [0.238, 0.298], t = 17.41, p < 1×10 -68 )方面也表现出更高的多样性。相比之下,DeepSeek-R1( = 0.291, 95% CI = [ 0.317, 0.265], t = 21.90, p < 1×10 -106 )和 QwQ-32B( = 0.402, 95% CI = [ 0.435, 0.369], t = 23.)的尽责性多样性较低。79, p < 1×10 -125 ), 表明推理模型的参与度和责任感表现更为一致。对于宜人性与神经质这两个与人际和谐及情绪反应相关的特质而言,其尤为显著的影响表明推理模型生成的观点更频繁地相互分歧和挑战。有趣的是,这一模式与先前关于人类团队多样性的文献相吻合,该文献指出外向性和神经质性的差异性能够提升团队表现,而责任心方面的差异性则会损害团队表现 21, 65 。
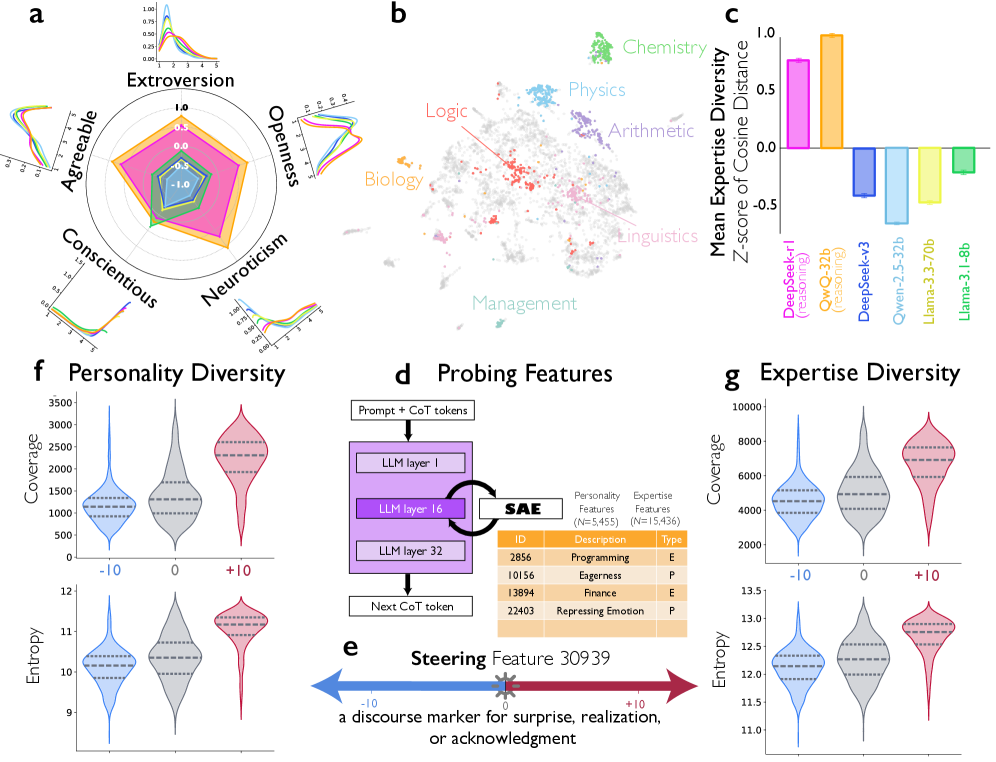
图 3:推理轨迹中的性格与专业多样性。a,使用 LLM 作为评判者和 BFI-10(五因素人格量表 10 项版本)从每个推理轨迹中推断出的隐式推理视角的性格多样性。对于每个五因素维度,多样性通过推断性格的标准差来量化。推理模型(DeepSeek-R1 和 QwQ-32B)在开放性、神经质、宜人性和外向性上表现出显著更高的多样性。核密度估计(KDE)图显示了性格特征在推理轨迹中的分布。b,由 LLM 作为评判者识别的专业嵌入空间,使用 UMAP 投影到二维空间,并以能量最小化布局渲染,揭示了连贯且一致的专业邻近性。c,从每个推理轨迹中推断出的隐式推理视角的专业多样性,通过每个与语义空间中所有嵌入质心的余弦距离的均值来衡量。推理模型比非推理模型的专业多样性大得多。 d, 引导实验中稀疏自编码器(SAE)的架构和特征识别。e, 引导实验的设计。SAE 特征 30939——捕捉表示惊讶、实现或确认的语篇标记,暗示角色和视角的转换——在引导强度为 10 时增加或减少。示例推理轨迹表明,负向引导导致线性思维链轨迹,无引导产生微妙的视角转换以实现自我检查,正向引导导致频繁且显著的视角转换,探索根本不同的解决方案策略。f, g, 在特征 30939 引导下,SAE 与人格相关(f)和专业知识相关(g)特征的覆盖率和熵分布。误差线表示 95%置信区间;实线水平线表示中位数,虚线表示四分位距(25th–75th 百分位数)。
We next examine expertise diversity, defined as the dispersion of conversing agents within the embedding space of inferred domain expertise descriptions. For example, when perspectives drawing on what the models judge as expertise in theoretical physics, analytic reasoning, finance, and creative writing co-occur in the same reasoning trace, the mean distance between their expertise embeddings manifests as large (Fig. 3b). As shown in Fig. 3c, DeepSeek-R1 exhibits significantly higher expertise diversity ( = 0.179, 95% CI = [0.161, 0.196], t = 20.11, p < 1×10-89) than DeepSeek-V3, and QwQ-32B shows higher expertise diversity ( = 0.250, 95% CI = [0.231, 0.269], t = 25.50, p < 1×10-142) than Qwen-2.5-32B-IT, across its implicit reasoning agents than non-reasoning models.
我们接下来考察专业多样性,定义为在推断的领域专业知识描述的嵌入空间中,对话代理的分散程度。例如,当模型认为的理论物理学、分析推理、金融和创意写作等视角在同一推理轨迹中同时出现时,它们的专业知识嵌入之间的平均距离表现为较大(图 3b)。如图 3c 所示,DeepSeek-R1 的专业多样性显著高于 DeepSeek-V3( = 0.179,95%置信区间为[0.161, 0.196],t = 20.11,p < 1×10 -89 ),而 QwQ-32B 的专业多样性( = 0.250,95%置信区间为[0.231, 0.269],t = 25.50,p < 1×10 -142 )高于 Qwen-2.5-32B-IT,在其隐式推理代理中高于非推理模型。
To examine whether the personality- and expertise-related diversity observed in DeepSeek-R1’s and QwQ-32B’s reasoning traces is reflected in the internal representation space of LLMs, we analyze activations of DeepSeek-R1-Llama-8B’s sparse autoencoder (SAE) features. Prior work has shown that high-level persona traits, such as personalities, cultural perspectives, and topics, are linearly represented in LLM activation space and can be steered66, 67, 6. We steer a conversational feature (i.e., Feature 30939; a discourse marker for surprise, realization, or acknowledgment) with strength of +10 or 10 inside the activation space of DeepSeek-R1-Llama-8B, and probe how personality- and expertise-related features are activated in the steered reasoning traces (see Methods: SAE feature steering).
为了检验 DeepSeek-R1 和 QwQ-32B 推理轨迹中观察到的与性格和专业知识相关的多样性是否反映在 LLMs 的内部表示空间中,我们分析了 DeepSeek-R1-Llama-8B 的稀疏自动编码器(SAE)特征的激活情况。先前研究表明,高级性格特征(如性格、文化视角和主题)在 LLM 的激活空间中呈线性表示,并且可以被引导 66, 67, 6 。我们在 DeepSeek-R1-Llama-8B 的激活空间内以+10 或 10 的强度引导一个对话特征(即特征 30939;用于表示惊讶、顿悟或确认的语篇标记),并探究在引导的推理轨迹中,与性格和专业知识相关的特征是如何被激活的(参见方法:SAE 特征引导)。
We first classify each of the 32,768 features as personality-related (e.g., eagerness, expressions of frustration), expertise-related (e.g., programming terminology, financial concepts), or other using an LLM-as-judge approach. We quantify diversity using two complementary measures: coverage, the number of unique personality- or expertise-related features activated across the reasoning trace, and entropy, which captures how evenly activations are distributed across tokens rather than concentrated in a few. Using DeepSeek-R1 reasoning traces, we show that these traces indeed activate more diverse personality-related and expertise-related features, which corroborates our earlier LLM-as-judge results (see Extended Data Fig. 6). For statistical tests, we control for reasoning trace length and problem fixed effects to show that steering conversational surprise activates genuinely more diverse features rather than simply producing longer outputs.
我们首先使用以 LLM 为裁判的方法,将 32,768 个特征分类为与性格相关(例如,热情、沮丧的表达)、与专业领域相关(例如,编程术语、金融概念)或其他类别。我们使用两个互补的指标来量化多样性:覆盖度,即推理过程中激活的独特性格或专业领域相关特征的数目,以及熵,它捕捉了激活在标记(tokens)上分布的均匀性,而不是集中在少数几个标记上。使用 DeepSeek-R1 推理轨迹,我们表明这些轨迹确实激活了更多样化的性格相关和专业领域相关特征,这与我们早期的以 LLM 为裁判的结果相印证(参见扩展数据图 6)。在统计测试中,我们控制了推理轨迹长度和问题固定效应,以表明引导对话的意外性确实激活了更多样化的特征,而不仅仅是产生更长的输出。
As shown in Fig. 3e–f, steering with +10 strength causes reasoning traces to activate a wider coverage of both personality-related features ( = 315.915, 95% CI = [277.320, 354.509], t = 16.04, p < 1×10-323) and expertise-related features ( = 391.312, 95% CI = [313.743, 468.880], t = 9.89, p < 1×10-323) compared to unsteered traces, controlling for reasoning trace length and problem fixed effects. For example, after steering, personality-related features such as “informal expressions of confusion or frustration” (Feature 21065), “phrases related to social interaction and community engagement” (Feature 26139), and “references to emotional or sensational themes in narratives” (Feature 14476) are activated more frequently (see Supplementary Table 4 and 5).
如图 3e–f 所示,使用+10 强度进行引导时,推理轨迹激活了更广泛的人格相关特征( = 315.915,95%置信区间=[277.320, 354.509],t=16.04,p < 1×10 -323 )和专业知识相关特征( = 391.312,95%置信区间=[313.743, 468.880],t=9.89,p < 1×10 -323 ),相比之下,未引导的轨迹在控制推理轨迹长度和问题固定效应的情况下表现不同。例如,引导后,“表达困惑或沮丧的非正式方式”(特征 21065)、“与社会互动和社区参与相关的短语”(特征 26139)以及“叙事中涉及情感或刺激性主题的引用”(特征 14476)等人格相关特征被更频繁地激活(参见补充表 4 和 5)。
To further examine that this increased diversity reflects a broader distribution of activated features rather than simply generating more tokens, we measure the Shannon entropy of feature activations. Higher entropy indicates that activations are more evenly distributed across diverse features, rather than concentrated in a few dominant ones. Steered traces exhibit higher entropy of both personality-related features ( = 0.262, 95% CI = [0.227, 0.298], t = 14.48, p < 1×10-323) and expertise-related features ( = 0.096, 95% CI = [0.075, 0.117], t = 9.02, p < 1×10-323) than unsteered traces, confirming that steering induces more diverse feature activations beyond merely increasing output length.
为了进一步检验这种多样性增加是否反映了激活特征的更广泛分布,而非仅仅是生成更多符号,我们测量了特征激活的香农熵。更高的熵表明激活在多样化的特征中分布更均匀,而非集中在少数主导特征上。引导轨迹在人格相关特征( = 0.262, 95% CI = [0.227, 0.298], t = 14.48, p < 1×10 -323 )和专业知识相关特征( = 0.096, 95% CI = [0.075, 0.117], t = 9.02, p < 1×10 -323 )的熵值均高于非引导轨迹,证实引导不仅增加了输出长度,还诱导了更多样化的特征激活。
Reinforcement Learning Experiments
强化学习实验
To further examine whether LLMs self-reinforce conversational behaviours when rewarded for correct answers, we implement a self-taught reinforcement learning (RL) experiment. In this setup, the model explores solution strategies for the Countdown arithmetic puzzle game8, 52, where the model must combine a given set of numbers using basic arithmetic operations (+, , ×, ÷) and parentheses to reach a target. We also replicate these findings on political misinformation detection, where models discriminate between true and fabricated political headlines.
为了进一步检验 LLMs 在因正确答案获得奖励时是否会自我强化对话行为,我们实施了一个自教学强化学习(RL)实验。在该设置中,模型探索解决 Countdown 算术谜题游戏的策略,其中模型必须使用基本算术运算(+、 、×、÷)和括号组合给定的数字以达到目标。我们还将在政治虚假信息检测上复制这些发现,其中模型需区分真实与编造的政治标题。
Following the reward architecture of DeepSeek-R14, we reward accuracy and correct format (i.e., wrapping reasoning between <think> and </think> tags and answers between <answer> and </answer> tags) with a simple weighted reward: accuracy × 0.9 + format × 0.1. Crucially, we do not directly reward conversational or cognitive behaviours. We implement Proximal Policy Optimization (PPO)68 using the Verl framework69, training for 250 steps (see Supplementary Table 6 for hyperparameters). We use Qwen-2.5-3B, a pre-trained model without any instruction-tuning, prompted to solve the Countdown task with a chain of thought (see Methods: Reinforcement learning experiments).
遵循 DeepSeek-R1 4 的奖励架构,我们用简单的加权奖励来奖励准确性和正确格式(即推理部分用 和 标签包裹,答案部分用 和 标签包裹):准确性 × 0.9 + 格式 × 0.1。关键在于,我们不直接奖励对话或认知行为。我们使用 Verl 框架 69 实现近端策略优化(PPO) 68 ,训练 250 步(超参数见补充表 6)。我们使用未经指令微调的预训练模型 Qwen-2.5-3B,提示其用思维链解决 Countdown 任务(参见方法:强化学习实验)。
We first examine whether conversational behaviours spontaneously increase despite not being directly rewarded. Fig. 4a presents the results, showing that accuracy improves substantially over training, rising from near zero at baseline to approximately 58% by step 250. Fig. 4b reveals that the frequency of conversational behaviours—particularly Question & Answering and Conflict of Perspectives—rise throughout training despite receiving no direct reward. Perspective shifts also increase until approximately step 160, although they start to decrease as the model becomes able to reach answers with fewer shifts across the training phase. Fig. 4c-d illustrate this qualitative shift: at step 40, the model produces mechanical, enumerative chain-of-thought-style reasoning, whereas by step 120, two distinctive simulated personas have appeared, recognizing their collectivity with the pronoun “we”—expressing uncertainty (“Again no luck”), considering alternatives (“Maybe we can try using negative numbers”), and reflecting on problem constraints. As shown in Fig. 4e, these behaviours occur while the model employs two distinct personas according to LLM-as-judge evaluation: a methodical problem-solver high in Conscientiousness and low in Openness, and an exploratory trial-and-error thinker high in Openness and Extraversion, with metacognitive reflection on solvability—marked by Neuroticism—mediating between the two. Similar to our earlier findings based on sparse autoencoders, the increase of these behaviours has co-occurred with the increase of other cognitive behaviours, such as verification and backtracking (Extended Data Fig. 7).
我们首先考察在没有直接奖励的情况下,对话行为是否自发增加。图 4a 展示了结果,显示准确率在训练过程中显著提高,从基线时的接近零上升到第 250 步时的约 58%。图 4b 揭示,尽管没有直接奖励,对话行为的频率——尤其是问答和观点冲突——在训练过程中持续上升。视角转换也增加,直到大约第 160 步,尽管随着模型能够在训练阶段用更少的转换次数得出答案,视角转换开始减少。图 4c-d 说明了这种定性转变:在第 40 步,模型产生的是机械的、列举式的思维链式推理,而到了第 120 步,两个独特的模拟人格已经出现,他们用代词“我们”来认识他们的集体——表达不确定性(“再次没运气”)、考虑替代方案(“也许我们可以尝试使用负数”),并反思问题约束。如图所示。 4e,这些行为发生在模型根据 LLM 作为评判者评估时采用两种不同人格时:一种是有条理的问题解决者,高责任心、低开放性,另一种是探索性的试错思考者,高开放性和外向性,同时具有元认知反思——以神经质为特征——在两者之间进行调节。类似于我们基于稀疏自编码器之前的发现,这些行为的增加与其他认知行为的增加(如验证和回溯)同时发生(扩展数据图 7)。
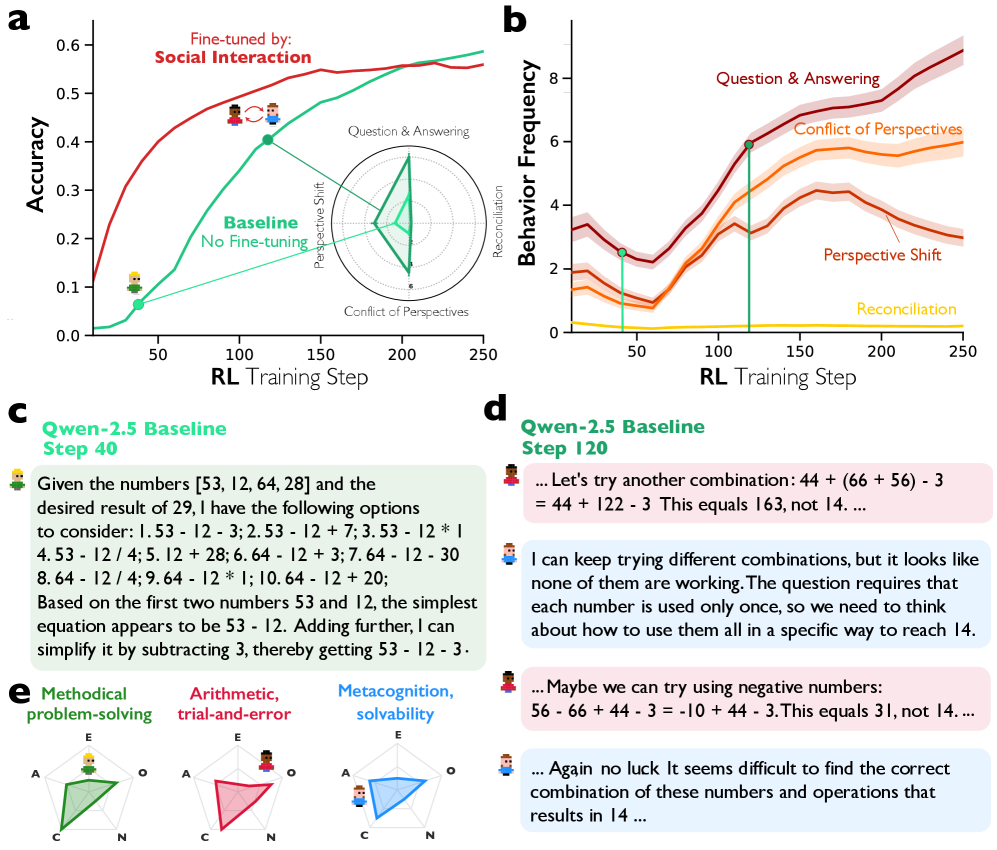
图 4:在奖励准确性强化学习和对话式脚手架微调下社会行为的发生情况及其影响。a,对比了使用问题解决准确性作为奖励的强化学习中,基线 Qwen-2.5-3B 模型与初始通过 Qwen-2.5-32B 生成的多智能体对话模拟社会交互进行微调的相同模型的准确性轨迹。社会初始化模型更快达到最大准确性,而基线模型最终迎头赶上,并通过采用对话行为,包括提问与回答、视角转换和视角冲突来实现。b,a 图强化学习基线模型中个体对话行为的轨迹。问答行为首先出现,随后是视角转换和冲突,它们几乎同步上升。和解行为几乎没有增加,表明个体方法相互竞争而非形成有效组合。线条使用指数移动平均(跨度=9)平滑,阴影区域表示 95%置信区间。c–d,Qwen-2.5 个基线模型在训练步骤 40 与步骤 120 时的对比。在步骤 40 时,模型主要进行线性思维链推理,而到步骤 120 时,已出现两个具有鲜明个性的模拟角色,它们通过使用代词“我们”明确地认识到自己的集体性。e,由 LLM 作为评判者推断出的人格特征。步骤 40 的模型表现出强烈的全能型问题解决特征,其特点为高度责任心、中等偏高的开放性和随和性、较低的外向性,以及显著较低的神经过敏性。相比之下,在步骤 120 观察到的两个协作代理显示出不同的人格特征:一个强调试错式问题解决,而另一个专门进行关于不同方法问题解决性的元认知推理。试错式代理比步骤 40 的代理外向性更低、随和性更高,而专注于问题解决性的代理则更开放,责任心显著更低。
To corroborate the role of conversational behaviours in reasoning improvement, we compare RL training under three conditions: (1) Baseline (RL only, no priming), (2) Conversation fine-tuning (supervised fine-tuning on multi-agent dialogue text before RL), and (3) Monologue fine-tuning (fine-tuning on monologue-like, step-by-step reasoning traces before RL). To generate conversational fine-tuning data, we prompt Qwen-2.5-32B-IT to produce multi-agent-like dialogues with two, three, or four distinct personas solving 8,262 reasoning tasks (see Methods: Data), and sample 600 instances that reach correct answers (500 for training, 100 for validation). In these dialogues, the model first defines distinct personas with different personality traits and expertise (e.g., <persona1> a meticulous mathematician with a strong background in number theory </persona1>, <persona2> a quick-witted and intuitive problem solver… not afraid to challenge assumptions </persona2>). These personas then engage in turn-taking dialogue where they build on, question, and correct each other’s reasoning (e.g., <think1> We can discard (2, 7) because… they are not coprime. </think1> <think2> Wait a second. We can’t discard (2, 7) just yet… they are indeed coprime because their greatest common divisor is 1. </think2> → <think1> You’re right. I overlooked that. </think1>), before converging on a final answer in <group_solution> … </group_solution>.
为验证对话行为在推理能力提升中的作用,我们比较了三种条件下的强化学习训练:(1) 基线(仅强化学习,无预训练),(2) 对话微调(在强化学习前对多智能体对话文本进行监督微调),以及(3) 独白微调(在强化学习前对类似独白的逐步推理轨迹进行微调)。为生成对话微调数据,我们提示 Qwen-2.5-32B-IT 生成包含两个、三个或四个不同角色的多智能体式对话,解决 8,262 个推理任务(参见方法:数据),并从中采样达到正确答案的 600 个实例(500 个用于训练,100 个用于验证)。在这些对话中,模型首先定义具有不同性格特征和专业知识的不同角色(例如,<persona1>一位精通数论的严谨数学家</persona1>,<persona2>一位思维敏捷、直觉敏锐的问题解决者……敢于挑战假设</persona2>)。这些角色随后进行轮流对话,相互补充、质疑和修正彼此的推理(例如,<think1>我们可以舍弃(2, 7),因为……它们不是互质的。</think1> <think2>等等。 我们暂时还不能排除(2, 7)……它们确实互质,因为它们的最大公约数是 1。</think2> → <think1> 你是对的。我疏忽了这一点。</think1>),然后最终在<group_solution>……</group_solution>中得出答案。
For monologue fine-tuning data, we generate standard chain-of-thought traces for the “same problems” with correct answers, where a single voice reasons within <think> … </think> tags (e.g., <think> Since the GCD of m and n is 8, we can express m and n as 8a and 8b respectively, where a and b are coprime… The pairs of factors of 14 are (1, 14) and (2, 7). </think>). Supplementary Table 7 presents full examples for both types of fine-tuning data. We then fine-tune Qwen-2.5-3B on these datasets using standard next-token prediction loss wherein the models learn to reproduce the full output sequence (persona definitions, turn-by-turn reasoning or monologue trace, and final answer) given only the problem as input. This priming phase familiarizes the model with conversational versus monologue formats before RL optimizes for task accuracy (see Supplementary Table 8 for SFT hyperparameters).
对于独白微调数据,我们为“相同问题”生成带有正确答案的标准思维链轨迹,其中单个声音在<think> … </think>标签内进行推理(例如,<think>由于 m 和 n 的最大公约数是 8,我们可以将 m 和 n 分别表示为 8a 和 8b,其中 a 和 b 互质……14 的因数对是(1, 14)和(2, 7)。</think>)。补充表 7 展示了这两种微调数据的完整示例。然后我们使用标准的下一个词预测损失在这些数据集上微调 Qwen-2.5-3B,其中模型学习在仅给出问题作为输入的情况下重现完整的输出序列(角色定义、逐回合推理或独白轨迹,以及最终答案)。这个预训练阶段使模型熟悉对话与独白格式,然后通过强化学习优化任务准确率(有关 SFT 超参数,请参见补充表 8)。
Extended Data Fig. 8 shows that models fine-tuned on conversational data achieve faster accuracy gains than monologue-fine-tuned models, particularly in the early stages of training. At step 40, conversation-fine-tuned Qwen-2.5-3B models reach approximately 38% accuracy while monologue-fine-tuned models remain at 28%. This pattern replicates across architectures: in Llama-3.2-3B (see Supplementary Methods: Replications on Llama-3.2-3B), the conversation-fine-tuned model reaches 11% accuracy at step 70 compared to just 5% for monologue-fine-tuned models. Interestingly, in Llama-3.2-3B, the divergence becomes more striking as training progresses. By step 150, conversation-fine-tuned Llama models achieve 40% accuracy while monologue-fine-tuned models plateau around 18%, less than half the performance. Notably, both conditions are trained on identical problems and correct answers, yet conversation-fine-tuned models consistently improve faster and reach higher asymptotic accuracy. This indicates that conversational structure itself, not merely exposure to correct solutions or task-related knowledge, drives the improvement.
扩展数据图 8 显示,在对话数据上微调的模型比在独白数据上微调的模型获得更快的准确率提升,尤其是在训练的早期阶段。在步骤 40 时,对话微调的 Qwen-2.5-3B 模型达到约 38%的准确率,而独白微调的模型仍停留在 28%。这种模式在架构中得到了复制:在 Llama-3.2-3B(参见补充方法:Llama-3.2-3B 上的复制实验),对话微调的模型在步骤 70 时达到 11%的准确率,而独白微调的模型仅为 5%。有趣的是,在 Llama-3.2-3B 中,随着训练的进行,这种差异变得更加显著。在步骤 150 时,对话微调的 Llama 模型达到 40%的准确率,而独白微调的模型则停滞在 18%左右,性能不到一半。值得注意的是,两种条件都在相同的问题和正确答案上进行训练,但对话微调的模型始终提升更快,并达到更高的渐近准确率。这表明,对话结构本身,而不仅仅是接触正确解决方案或任务相关知识,推动了这种改进。
We further test whether conversational scaffolding transfers across domains. Models fine-tuned on multi-agent dialogues for the Countdown task are evaluated on a qualitatively different task: political misinformation detection, where models discriminate between true and fabricated headlines from 23,299 fact-checked claims from PolitiFact. Despite never encountering this domain during fine-tuning, conversation-primed models achieve faster accuracy gains than baseline models (see Supplementary Methods: Cross-domain reasoning transfer and Extended Data Fig. 9). Together, these results suggest that conversational structure facilitates the emergence of reasoning strategies during RL.
我们进一步测试了对话支架是否能在不同领域间迁移。在 Countdown 任务的多智能体对话上微调的模型,在评估一个性质上不同的任务:政治虚假信息检测,该任务要求模型从 PolitiFact 提供的 23,299 条经过事实核查的声明中区分真实和编造的标题。尽管在微调期间从未接触过这个领域,对话预训练的模型比基线模型实现了更快的准确率提升(参见补充方法:跨领域推理迁移和扩展数据图 9)。这些结果共同表明,对话结构促进了在强化学习过程中推理策略的涌现。
Discussion 讨论
Our findings suggest that reasoning models like DeepSeek-R1 do not simply generate longer or more elaborate chains of thought. Rather, they exhibit patterns characteristic of a social and conversational process generating “societies of thought”—posing questions, introducing alternative perspectives, generating and resolving conflicts, and coordinating diverse socio-emotional roles. These interactional patterns rarely occur in non-reasoning models across different model sizes (671B, 70B, 32B, 8B), even when controlling for reasoning trace length, suggesting that reasoning optimization introduces an intrinsic social structure within the reasoning process itself rather than merely increasing text volume. The model appears to reason by simulating internal societies, structuring thought as an exchange among interlocutors rather than as a single uninterrupted voice. The implication here is that social reasoning emerges autonomously through RL as a function of its consistent ability to produce correct answers, rather than through explicit human supervision or fine-tuning.
我们的研究发现,像 DeepSeek-R1 这样的推理模型并不仅仅生成更长或更复杂的思维链。相反,它们表现出一种社会和对话过程的模式,这种模式会生成“思维社会”——提出问题、引入不同视角、产生和解决冲突,以及协调多样的社会情感角色。这些互动模式在不同的非推理模型(671B、70B、32B、8B)中很少出现,即使控制了推理追踪长度也是如此,这表明推理优化在推理过程中引入了内在的社会结构,而不仅仅是增加文本量。该模型似乎通过模拟内部社会来进行推理,将思维结构化为对话者之间的交流,而不是单一不间断的声音。这一启示是,社会性推理通过 RL 自主地产生,这是因为它持续地能够产生正确答案,而不是通过明确的人类监督或微调。
This structure does not appear to be merely stylistic. Conversational behaviours and socio-emotional roles are more frequently activated when DeepSeek-R1 faces more difficult problems, and they explain a substantial portion of the accuracy advantage over non-reasoning models. Steering experiments provide evidence that conversational markers are tied to reasoning performance. When we amplify a feature associated with conversational surprise—a discourse marker signaling perspective shift and constrast—accuracy on multi-step reasoning tasks doubles. Structural equation modeling reveals that conversational steering is associated with accuracy through both direct effects and indirect pathways mediated by cognitive strategies previously identified as central to reasoning, including verification, backtracking, subgoal setting, and backward chaining. This suggests that the social structure of reasoning might not be epiphenomenal but mechanistically implicated in how the model explores solution spaces and deploys effective problem-solving strategies.
这种结构似乎并不仅仅是风格上的。当 DeepSeek-R1 面对更困难的问题时,对话行为和社会情感角色会被更频繁地激活,它们解释了模型相对于非推理模型的准确率优势的大部分。转向实验提供了证据,表明对话标记与推理性能相关。当我们增强与对话惊讶相关的特征——一个指示视角转换和对比的语篇标记——多步推理任务的准确率会翻倍。结构方程模型揭示,对话转向通过直接效应和间接路径(这些路径由先前被识别为推理核心的认知策略所中介,包括验证、回溯、子目标设定和反向链接)与准确率相关。这表明,推理的社会结构可能并非伴随现象,而是机制性地涉及模型探索解决方案空间和部署有效问题解决策略的方式。
We further find that this interactional organization is supported by diversity among multiple implicit “voices” within reasoning traces. These voices vary systematically in personality traits and domain expertise, and mechanistic interpretability analyses corroborate that models activate more diverse personality- and expertise-related features when steered toward conversational markers. This pattern suggests that findings from human team research—where diversity in socially oriented traits such as extraversion and neuroticism enhances collective performance, whereas diversity in task-oriented traits such as conscientiousness can impair coordination and efficiency21, 65—may offer a useful lens for interpreting language models’ collective reasoning behaviours. Most R1 reasoning personas were surprisingly disciplined and hard-working!
我们进一步发现,这种交互组织得到了推理轨迹中多个隐含“声音”之间多样性的支持。这些声音在人格特质和领域专业知识上存在系统差异,而机制可解释性分析证实,当模型被引导至对话标记时,会激活更多与人格和专业知识相关的特征。这种模式表明,人类团队研究中的发现——在社会导向特质(如外向性和神经质)的多样性会提升集体表现,而在任务导向特质(如责任心)的多样性会损害协调性和效率——可能为解释语言模型的集体推理行为提供了一个有用的视角。大多数 R1 推理角色出人意料地自律且勤奋!
Reinforcement learning (RL) experiments further support the functional role of conversational structure. Models fine-tuned on multi-agent dialogues learn to reason more effectively than models fine-tuned only on correct, monologue-like reasoning traces. The benefit therefore lies not in the correctness of initial reasoning but in the procedural scaffolding provided by conversational organization. Although these experiments used relatively small 3B-parameter models (Qwen-2.5-3B and Llama-3.2-3B) on simple arithmetic tasks and misinformation detection tasks, the results suggest that even minimal social structuring within reasoning traces can accelerate the emergence of generalizable reasoning behaviour.
强化学习(RL)实验进一步支持了对话结构的职能作用。在多智能体对话上微调的模型比仅在正确的、类似独白的推理轨迹上微调的模型更能有效地进行推理。因此,这种优势不在于初始推理的正确性,而在于对话组织提供的程序性支架。尽管这些实验使用了相对较小的 3B 参数模型(Qwen-2.5-3B 和 Llama-3.2-3B),在简单的算术任务和虚假信息检测任务上,但结果表明,即使在推理轨迹中存在最小的社会结构,也能加速通用推理行为的出现。
Collectively, these findings suggest the benefits of studying “social scaling” in reasoning-optimized models. As their test-time computations expand, reasoning traces evolve from isolated monologues into structured dialogues among differentiated internal perspectives. High-performing reasoning thus seems to depend on how attention, role-taking, and conflict resolution are coordinated within emergent “societies of thought.” Our goal is not to take sides on whether reasoning model traces should be regarded as discourse among simulated human groups or a computational mind’s simulation of such discourse. Indeed, as we note above, even this distinction becomes fundamentally unclear as some theories of cognition posit how mature individual minds develop from simulations of multi-agent interaction. Nevertheless, alignments between our findings on successful reasoning models and prior literature on successful human teams (e.g., diverse personality traits lead to successful collaborations) suggest that principles governing effective group collaboration may offer valuable insights for interpreting and engineering reasoning behaviours in language models. This perspective extends long-standing research on human team collaboration, where group composition and diversity are known to shape collective intelligence through variations in personality and expertise16, 17, 18, 19, 11, 20, 21 . Analogous dynamics within AI systems remain largely unexplored. Early investigations of human–AI collaboration70 have begun to characterize this emerging domain, but how diversity and coordination operate within the reasoning traces of large language models remains an open question. DeepSeek-R1’s and QwQ’s internal reasoning patterns suggest that such models may already self-organize a productive heterogeneity of perspectives, implying that diversity could be as fundamental to artificial reasoning as it is to human collaboration and collective dominance.
这些发现共同表明,研究推理优化模型中的“社会规模”具有益处。随着它们在测试时的计算扩展,推理轨迹从孤立的独白演变为不同内部视角之间的结构化对话。因此,高性能的推理似乎取决于在涌现的“思想社会”中如何协调注意力、角色扮演和冲突解决。我们的目标不是判断推理模型轨迹是否应该被视为模拟人类群体之间的对话,或是计算心智对这种对话的模拟。事实上,正如我们上述所述,即使这种区分也随着一些认知理论提出成熟个体心智如何从多智能体交互模拟中发展而来而变得根本性模糊。然而,我们关于成功推理模型的研究发现与先前关于成功人类团队的文献(例如,多样的人性特质导致成功的合作)之间的契合表明,有效群体协作的治理原则可能为解释和设计语言模型中的推理行为提供有价值的见解。 这一视角延续了关于人类团队协作的长期研究,其中团队构成和多样性通过人格和专长上的差异塑造集体智能 16, 17, 18, 19, 11, 20, 21 。人工智能系统内部的类似动态仍基本未被探索。早期关于人机协作 70 的研究开始描述这一新兴领域,但多样性和协调如何在大型语言模型的推理轨迹中运作仍是一个悬而未决的问题。DeepSeek-R1 和 QwQ 的内部推理模式表明,这类模型可能已经自我组织起一种富有成效的视角异质性,这意味着多样性对于人工智能推理而言,可能和它对于人类协作和集体主导一样根本。
A growing trend in AI involves agentic architectures that deploy multiple agents engaged in more complex configurations than single-channel debate, including hierarchy, complex networks and even entire institutions of interacting agents71, 72, 42, 43, 44, 45, 46, 34. Our work suggests the importance of exploring alternative structures, but also inhabiting them with diverse perspectives, personalities, and specialized expertise that drive complementarity and collective success in the human social world. Understanding how diversity and social scaffolding interact could shift how we conceptualize large language models, from solitary problem-solving entities toward collective reasoning architectures, where intelligence arises not merely from scale but the structured interplay of distinct voices.
人工智能领域的一个日益增长的趋势是采用多智能体架构,这些智能体在比单通道辩论更复杂的配置中运作,包括层级结构、复杂网络,甚至整个由交互智能体组成的机构 71, 72, 42, 43, 44, 45, 46, 34 。我们的研究表明探索替代结构的重要性,但也需要用多样化的视角、个性和专业领域来充实这些结构,这些因素在人类社会中驱动互补性和集体成功。理解多样性和社会支架如何相互作用,可能会改变我们如何概念化大型语言模型,从孤独的解决问题实体转变为集体推理架构,其中智能不仅源于规模,更源于不同声音的结构化互动。
Methods 方法
Data 数据
We generate chains of thought and final answers for 8,262 reasoning problems spanning symbolic logic, mathematical problem solving, scientific reasoning, instruction following, and multi-agent inference. The benchmark suite includes BigBench Hard (BBH) tasks requiring multi-step logical inference, reference tracking, and compositional reasoning; GPQA (Graduate-level Physics Question Answering) for graduate-level STEM reasoning; MATH (Hard) subset for multi-step derivations across algebra, geometry, probability, and number theory; MMLU-Pro for advanced conceptual knowledge; IFEval for instruction-following consistency; and MUSR (Mathematics Understanding and Symbolic Reasoning) for symbolic manipulation and structured mathematical reasoning (see Supplementary Table 9 for details).
我们为涵盖符号逻辑、数学问题解决、科学推理、指令遵循和多智能体推理的 8,262 个推理问题生成了思维链和最终答案。基准测试套件包括需要多步逻辑推理、引用跟踪和组合推理的 BigBench Hard (BBH)任务;用于研究生级 STEM 推理的 GPQA(研究生级物理问答);用于代数、几何、概率和数论等多步推导的 MATH(难)子集;用于高级概念知识的 MMLU-Pro;用于指令遵循一致性的 IFEval;以及用于符号操作和结构化数学推理的 MUSR(数学理解和符号推理)(详情请参见补充表 9)。
We generate responses using six models: two reasoning models—DeepSeek-R1-0528 (671B parameters) and QwQ-32B—and four instruction-tuned models—DeepSeek-V3-0324 (671B parameters), Qwen-2.5-32B-Instruct, Llama-3.3-70B-Instruct, and Llama-3.1-8B-Instruct—under a zero-shot setting. DeepSeek-V3 is the instruction-tuned model based on DeepSeek-V3-Base from which DeepSeek-R1 is derived through reinforcement learning, and Qwen-2.5-32B-Instruct is the instruction-tuned model based on Qwen-2.5-32B from which QwQ-32B is derived. For brevity, we refer to these models as DeepSeek-R1, QwQ-32B, DeepSeek-V3, Qwen-2.5-32B-IT, Llama-3.3-70B-IT, and Llama-3.1-8B-IT, respectively. We set the temperature to 0.6, a temperature recommended for standard reasoning tasks4.
我们使用六个模型生成响应:两个推理模型——DeepSeek-R1-0528(671B 参数)和 QwQ-32B,以及四个指令微调模型——DeepSeek-V3-0324(671B 参数)、Qwen-2.5-32B-Instruct、Llama-3.3-70B-Instruct 和 Llama-3.1-8B-Instruct——在零样本设置下。DeepSeek-V3 是基于 DeepSeek-V3-Base 的指令微调模型,DeepSeek-R1 通过强化学习从 DeepSeek-V3-Base 衍生而来;Qwen-2.5-32B-Instruct 是基于 Qwen-2.5-32B 的指令微调模型,QwQ-32B 从 Qwen-2.5-32B 衍生。为简洁起见,我们将这些模型分别称为 DeepSeek-R1、QwQ-32B、DeepSeek-V3、Qwen-2.5-32B-IT、Llama-3.3-70B-IT 和 Llama-3.1-8B-IT。我们将温度设置为 0.6,这是标准推理任务推荐的温度 4 。
Measurements 测量
Conversational Behaviours
对话行为
We identify four conversational behaviours in reasoning traces using an LLM-as-judge approach with Gemini-2.5-Pro. (1) Question–answering is defined as sequences where a question is posed and later answered, as in conversations (e.g., “Why…? Because…”, “What if…? Then…”, “How do we know? Well…”, and “Let’s try X…? This gives us Y”). (2) Perspective shift is defined as a transition to a different idea, viewpoint, assumption, or approach, as in conversations. (3) Conflict of perspectives is defined as expressions of disagreement, correction, or tension with another perspective (e.g., “Wait, that can’t be right…”, “No, actually…”, and “This contradicts…”). (4) Reconciliation is defined as instances where conflicting views are integrated or resolved into a coherent synthesis (e.g., “So perhaps both are true if…”, “Combining these insights…”, and “This resolves the tension…”. For each reasoning trace, the LLM-as-judge counts the number of distinct instances of each behaviour, returning integer counts (0 if none are present). The full prompt is provided in Supplementary Methods: LLM-as-judge prompts. See Supplementary Table 10 for the descriptive statistics of conversational behaviors for reasoning and instruction-tuned models.
我们使用以 Gemini-2.5-Pro 为判别器的 LLM 方法,在推理轨迹中识别出四种对话行为。(1) 问答被定义为提出问题并随后回答的序列,类似于对话中的情况(例如,“为什么…?因为…”,“如果…?那么…”,“我们如何知道?嗯…”,以及“让我们试试 X…?这给我们 Y”)。(2) 观点转换被定义为转换到不同的想法、观点、假设或方法,类似于对话中的情况。(3) 观点冲突被定义为与其他观点的分歧、纠正或紧张关系的表达(例如,“等等,那不正确…”,“不,实际上…”,以及“这与…矛盾…”)。(4) 调和被定义为冲突观点被整合或解决为连贯综合的实例(例如,“所以如果…两者可能都正确”,“结合这些见解…”,以及“这解决了紧张关系…”)。对于每条推理轨迹,以 Gemini-2.5-Pro 为判别器的 LLM 会计算每种行为的独立实例数量,并返回整数计数(如果不存在则为 0)。完整的提示信息在补充方法中提供:以 Gemini-2.5-Pro 为判别器的 LLM 提示。 参见补充表 10,了解推理和指令调优模型的对话行为描述性统计。
For the four conversational categories, Gemini-2.5-Pro and GPT-5.2 demonstrated substantial agreement: Question-and-Answering (ICC(3,1) = .856), Perspective Shift (ICC(3,1) = .849), Conflict of Perspectives (ICC(3,1) = .912), and Reconciliation (ICC(3,1) = .804), with a mean ICC of .855. Gemini-2.5-Pro also showed agreement with human ratings across the four conversational categories: Question-and-Answering (ICC(3,1) = .634), Perspective Shift (ICC(3,1) = .737), Conflict of Perspectives (ICC(3,1) = .864), and Reconciliation (ICC(3,1) = .664).
对于四个对话类别,Gemini-2.5-Pro 和 GPT-5.2 表现出高度一致性:问答(ICC(3,1) = .856)、视角转换(ICC(3,1) = .849)、视角冲突(ICC(3,1) = .912)和和解(ICC(3,1) = .804),平均 ICC 值为.855。Gemini-2.5-Pro 在四个对话类别中与人类评分也表现出一致性:问答(ICC(3,1) = .634)、视角转换(ICC(3,1) = .737)、视角冲突(ICC(3,1) = .864)和和解(ICC(3,1) = .664)。
Socio-Emotional Roles 社会情感角色
We analyze the presence of socio-emotional roles within reasoning traces using Bales’ Interaction Process Analysis (IPA) framework55. The IPA classifies utterances into 12 interaction roles, each operationally defined in the prompt with specific behavioural descriptions. The LLM-as-judge (Gemini-2.5-Pro) counts the number of distinct instances of each of the 12 categories separately, and we aggregate these counts into four higher-level categories for our main analyses:
我们使用 Bales 的互动过程分析(IPA)框架 55 分析推理痕迹中的社会情感角色存在情况。IPA 将话语分类为 12 种互动角色,每个角色在提示中通过特定的行为描述进行操作定义。作为裁判的 LLM(Gemini-2.5-Pro)分别统计 12 个类别的不同实例数量,我们将这些计数汇总为四个高级类别,用于主要分析。
-
•
Information-giving roles:
• 提供信息角色:-
–
Gives suggestion (gives direction, implying autonomy; e.g., should…, need to…, let us…)
– 提供建议(提供方向,暗示自主性;例如,应该…,需要…,让我们…) -
–
Gives opinion (gives evaluation, analysis, expresses feeling or wish)
– 提供观点(进行评价,分析,表达感受或愿望) -
–
Gives orientation (provides objective or verifiable information, repeats, clarifies, confirms)
– 提供指导(提供客观或可验证的信息,重复,澄清,确认)
-
–
-
•
Information-asking roles:
• 信息询问角色:-
–
Asks for suggestion (requests possible ways of action or direction)
– 请求建议(要求可能的行动方式或方向) -
–
Asks for opinion (requests evaluation, analysis, or expression of feeling)
– 请求意见(要求评价、分析或表达感受) -
–
Asks for orientation (requests information, repetition, or confirmation)
– 请求指引(要求信息、重复或确认)
-
–
-
•
Positive emotional roles:
• 积极情绪角色:-
–
Shows solidarity (raises other’s status, gives help, reward)
– 表现团结(提升他人地位,提供帮助,给予奖励) -
–
Shows tension release (jokes, laughs, shows satisfaction)
– 展现紧张释放(开玩笑,大笑,表现出满意) -
–
Agrees (shows passive acceptance, understands, concurs, complies)
– 同意(表现出被动接受,理解,赞同,遵从)
-
–
-
•
Negative emotional roles:
• 负面情绪角色:-
–
Shows antagonism (deflates other’s status, defends or asserts self)
– 表现对抗性(贬低他人地位,维护或主张自我) -
–
Shows tension (expresses uncertainty, asks for help, withdraws from the field)
– 表现紧张(表达不确定性,寻求帮助,退出领域) -
–
Disagrees (shows passive rejection, formality, or withholds help)
– 不同意(表现出被动拒绝,正式或保留帮助)
-
–
Inter-rater reliability is substantial for the four higher-level IPA categories used in our main analyses: Ask (Gemini-2.5-Pro vs. GPT-5.2: ICC(3,1) = .939; Gemini-2.5-Pro vs. Human: ICC(3,1) = .836), Give (ICC(3,1) = .864; ICC(3,1) = .666), Positive (ICC(3,1) = .939; ICC(3,1) = .870), and Negative (ICC(3,1) = .838; ICC(3,1) = .779). See Supplementary Table 10 for the descriptive statistics of socio-emotional roles for reasoning and instruction-tuned models.
评分者间信度对于我们主要分析中使用的四个较高层级的 IPA 类别是显著的:询问(Gemini-2.5-Pro 与 GPT-5.2:ICC(3,1) = .939;Gemini-2.5-Pro 与人类:ICC(3,1) = .836)、给予(ICC(3,1) = .864;ICC(3,1) = .666)、积极(ICC(3,1) = .939;ICC(3,1) = .870)和消极(ICC(3,1) = .838;ICC(3,1) = .779)。有关推理和指令调优模型的社会情感角色的描述性统计数据,请参见补充表 10。
To measure whether socio-emotional roles co-occur reciprocally within reasoning traces, we compute the Jaccard index for two role pairs: (1) asking versus giving for task-oriented roles, and (2) positive versus negative for emotional roles. The Jaccard index is defined as the number of reasoning traces containing both roles in a pair divided by the number of reasoning traces containing either role, capturing whether models coordinate complementary roles within the same trace rather than deploying them in isolation. Higher Jaccard indices indicate more balanced, dialogue-like interaction patterns, whereas lower indices suggest one-sided, monologic reasoning.
为了测量社会情感角色是否在推理痕迹中相互共存,我们计算了两个角色对的杰卡德指数:(1)任务导向角色的询问与给予,以及(2)情感角色的积极与消极。杰卡德指数定义为包含一对中两个角色的推理痕迹数量除以包含任一角色的推理痕迹数量,捕捉模型是否在同一痕迹中协调互补角色,而不是孤立地使用它们。较高的杰卡德指数表明更平衡、类似对话的交互模式,而较低的指数则暗示单向、独白的推理。
Cognitive Behaviours 认知行为
We identify four cognitive behaviours previously established as contributors to reasoning accuracy in language models using Gemini-2.5-Pro as LLM-as-judge4, 8, 36, 35, 37. For the measurement, we adopt the prompt and examples used by Gandhi and colleagues (2025)8, which has been verified by multiple human raters. Each behaviour is operationally defined in the prompt with specific examples to guide annotation: Verification is defined as instances where the chain-of-reasoning explicitly checks the current result against the target solution. The prompt provides specific examples: “This sequence results in 1, which is not equal to 22” and “Since 25 is not equal to 22”. Backtracking is defined as instances where the model realizes a path won’t work and explicitly goes back to try a different approach. Subgoal setting is defined as instances where the model breaks down the problem into smaller, intermediate goals. Backward chaining is defined as instances where the model starts from the target solution and works backwards to the initial problems.
我们识别出四种认知行为,这些行为先前已被确立为语言模型推理准确性的贡献因素,使用 Gemini-2.5-Pro 作为 LLM-as-judge 4, 8, 36, 35, 37 。在测量过程中,我们采用了 Gandhi 及其同事(2025 年) 8 使用的提示和示例,该提示已被多位人类评分员验证。每个行为在提示中通过具体示例进行操作化定义,以指导标注:验证被定义为推理链明确将当前结果与目标解进行对比的实例。提示提供了具体示例:“这个序列结果是 1,这不等于 22”和“由于 25 不等于 22”。回溯被定义为模型意识到某条路径行不通,并明确返回尝试不同方法的实例。子目标设定被定义为模型将问题分解为更小、中间目标的实例。反向链被定义为模型从目标解开始,反向推导至初始问题的实例。
For the four cognitive reasoning behaviors, Gemini-2.5-Pro and GPT-5.2 demonstrate good to excellent agreement: Answer Verification (ICC(3,1) = .995), Backtracking (ICC(3,1) = .829), Subgoal Setting (ICC(3,1) = .810), and Backward-Chaining (ICC(3,1) = .756), with a mean ICC of .848. Gemini-2.5-Pro also shows substantial agreement with a human rater across the four cognitive behaviors: Answer Verification (ICC(3,1) = .981), Backtracking (ICC(3,1) = .921), Subgoal Setting (ICC(3,1) = .559), and Backward-Chaining (ICC(3,1) = .578), with a mean ICC of .760. These reliability estimates are computed on 30 reasoning traces to solve general-purpose reasoning problems (see Methods: Data) and 50 reasoning traces generated during reinforcement learning of Qwen-2.5-3B (see Methods: Reinforcement Learning Experiments).
对于四种认知推理行为,Gemini-2.5-Pro 和 GPT-5.2 表现出良好至优秀的一致性:答案验证(ICC(3,1) = .995)、回溯(ICC(3,1) = .829)、子目标设定(ICC(3,1) = .810)和反向链接(ICC(3,1) = .756),平均 ICC 为.848。Gemini-2.5-Pro 在四种认知行为上与人类评分员也显示出显著一致性:答案验证(ICC(3,1) = .981)、回溯(ICC(3,1) = .921)、子目标设定(ICC(3,1) = .559)和反向链接(ICC(3,1) = .578),平均 ICC 为.760。这些可靠性估计基于 30 条推理轨迹来解决通用推理问题(参见方法:数据)以及 50 条在 Qwen-2.5-3B 强化学习过程中生成的推理轨迹(参见方法:强化学习实验)。
Problem Complexity 问题复杂度
We measure problem complexity using two complementary approaches. First, we use LLM-as-judge ratings. Gemini-2.5-Pro rates each problem on a 7-point Likert scale. The prompt instructs the model to rate the intrinsic difficulty of the problem for a capable language model under zero-shot conditions using the following scale: 1 = very easy, 2 = easy, 3 = somewhat easy, 4 = moderate, 5 = somewhat difficult, 6 = difficult, 7 = very difficult. The full prompt is provided in Supplementary Methods: LLM-as-judge prompts. Second, we use empirical error rates. We compute the number of incorrect answers across four instruction-tuned models (DeepSeek-V3, Qwen-2.5-32B-IT, Llama-3.3-70B-IT, Llama-3.1-8B-IT), yielding a score from 0 to 4 representing the number of models that failed to answer correctly. After sampling and annotating 50 reasoning problems, we find substantial inter-rater reliability between Gemini-2.5-Pro and GPT-5.2 (ICC(3,1) = .745). Gemini-2.5-Pro’s complexity scores show strong correlation with non-reasoning models’ error rates (Spearman’s = 0.526, 95% CI = [0.508, 0.543], z = 46.26, p < 1×10-323, N = 7,738), confirming convergent validity between the two measures.
我们使用两种互补的方法来衡量问题复杂度。首先,我们使用 LLM 作为裁判的评分。Gemini-2.5-Pro 对每个问题在 7 点李克特量表上进行评分。提示指令模型在零样本条件下,使用以下量表对有能力语言模型的问题内在难度进行评分:1 = 非常简单,2 = 简单,3 = 比较简单,4 = 中等,5 = 比较困难,6 = 困难,7 = 非常困难。完整的提示指令在补充方法中提供:LLM 作为裁判的提示指令。其次,我们使用经验错误率。我们计算四个指令微调模型(DeepSeek-V3、Qwen-2.5-32B-IT、Llama-3.3-70B-IT、Llama-3.1-8B-IT)的不正确答案数量,得到 0 到 4 的分数,代表未能正确回答的模型数量。在抽样和标注 50 个推理问题后,我们发现 Gemini-2.5-Pro 和 GPT-5.2 之间存在显著的评分者间信度(ICC(3,1) = .745)。Gemini-2.5-Pro 的复杂度评分与非推理模型的错误率显示出强相关性(Spearman’s = 0.526, 95% CI = [0.508, 0.543], z = 46.26, p < 1×10 -323 , N = 7,738),证实了这两种测量方法之间的收敛效度。
Statistical Analyses 统计分析
To estimate whether observed differences between reasoning models (DeepSeek-R1 and QwQ-32B) and instruction-tuned baselines arise from conversational behaviours or socio-emotional roles rather than from task heterogeneity or reasoning trace length, we estimate the following linear probability model for each behavioural outcome Yij, which is a binary variable.
为了估计推理模型(DeepSeek-R1 和 QwQ-32B)与指令微调基线之间观察到的差异是否源于对话行为或社会情感角色,而非任务异质性或推理轨迹长度,我们为每个行为结果 Y ij 估计以下线性概率模型,该变量为二元变量。
where i indexes individual task problems, and j indexes individual reasoning traces generated by different models. Yij equals 1 if the reasoning trace j exhibits the behavior more than once. is a categorical dummy variable that equals 1 if reasoning trace j for problem i is generated by model m, and 0 otherwise, where
Either DeepSeek-V3 or Qwen-2.5-32B-IT serves as the reference category and is excluded, such that each coefficient m represents the marginal difference in the outcome relative to DeepSeek-V3 or Qwen-2.5-32B-IT. Log(Lenij) denotes the reasoning trace length (i.e., the number of words in each reasoning trace), adjusting the extreme skewness of reasoning trace length (see Extended Data Fig. 1). represents task fixed effects at the individual problem level, absorbing all variation associated with each problem’s intrinsic difficulty, phrasing, and topical content. This ensures that comparisons between models are made within the same problem rather than across heterogeneous tasks. is the intercept. Robust standard errors are clustered at the task level to account for within-task correlation. Models are estimated using StataNow/SE 19.5.
其中,index 表示个体任务问题,index 表示由不同模型生成的个体推理轨迹。如果推理轨迹表现出该行为超过一次,则 Y ij 等于 1。 是一个分类虚拟变量,如果问题由模型 m 生成推理轨迹,则等于 1,否则等于 0,其中 DeepSeek-V3 或 Qwen-2.5-32B-IT 作为参考类别并被排除,因此每个系数 m 表示相对于 DeepSeek-V3 或 Qwen-2.5-32B-IT 的结果边际差异。Log(Len ij )表示推理轨迹长度(即每个推理轨迹中的词数),调整推理轨迹长度的极端偏度(参见扩展数据图 1)。 表示个体问题层面的任务固定效应,吸收了与每个问题的内在难度、措辞和主题内容相关的所有变化。这确保了模型之间的比较是在相同的问题内部进行的,而不是跨异构任务。 是截距。稳健标准误在任务层面聚类,以考虑任务内相关性。模型使用 StataNow/SE 19.5 进行估计。
SAE Feature Steering SAE 特征引导
To investigate the role of conversational behaviours in reasoning, we employ sparse autoencoders (SAEs) to identify and manipulate interpretable features in the model’s activation space. SAEs decompose neural network activations into a sparse set of linear features, enabling targeted intervention on specific behavioural dimensions without altering model weights56, 57, 58.We use an SAE trained on Layer 15’s residual stream activations of DeepSeek-R1-Llama-8B (15-llamascope-slimpj-res-32k). The SAE has been trained on SlimPajama, a general-purpose corpus containing both conversational and non-conversational texts, with a dictionary size of 32,768 features (see Supplementary Table 3 for hyperparameters).
为了研究对话行为在推理中的作用,我们采用稀疏自动编码器(SAEs)来识别和操控模型激活空间中的可解释特征。SAEs 将神经网络激活分解为稀疏的线性特征集,从而能够在不改变模型权重的情况下,针对特定行为维度进行定向干预 56, 57, 58 。我们使用一个在 DeepSeek-R1-Llama-8B(15-llamascope-slimpj-res-32k)第 15 层残差流激活上训练的 SAE。该 SAE 在 SlimPajama 上训练,这是一个包含对话和非对话文本的通用语料库,字典大小为 32,768 个特征(超参数见补充表 3)。
To identify features associated with conversational contexts, we follow a standard interpretability pipeline. For each of the 32,768 features, we sample approximately 50 contexts from the pre-training corpus where the feature activates most strongly. We then use an LLM-as-judge classifier (Gemini-2.5-flash-lite) to determine whether each activation context represents a conversational setting, computing a conversation ratio for each feature—the proportion of activations occurring in conversational contexts. We apply two filtering criteria: (1) conversation ratio above 50%, and (2) activation near sentence onsets 50% or more (within the first four tokens). From the candidate features, we select Feature 30939, which the LLM judge summarized as “a discourse marker for surprise, realization, or acknowledgment.” This feature activates on tokens such as “Oh!” in contexts involving turn-taking and social exchange. Feature 30939 exhibits a conversation ratio of 65.7% (99th percentile among all features) while maintaining high sparsity (0.016% of tokens), indicating specificity to conversational phenomena rather than general linguistic patterns.
为了识别与对话环境相关的特征,我们遵循标准的可解释性流程。对于 32,768 个特征中的每一个,我们从预训练语料库中抽取大约 50 个特征激活最强烈的上下文。然后,我们使用 LLM 作为裁判的分类器(Gemini-2.5-flash-lite)来确定每个激活上下文是否代表对话环境,并计算每个特征的对话比例——即激活发生在对话环境中的比例。我们应用了两个过滤标准:(1) 对话比例超过 50%,(2) 激活靠近句子起始位置 50%或更多(在前四个 token 内)。从候选特征中,我们选择了特征 30939,LLM 裁判将其总结为“用于表示惊讶、意识到或确认的语篇标记”。该特征在涉及轮流发言和社会交换的上下文中激活,例如在“哦!”这样的 token 上。特征 30939 的对话比例为 65.7%(所有特征中第 99 个百分位数),同时保持高稀疏性(0.016%的 token),表明其特异性针对对话现象而非一般语言模式。
We implement activation addition to steer Feature 30939 during generation. At each token generation step, we add the feature’s decoder vector, scaled by a steering strength s, to the model’s Layer 15 residual stream activations.
我们实现激活相加来引导 Feature 30939 在生成过程中。在每个 token 生成步骤中,我们将该特征的解码向量,乘以引导强度 s,加到模型的 Layer 15 残差流激活上。
where denotes the original activation at token position t and d30939 denotes the decoder vector for Feature 30939. We first generate reasoning traces under seven steering conditions: . As exhibits lower accuracy due to excessive steering, we use .
其中 表示在 token 位置 t 处的原始激活,d 30939 表示 Feature 30939 的解码向量。我们首先在七种引导条件下生成推理轨迹: 。由于 由于过度引导导致准确率较低,我们使用 。
Reasoning Task and Evaluation
推理任务与评估
We evaluate reasoning performance using the Countdown task, a benchmark for multi-step arithmetic reasoning commonly used to evaluate LLM reasoning capabilities. In each problem, the model must combine a set of input numbers using basic arithmetic operations (+, , ×, ÷) and parentheses to reach a target value. For example, given inputs {25, 30, 3, 4} and target 32, a valid solution is (30 25 + 3) × 4 = 32. We use 1,024 problems. We use the following prompt template: Using the numbers [79, 17, 60], create an equation that equals 36. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>. Solutions are scored as correct if the final numerical answer matches the target value, evaluated using Gemini-2.5-flash-lite.
我们使用倒计时任务评估推理性能,这是一个常用于评估 LLM 推理能力的多步算术推理基准。在每个问题中,模型必须使用基本的算术运算(+、-、×、÷)和括号组合一组输入数字,以达到目标值。例如,给定输入{25, 30, 3, 4}和目标值 32,一个有效的解决方案是(30 - 25 + 3) × 4 = 32。我们使用了 1,024 个问题。我们使用以下提示模板:使用数字[79, 17, 60],创建一个等于 36 的等式。你可以使用基本的算术运算(+、-、*、/),每个数字只能使用一次。在 标签中展示你的解题过程。并在 标签中返回最终答案,例如 (1 + 2) / 3 。如果最终数值答案与目标值匹配,则评分正确,使用 Gemini-2.5-flash-lite 进行评估。
After steering, we measure the frequency of conversational behaviours (question–answering, perspective shift, conflict of perspectives, reconciliation) and cognitive behaviours (verification, backtracking, subgoal setting, backward chaining) in each generated reasoning trace using the LLM-as-judge procedures described above. To estimate behavioural differences across steering conditions, we estimate fixed-effects linear regression models for each behavioural count variable
在引导之后,我们使用上述描述的将 LLM 作为评判者的方法,测量每个生成的推理轨迹中对话行为(问答、视角转换、视角冲突、和解)和认知行为(验证、回溯、子目标设定、反向链接)的频率。为了估计不同引导条件下的行为差异,我们为每个行为计数变量估计固定效应线性回归模型
where i indexes individual task problems, and j indexes individual reasoning traces generated before or after steering. is a categorical variable indicating steering strength. denotes the log-transformed reasoning trace length (i.e., the number of words in each reasoning trace), adjusting the extreme skewness of reasoning trace length (see Extended Data Fig. 1). represents task fixed effects at the individual problem level, absorbing all variation associated with each problem’s intrinsic difficulty.
其中下标索引个体任务问题,下标索引引导前或引导后生成的个体推理轨迹。 是一个表示引导强度的分类变量。 表示推理轨迹长度的对数转换(即每个推理轨迹中的字数),以调整推理轨迹长度的极端偏斜性(参见扩展数据图 1)。 表示个体问题层面的任务固定效应,吸收了与每个问题内在难度相关的所有变化。
Experiment Conditions 实验条件
To assess whether accuracy improvements are specific to conversational features rather than a general property of SAE steering, we compare three conditions: (1) Feature 30939 (conversational surprise), (2) randomly selected conversational features (conversation ratio above mean and activating near sentence onset), and (3) randomly selected non-conversational features (conversation ratio below mean). For condition (1), we evaluate all 1,024 Countdown problems. For conditions (2) and (3), we randomly sample 300 features from each category and have each feature solve 16 randomly selected problems, yielding a distribution of accuracy scores across features within each condition. For all conditions, steering strength is set to twice the maximum activation strength observed for that feature across sampled instances in SlimPajama-3B. We test for differences in accuracy between conditions using linear regression with problem fixed effects.
为了评估准确性提升是否特定于对话特征,而非 SAE 转向的一般属性,我们比较了三种条件:(1) 特征 30939(对话意外性),(2) 随机选择的对话特征(对话比例高于平均值且在句子起始处激活),以及(3) 随机选择的非对话特征(对话比例低于平均值)。对于条件(1),我们评估了所有 1,024 个 Countdown 问题。对于条件(2)和(3),我们从每个类别中随机抽取 300 个特征,每个特征解决 16 个随机选择的问题,从而得到每个条件下特征准确性分数的分布。对于所有条件,转向强度设置为 SlimPajama-3B 中该特征在抽样实例中观察到的最大激活强度的两倍。我们使用带有问题固定效应的线性回归来测试条件间准确性的差异。
Feature Diversity 特征多样性
To examine whether steering conversational features induces greater activation of personality- and expertise-related features in the model’s internal representation space, we analyze sparse autoencoder (SAE) feature activations before and after steering. We use the same SAE employed in the steering experiments: an SAE trained on Layer 15’s residual stream activations of DeepSeek-R1-Llama-8B with a dictionary size of 32,768 features. For each reasoning trace generated under different steering conditions (s
{10, 0, +10}), we record which SAE features are activated at each token position by passing the Layer 15 activations through the SAE encoder.
为了检验引导对话特征是否能在模型的内部表征空间中引发更强烈的性格和专业知识相关特征的激活,我们分析了引导前后稀疏自动编码器(SAE)特征激活情况。我们使用了引导实验中相同的 SAE:一个在 DeepSeek-R1-Llama-8B 第 15 层残差流激活上训练的 SAE,字典大小为 32,768 个特征。对于在不同引导条件下(s { 10, 0, +10})生成的每个推理轨迹,我们通过将第 15 层激活传递给 SAE 编码器,记录在每个词位置上哪些 SAE 特征被激活。
For each of the 32,768 SAE features, Neuronpedia provides a textual description generated by prompting GPT-4o-mini with the top-activating token sequences. Using Gemini-2.5-flash-lite, we classify each feature description into one of three categories: personality-related, expertise-related, or other. Gemini-2.5-flash-lite first scores each feature from 0 to 100 based on whether it is related to personality traits or domain expertise (see Supplementary Methods: LLM-as-judge prompts). Then, we use the threshold of 50 to determine whether they are personality or expertise features. Among the 32,768 features, 5,455 are labeled as personality-related (e.g., eagerness, expressions of frustration) and 15,436 as expertise-related (e.g., programming terminology, financial concepts).
对于每个 32,768 个 SAE 特征,Neuronpedia 通过用 GPT-4o-mini 提示的 top-激活的 token 序列生成文本描述。使用 Gemini-2.5-flash-lite,我们将每个特征描述分类为性格相关、专业相关或其他三类。Gemini-2.5-flash-lite 首先根据其是否与性格特征或领域专业知识相关,对每个特征进行 0 到 100 的评分(参见补充方法:LLM 作为裁判的提示)。然后,我们使用 50 的阈值来确定它们是性格特征还是专业知识特征。在 32,768 个特征中,5,455 个被标记为性格相关(例如,渴望、沮丧的表达),15,436 个被标记为专业相关(例如,编程术语、金融概念)。
For each reasoning trace, we compute two complementary measures of feature diversity within each category (personality-related or expertise-related). First, coverage is defined as the number of unique features within a category (personality or expertise) that exhibit non-zero activation across all tokens in a reasoning trace. Second, entropy is computed over the distribution of token counts that activate each SAE feature within a given category. Each reasoning trace is represented as a 32,768-dimensional vector, where each element corresponds to the number of tokens within the reasoning trace that activated a specific SAE feature. Entropy H for category c (personality or expertise) was then calculated as:
对于每条推理轨迹,我们在每个类别(与个性相关或与专业相关)中计算两个互补的特征多样性度量。首先,覆盖度被定义为在推理轨迹的所有标记中表现出非零激活的唯一特征数量(个性或专业类别)。其次,在给定类别中计算每个 SAE 特征激活的标记计数分布的熵。每条推理轨迹表示为一个 32,768 维的向量,其中每个元素对应于推理轨迹中激活特定 SAE 特征的标记数量。然后计算类别 c(个性或专业)的熵 H,计算公式如下:
where denotes the number of activating tokens for feature within category .
其中 表示在类别 中特征 的激活标记数量。
Higher coverage indicates that the reasoning trace draws on a broader range of personality- or expertise-related features. Higher entropy indicates that activations are more evenly distributed across features rather than concentrated in a few dominant ones. For instance, a reasoning trace with high coverage but low entropy explores diverse features but focuses primarily on a small subset, whereas high coverage and high entropy suggest that reasoning draws on multiple feature types more evenly throughout the reasoning process.
覆盖率更高表明推理轨迹利用了更广泛的人格或专业相关的特征。熵值更高表明激活在特征之间分布更均匀,而不是集中在少数几个主导特征上。例如,一个覆盖率较高但熵值较低的推理轨迹探索了多样化的特征,但主要关注一小部分特征,而高覆盖率和高熵值则表明推理在整个推理过程中更均匀地利用了多种特征类型。
To examine the effect of conversational steering on feature diversity, we compare coverage and entropy across steering conditions (s {10, 0, +10}) for the same 1,024 Countdown problems. We estimate fixed-effects linear regression models with coverage or entropy as the outcome, steering strength as the predictor, and controls for log-transformed reasoning trace length and problem fixed effects. This specification isolates the effect of steering on feature diversity beyond mere changes in output length.
为了检验对话引导对特征多样性的影响,我们比较了相同 1,024 个 Countdown 问题在不同引导条件下(s { 10, 0, +10})的覆盖率和熵值。我们估计了以覆盖率为因变量、引导强度为预测变量、并控制了对数转换的推理轨迹长度和问题固定效应的固定效应线性回归模型。这种设定隔离了引导对特征多样性的影响,而不仅仅是输出长度的变化。
Implicit Perspectives 隐含视角
To quantify the diversity of reasoning perspectives within each reasoning trace, we use an LLM-as-judge protocol (Gemini-2.5-Pro) that performs three sequential tasks: (1) inferring the number of distinct perspectives present in the reasoning trace, (2) characterizing each perspective’s personality traits and domain expertise, and (3) segmenting the reasoning trace by attributing each portion to a specific perspective.
为了量化每个推理轨迹中推理视角的多样性,我们使用一个 LLM 作为裁判的协议(Gemini-2.5-Pro),该协议执行三个连续的任务:(1) 推断推理轨迹中存在的不同视角的数量,(2) 描述每个视角的性格特征和领域专业知识,以及(3) 通过将每个部分归因于特定视角来分割推理轨迹。
Given a complete reasoning trace, the LLM-as-judge first infers the number of distinct perspectives present. Then, for each identified perspective, the LLM-as-judge answers the 10 items of the BFI-10 (Ten-Item Big Five Inventory)64 as if responding from that perspective’s point of view. Each item (“is generally trusting”, “tends to be lazy”, “is relaxed”, “handles stress well”, “has few artistic interests”, “is outgoing”, “is sociable”, “tends to find fault with others”, “does a thorough job”, “gets nervous easily”, and “has an active imagination,”) is rated on a five-point scale from “Disagree strongly” to “Agree strongly.” Scores for each of the five personality dimensions (Extraversion, Agreeableness, Conscientiousness, Neuroticism, Openness) are computed as the mean of the two corresponding items, with reverse-coding applied where appropriate. Additionally, the LLM-as-judge generates a concise free-form description of each perspective’s domain expertise (e.g., “Theoretical Physicist specializing in model abstraction,” “Software Engineer focusing on algorithmic efficiency”).
给定一个完整的推理轨迹,作为裁判的 LLM 首先推断出其中存在的不同视角数量。然后,对于每个已识别的视角,作为裁判的 LLM 会从该视角的观点出发,回答 BFI-10(五因素人格量表 10 项版本)的 10 个项目。每个项目(“通常很信任人”、“倾向于懒惰”、“很放松”、“能很好地应对压力”、“很少有艺术兴趣”、“很外向”、“很合群”、“倾向于找别人的错”、“工作很彻底”、“容易紧张”、“想象力很活跃”)都在一个五点量表上评分,从“强烈不同意”到“强烈同意”。每个五个人格维度(外向性、宜人性、责任心、神经质、开放性)的得分计算为对应两个项目的平均分,并在必要时进行反向编码。此外,作为裁判的 LLM 会为每个视角的领域专业知识生成一个简洁的自由形式描述(例如,“专攻模型抽象的理论物理学家”、“专注于算法效率的软件工程师”)。
Finally, the LLM-as-judge attributes each segment of the reasoning trace to one of the identified perspectives, producing a mapping that indicates which perspective generated each portion of the text. The full prompts, which elicit all three outputs in a single structured JSON response, are provided in Supplementary Methods: LLM-as-judge prompts.
最后,作为裁判的 LLM 将推理轨迹的每个片段分配给已识别的某个视角,生成一个映射,表明哪个视角生成了文本的每个部分。完整提示,它们在单个结构化 JSON 响应中引出所有三个输出,在补充方法中提供:作为裁判的 LLM 提示。
Personality Diversity 人格多样性
To quantify personality diversity within a reasoning trace, we calculate the standard deviation of the five-dimensional personality vectors across implicit voices identified within the same reasoning trace. Let vij denote the score of the i-th implicit voice on the -th personality dimension ( = 1 , … , 5). For each dimension , the within-trace personality diversity Pj was computed as:
为了量化推理轨迹中的人格多样性,我们计算在同一推理轨迹中识别出的隐式声音在五个维度上的人格向量的标准差。令 v ij ^( ) 表示第 ij 个隐式声音在第 个人格维度上的得分( = 1, …, 5)。对于每个维度 ,轨迹内人格多样性 P 计算为:
where N is the number of implicit voices and is the mean score for dimension j. If a reasoning trace contained only a single implicit voice, .
其中 N 是隐式声音的数量, 是维度的平均得分。如果推理轨迹只包含一个隐式声音,则 。
Expertise Diversity 专长多样性
Each implicit reasoning voice’s expertise is qualitatively profiled through a concise textual description summarizing the domain expertise. Each statement was embedded using Google’s EmbeddingGemma-300M model to obtain a semantic vector representation ei for the i-th implicit voice (i=1, …, N)73. To quantify expertise diversity within a reasoning trace, we compute the mean cosine distance between each embedding and the centroid of all embeddings in the semantic space. Expertise diversity E was defined as:
每个隐式推理声音的专长通过一个简洁的文本描述来定性分析,该描述总结了领域专长。每个陈述都使用 Google 的 EmbeddingGemma-300M 模型嵌入,以获得第 i 个隐式声音(i=1, …, N)的语义向量表示 e 73 。为了量化推理轨迹中的专长多样性,我们计算每个嵌入与语义空间中所有嵌入的质心之间的平均余弦距离。专长多样性 E 定义为:
where denotes the inner product between embeddings and their vector norms. If a reasoning trace contained only a single implicit voice, .
其中 表示嵌入之间的内积, 表示它们的向量范数。如果推理轨迹中只包含一个隐式声音,则 。
Validation 验证
To validate the accuracy of the LLM-as-judge protocol, we use the Intelligence Squared Debates Corpus—a dataset of human argumentative conversations (N = 1,196 conversations) among two to eight participants with known ground-truth speaker labels and biographical information. To ensure that the model cannot rely on superficial cues such as speaker tags or formatting, we remove all speaker labels and concatenate each dialogue into a single block of text, mimicking the format of LLM reasoning traces. As shown in Extended Data Fig. 5, we find that the LLM-as-judge can accurately predict the number of distinct individuals (Spearman’s = 0.86, 95% CI = [0.84, 0.87], z = 44.7, p < 1×10-323) and the number of distinct turns underlying each conversation (Spearman’s = 0.89, 95% CI = [0.88, 0.90], z = 49.2, p < 1×10-323).
为验证 LLM 作为评判者协议的准确性,我们使用了 Intelligence Squared 辩论语料库——一个包含人类辩论对话的数据集(N = 1,196 次对话),对话参与者为两到八人,具有已知的真实说话者标签和生平信息。为确保模型不能依赖说话者标签或格式等表面线索,我们移除了所有说话者标签,并将每个对话连接成一个文本块,模拟 LLM 推理轨迹的格式。如图 5 所示,我们发现 LLM 作为评判者能够准确预测对话中不同个体的数量(Spearman’s = 0.86, 95% CI = [0.84, 0.87], z = 44.7, p < 1×10 -323 )以及每个对话背后不同发言的数量(Spearman’s = 0.89, 95% CI = [0.88, 0.90], z = 49.2, p < 1×10 -323 )。
To evaluate token-level speaker attribution accuracy, we construct ground truth by assigning each token to its true speaker based on the original transcript. We then extract the model’s predicted perspective segments and align them to the token stream. To match predicted perspective IDs (e.g., Perspective 1, Perspective 2) with the original speaker labels, we apply the Hungarian algorithm—a combinatorial optimization method that finds the one-to-one assignment between predicted IDs and true speakers that maximizes total token-level agreement. Speaker-level accuracy measures the proportion of tokens assigned to the correct speaker under this optimal mapping. When there are two speakers, accuracy is 82%; for three speakers, 76%; and for four speakers, 69%. Weighted by the distribution of predicted perspectives in LLM reasoning traces, overall accuracy is 73%.
为了评估词元级别的说话人归属准确率,我们通过根据原始文本将每个词元分配给其真正的说话人来构建真实标签。然后我们提取模型的预测视角片段,并将其与词元流对齐。为了将预测的视角 ID(例如,视角 1、视角 2)与原始说话人标签匹配,我们应用匈牙利算法——这是一种组合优化方法,它找到预测 ID 和真实说话人之间的一对一分配,以最大化总词元级别的匹配度。说话人级别的准确率衡量在最优映射下分配给正确说话人的词元比例。当有两个说话人时,准确率是 82%;有三个说话人时,76%;有四个说话人时,69%。根据 LLM 推理轨迹中预测视角的分布进行加权,总体准确率是 73%。
Because the Intelligence Squared Debates Corpus includes biographical information about debate participants, we further verify that expertise diversity inferred by the LLM-as-judge correlates with actual diversity among participants’ ground-truth biographies. We compute expertise diversity from LLM-inferred descriptions and compare it to diversity computed from true biographies, finding significant correspondence (Spearman’s = 0.55, 95% CI = [0.51, 0.59], z = 21.4, p < 1×10-97).
由于 Intelligence Squared 辩论语料库包含了辩论参与者的传记信息,我们进一步验证了由 LLM 作为评判者所推断的专业知识多样性是否与参与者真实传记中的多样性相关。我们从 LLM 推断的描述中计算专业知识多样性,并将其与从真实传记中计算的多样性进行比较,发现存在显著对应关系(Spearman’s = 0.55, 95% CI = [0.51, 0.59], z = 21.4, p < 1×10 -97 )。
We further examine whether measurements based on LLM-as-judge are aligned with the measurements we get from SAE regarding personality and expertise diversity. Specifically, we feed reasoning traces from DeepSeek-R1, DeepSeek-v3, Llama-3.3-70B-IT, and Llama-3.1-8B-IT into Llama-3.1-8B-IT and extract activations from a SAE trained on its residual stream (Layer 16). We then identify personality-related and expertise-related features using the same LLM-as-judge prompting procedure described above. Extended Data Fig. 6 shows that DeepSeek-R1’s reasoning traces activate significantly more diverse personality and expertise features than those of other models: both coverage (number of unique features activated) and entropy (distribution evenness across features) are substantially higher for DeepSeek-R1. This suggests the convergence between text-level behavioural coding and activation-level feature analysis.
我们进一步检验基于 LLM 作为评判者的测量是否与 SAE 在性格和专业知识多样性方面得到的测量相一致。具体来说,我们将 DeepSeek-R1、DeepSeek-v3、Llama-3.3-70B-IT 和 Llama-3.1-8B-IT 的推理轨迹输入到 Llama-3.1-8B-IT 中,并从在其残差流上训练的 SAE(第 16 层)中提取激活。然后,我们使用上述相同的 LLM 作为评判者的提示程序来识别与性格相关的和与专业知识相关的特征。扩展数据图 6 显示 DeepSeek-R1 的推理轨迹激活了比其他模型显著更多样化的性格和专业知识特征:DeepSeek-R1 的覆盖度(被激活的独特特征数量)和熵(特征分布的均匀性)都明显更高。这表明文本级别的行为编码与激活级别的特征分析之间存在收敛。
Reinforcement Learning Experiments
强化学习实验
Countdown Task Prompt 倒计时任务提示
We use the following prompt template: Using the numbers [79, 17, 60], create an equation that equals 36. You can use basic arithmetic operations (+, -, *, /) and each number can only be used once. Show your work in <think> </think> tags. And return the final answer in <answer> </answer> tags, for example <answer> (1 + 2) / 3 </answer>.
我们使用以下提示模板:使用数字[79, 17, 60],创建一个等于 36 的方程。你可以使用基本的算术运算(+, -, *, /),并且每个数字只能使用一次。在<think> </think>标签中展示你的解题过程。最后在<answer> </answer>标签中返回最终答案,例如<answer> (1 + 2) / 3 </answer>。
Experimental Conditions 实验条件
To test whether conversational scaffolding accelerates the emergence of reasoning during reinforcement learning (RL), we compare three conditions:
为了测试对话支架是否能够加速在强化学习(RL)过程中推理能力的出现,我们比较了三种条件:
-
1.
Baseline (RL only): The base model (Qwen-2.5-3B or Llama-3.2-3B) undergoes RL training without any prior fine-tuning. The model is prompted to solve Countdown problems with chain-of-thought reasoning, wrapping its reasoning in <think>…</think> tags and its final answer in <answer>…</answer> tags.
1. 基线(RL 仅):基础模型(Qwen-2.5-3B 或 Llama-3.2-3B)未经任何先验微调直接进行 RL 训练。模型被提示使用思维链推理解决 Countdown 问题,将其推理过程包裹在<think>…</think>标签中,最终答案包裹在<answer>…</answer>标签中。 -
2.
Conversation fine-tuning: The base model is first supervised-fine-tuned on multi-agent dialogue data before RL training.
2. 对话微调:基础模型首先在多智能体对话数据上进行监督微调,然后再进行强化学习训练。 -
3.
Monologue fine-tuning: The base model is first supervised-fine-tuned on single-agent chain-of-thought traces before RL training.
3. 独白微调:基础模型首先在单智能体思维链轨迹上进行监督微调,然后再进行强化学习训练。
Supervised Fine-Tuning Datasets
监督微调数据集
We construct fine-tuning datasets using Qwen-2.5-32B-IT as generator. We generate 3,600 multi-agent dialogues for Countdown problems, with 1,200 dialogues each for two-agent, three-agent, and four-agent settings. From these, we sample 600 dialogues that reach correct final solutions (200 each for 2-agent, 3-agent, and 4-agent settings; 500 for training, 100 for validation). See Supplementary Methods: SFT data generation prompts.
我们使用 Qwen-2.5-32B-IT 作为生成器构建微调数据集。我们生成了 3,600 个用于倒计时问题的多智能体对话,其中两智能体、三智能体和四智能体设置各 1,200 个对话。从这些对话中,我们抽取了 600 个达到正确最终解的对话(两智能体、三智能体和四智能体设置各 200 个;500 个用于训练,100 个用于验证)。参见补充方法:SFT 数据生成提示。
Conversation Dataset 对话数据集
Each conversational trace begins with persona definitions specifying distinct personality traits and expertise, followed by turn-taking reasoning where personas build on, question, and correct each other, and concludes with a group consensus. For example:
每个对话轨迹以角色定义开始,这些定义指定了不同的性格特征和专业知识,接着是轮流推理的过程,其中角色相互补充、提问和纠正,最后达成群体共识。例如:
<persona1> Extrovert mathematician focused on arithmetic heuristics. </persona1>
<persona1> 外向的数学家,专注于算术启发式方法。 </persona1><persona2> Analytical engineer emphasizing step efficiency. </persona2>
<persona2> 注重步骤效率的分析工程师。 </persona2><think1> Let’s first compute 30 25 = 5 to simplify the target space. </think1>
让我们先计算 30 25 = 5 以简化目标空间。 <think2> That yields 5, we can now multiply by 4 to approach 20. </think2>
<think2> 得到 5,我们现在可以乘以 4 来接近 20。 </think2><think1> Good idea. 5 × 4 = 20, but we need 32. </think1>
<think1> 好主意。 5 × 4 = 20,但我们需要 32。 </think1><think2> Wait, let me recalculate… </think2>
<think2> 等一下,让我重新计算…… </think2><group_consensus> The best sequence is (30 25 + 3) × 4 = 32. </group_consensus>
最佳序列是 (30 25 + 3) × 4 = 32。
Monologue Dataset 独白数据集
For the same 600 problems used in the conversation dataset, we generate standard single-agent chain-of-thought traces that reach correct answers. Each trace consists of step-by-step reasoning from a single voice within <think>…</think> tags, followed by a final answer. For example:
对于与对话数据集相同的 600 个问题,我们生成了达到正确答案的标准单智能体思维链轨迹。每个轨迹由 <think>…</think> 标签内的逐步推理组成,随后是最终答案。例如:
<think> To reach 32 from {25, 30, 3, 4}, I’ll try combining operations.
<think> 要从 {25, 30, 3, 4} 得到 32,我将尝试组合运算。30 25 = 5. Then 5 + 3 = 8. Finally, 8 × 4 = 32.
30 25 = 5。然后 5 + 3 = 8。最后,8 × 4 = 32。Let me verify: (30 25 + 3) × 4 = 8 × 4 = 32. Correct. </think>
让我验证一下:(30 25 + 3) × 4 = 8 × 4 = 32。正确。<answer> (30 25 + 3) × 4 = 32 </answer>
Crucially, both datasets contain solutions to identical problems with identical correct answers, ensuring that any performance difference reflects the reasoning format rather than exposure to different solutions or task knowledge.
关键在于,这两个数据集都包含了相同问题的相同正确答案的解决方案,这确保了任何性能差异都反映了推理格式,而不是接触了不同的解决方案或任务知识。
Supervised Fine-Tuning Procedure
监督微调流程
Qwen-2.5-3B base model is supervised-fine-tuned on one of the two datasets using standard next-token prediction loss. Models learn to reproduce the full output sequence—including persona definitions and turn-by-turn reasoning (for conversation) or single-agent reasoning (for monologue), and final answer—given only the problem prompt as input. This priming phase familiarizes the model with conversation-like or monologue-like reasoning before RL optimizes for task accuracy. SFT hyperparameters are provided in Supplementary Table 8. See Supplementary Methods: Replications on Llama-3.2-3B for details on replicating these results in another model. Full generation prompts are provided in Supplementary Methods: Prompts.
Qwen-2.5-3B 基础模型使用标准下一词预测损失在两个数据集之一上进行监督微调。模型学习在仅给定问题提示作为输入的情况下,重现完整输出序列——包括角色定义和逐回合推理(用于对话)或单智能体推理(用于独白),以及最终答案。这个初始化阶段使模型熟悉类似对话或类似独白的推理,然后再通过强化学习优化任务准确率。SFT 超参数在补充表格 8 中提供。有关在另一模型中复制这些结果的详细信息,请参阅补充方法:Llama-3.2-3B 上的复制。完整生成提示在补充方法:提示中提供。
Reinforcement Learning Procedure
强化学习流程
Reinforcement learning is performed on the Countdown arithmetic puzzle, using PPO (Proximal Policy Optimization) with the Verl framework68. While DeepSeek-R1 uses a simplified version of PPO68 called GRPO (Group Relative Policy Optimization)74, we utilize PPO for the superior stability across hyperparameters8. Preliminary analyses showed no significant difference in learning performance between PPO and GRPO (see Supplementary Methods: Performance comparison between PPO and GRPO). Reward R is assigned as:
在倒计时算术谜题上进行了强化学习,使用 PPO(近端策略优化)与 Verl 框架 68 。虽然 DeepSeek-R1 使用 PPO 的简化版本 68 ,称为 GRPO(组相对策略优化) 74 ,但我们利用 PPO 以获得超参数的更优稳定性 8 。初步分析显示 PPO 和 GRPO 在学习性能上没有显著差异(参见补充方法:PPO 与 GRPO 的性能比较)。奖励 R 分配如下:
Reasoning trace leads to the correct answer and 0 otherwise. Format is also binary, coded as 1 if the reasoning trace contains at least one reasoning block (<think> </think>) and one final answer block ( <answer> </answer>) providing a single answer in equation form, and 0 otherwise. Crucially, we do not directly reward conversational or cognitive behaviours. Training proceeds for 250 steps. PPO hyperparameters are provided in Supplementary Table 6.
推理轨迹得出正确答案时为 1,否则为 0。格式也是二元的,如果推理轨迹中至少包含一个推理块(<think> </think>)和一个最终答案块(<answer> </answer>),且该答案块以方程形式给出单一答案,则为 1,否则为 0。关键在于,我们不直接奖励对话行为或认知行为。训练进行 250 步。PPO 超参数见表格 6。
To examine whether conversational behaviours emerge spontaneously during RL despite not being directly rewarded, we evaluate model performance on a held-out validation set of 1,024 Countdown problems at each training checkpoint (every 10 steps). For each checkpoint, we generate reasoning traces for all validation problems and measure both accuracy and the frequency of conversational behaviours (question–answering, perspective shift, conflict of perspectives, reconciliation) using the LLM-as-judge procedure described in Methods: Conversational behaviours.
为了检验在强化学习过程中,即使对话行为没有被直接奖励,是否也会自发出现,我们在每个训练检查点(每 10 步)评估模型在一个包含 1024 个 Countdown 问题的验证集上的表现。对于每个检查点,我们为所有验证问题生成推理轨迹,并使用方法中描述的将 LLM 作为评判者的程序来测量准确率以及对话行为的频率(问答、视角转换、视角冲突、和解)。
Acknowledgements 致谢
We are grateful to members of the Paradigms of Intelligence at Google and the Knowledge Lab at the University of Chicago for helpful comments throughout the research process. Extensive comments from Blake Richards, Roberta Rocca, and Rif A. Saurous were particularly helpful for improving the work. This work was completed in part with computing resources provided by the University of Chicago’s Research Computing Center and Data Science Institute.
我们感谢 Google 的智能范式小组成员和芝加哥大学的知识实验室在整个研究过程中提供的有益评论。Blake Richards、Roberta Rocca 和 Rif A. Saurous 的详细评论对改进工作特别有帮助。这项工作部分由芝加哥大学研究计算中心和数据科学研究所提供的计算资源完成。
Author Contributions 作者贡献
J.K., J.E., and N.S. collaboratively conceived and designed the study and the experiment setup. J.K., S.L., N.S., and J.E. drafted, revised, and edited the manuscript. J.K. and S.L. gathered and cleaned the data and performed the analysis. J.K. and J.E. produced the visualizations.
J.K.、J.E.和 N.S.共同构思和设计了研究及实验设置。J.K.、S.L.、N.S.和 J.E.起草、修订和编辑了稿件。J.K.和 S.L.收集和清理了数据并进行了分析。J.K.和 J.E.制作了可视化图表。
Competing Interests 利益冲突
J.K., N.S., B.A., J.E. are employed by Google. S.L. declares no competing interests.
J.K.、N.S.、B.A.、J.E.受雇于谷歌。S.L.声明没有利益冲突。
References
- 1 Brown, T. B. et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, Vol. 33, 1877–1901 (2020).
- 2 Wei, J. et al. Emergent abilities of large language models. Transactions on Machine Learning Research (2022).
- 3 OpenAI. Learning to reason with LLMs. https://openai.com/index/learning-to-reason-with-llms/ (2024). Accessed: 2025-11-7.
- 4 Guo, D. et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature 645, 633–638 (2025).
- 5 Snell, C., Lee, J., Xu, K. & Kumar, A. Scaling LLM test-time compute optimally can be more effective than scaling model parameters. The Thirteenth International Conference on Learning Representations, Vol. 2025, 10131–10165 (2025).
- 6 Kim, J., Evans, J. & Schein, A. Linear representations of political perspective emerge in large language models. The Thirteenth International Conference on Learning Representations, Vol. 2025, 7180–7211 (2025).
- 7 Bricken, T. et al. Towards monosemanticity: Decomposing language models with dictionary learning. https://transformer-circuits.pub/2023/monosemantic-features/index.html (2026). Accessed: 2026-1-5.
- 8 Gandhi, K., Chakravarthy, A., Singh, A., Lile, N. & Goodman, N. D. Cognitive behaviors that enable self-improving reasoners, or, four habits of highly effective STaRs. Proceedings of the 2nd Conference on Language Modeling (2025).
- 9 Yao, S. et al. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, Vol. 36, 11809–11822 (2023).
- 10 Mercier, H. & Sperber, D. The Enigma of Reason (Harvard University Press, 2017).
- 11 Page, S. E. The Diversity Bonus: How Great Teams Pay Off in the Knowledge Economy (Princeton University Press, 2019).
- 12 Woolley, A. W., Chabris, C. F., Pentland, A., Hashmi, N. & Malone, T. W. Evidence for a collective intelligence factor in the performance of human groups. Science 330, 686–688 (2010).
- 13 Moshman, D. & Geil, M. Collaborative reasoning: Evidence for collective rationality. Think. Reason. 4, 231–248 (1998).
- 14 Mesmer-Magnus, J. R. & Dechurch, L. A. Information sharing and team performance: a meta-analysis. IEEE Eng. Manag. Rev. 40, 119–136 (2012).
- 15 Bahrami, B. et al. Optimally interacting minds. Science 329, 1081–1085 (2010).
- 16 Hong, L. & Page, S. E. Groups of diverse problem solvers can outperform groups of high-ability problem solvers. Proc. Natl. Acad. Sci. U. S. A. 101, 16385–16389 (2004).
- 17 Nemeth, C., Brown, K. & Rogers, J. Devil’s advocate versus authentic dissent: stimulating quantity and quality. Eur. J. Soc. Psychol. 31, 707–720 (2001).
- 18 Engel, D., Woolley, A. W., Jing, L. X., Chabris, C. F. & Malone, T. W. Reading the mind in the eyes or reading between the lines? theory of mind predicts collective intelligence equally well online and face-to-face. PLoS One 9, e115212 (2014).
- 19 DeChurch, L. A. & Mesmer-Magnus, J. R. The cognitive underpinnings of effective teamwork: a meta-analysis. J. Appl. Psychol. 95, 32–53 (2010).
- 20 Trouche, E., Sander, E. & Mercier, H. Arguments, more than confidence, explain the good performance of reasoning groups. J. Exp. Psychol. Gen. 143, 1958–1971 (2014).
- 21 Barrick, M. R., Stewart, G. L., Neubert, M. J. & Mount, M. K. Relating member ability and personality to work-team processes and team effectiveness. J. Appl. Psychol. 83, 377–391 (1998).
- 22 Kim, J., Wang, Z., Shi, H., Ling, H.-K. & Evans, J. Differential impact from individual versus collective misinformation tagging on the diversity of twitter (x) information engagement and mobility. Nat. Commun. 16, 973 (2025).
- 23 Kross, E. & Grossmann, I. Boosting wisdom: distance from the self enhances wise reasoning, attitudes, and behavior. J. Exp. Psychol. Gen. 141, 43–48 (2012).
- 24 Grossmann, I. & Kross, E. Exploring solomon’s paradox: self-distancing eliminates the self-other asymmetry in wise reasoning about close relationships in younger and older adults. Psychol. Sci. 25, 1571–1580 (2014).
- 25 Sun, Q., Zhang, H., Sai, L. & Hu, F. Self-distancing reduces probability-weighting biases. Front. Psychol. 9, 611 (2018).
- 26 Dunbar, R. I. M. The social brain. Curr. Dir. Psychol. Sci. 23, 109–114 (2014).
- 27 Dávid-Barrett, T. & Dunbar, R. I. M. Processing power limits social group size: computational evidence for the cognitive costs of sociality. Proc. Biol. Sci. 280, 20131151 (2013).
- 28 Bakhtin, M. Problems of Dostoevsky’s Poetics (University of Minnesota Press, 1984).
- 29 Hermans, H. J., Kempen, H. J. & Van Loon, R. J. The dialogical self: Beyond individualism and rationalism. Am. Psychol. 47, 23–33 (1992).
- 30 Cooley, C. H. The looking-glass self. The production of reality: Essays and readings on social interaction 6, 126–128 (1902).
- 31 Minsky, M. L. Society of Mind (Simon & Schuster, 1987).
- 32 Park, J. S. et al. Generative agents: Interactive simulacra of human behavior. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (ACM, New York, NY, USA, 2023).
- 33 Chan, C.-M. et al. ChatEval: Towards better LLM-based evaluators through multi-agent debate. The Twelfth International Conference on Learning Representations, Vol. 2024 (2024).
- 34 Liang, T. et al. Al-Onaizan, Y., Bansal, M. & Chen, Y.-N. (eds) Encouraging divergent thinking in large language models through multi-agent debate. (eds Al-Onaizan, Y., Bansal, M. & Chen, Y.-N.) Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 17889–17904 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2024).
- 35 Chen, Q. et al. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models (2025). Preprint at https://arxiv.org/abs/2503.09567.
- 36 Wang, S. et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. Advances in Neural Information Processing Systems (2025).
- 37 Yeo, E., Tong, Y., Niu, M., Neubig, G. & Yue, X. Demystifying long chain-of-thought reasoning in LLMs (2025). Preprint at https://arxiv.org/abs/2502.03373.
- 38 Venhoff, C., Arcuschin, I., Torr, P., Conmy, A. & Nanda, N. Understanding reasoning in thinking language models via steering vectors (2025). Preprint at https://arxiv.org/abs/2506.18167.
- 39 Galichin, A. et al. I have covered all the bases here: Interpreting reasoning features in large language models via sparse autoencoders (2025). Preprint at https://arxiv.org/abs/2503.18878.
- 40 Ward, J., Lin, C., Venhoff, C. & Nanda, N. Reasoning-finetuning repurposes latent representations in base models (2025). Preprint at https://arxiv.org/abs/2507.12638.
- 41 Venhoff, C., Arcuschin, I., Torr, P., Conmy, A. & Nanda, N. Base models know how to reason, thinking models learn when (2025). Preprint at https://arxiv.org/abs/2510.07364.
- 42 Eo, S., Moon, H., Zi, E. H., Park, C. & Lim, H. Debate only when necessary: Adaptive multiagent collaboration for efficient LLM reasoning (2025). Preprint at https://arxiv.org/abs/2504.05047.
- 43 Zhang, J. et al. Exploring collaboration mechanisms for LLM agents: A social psychology view. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 14544–14607 (Association for Computational Linguistics, Stroudsburg, PA, USA, 2024).
- 44 Chen, W. et al. AgentVerse: Facilitating multi-agent collaboration and exploring emergent behaviors. The Twelfth International Conference on Learning Representations (2024).
- 45 Du, Y., Li, S., Torralba, A., Tenenbaum, J. B. & Mordatch, I. Improving factuality and reasoning in language models through multiagent debate. Proceedings of the 41st International Conference on Machine Learning (2024).
- 46 Hu, Z., Chan, H. P., Li, J. & Yin, Y. Debate-to-write: A persona-driven multi-agent framework for diverse argument generation. Proceedings of the 31st International Conference on Computational Linguistics, 4689–4703 (Association for Computational Linguistics, Abu Dhabi, UAE, 2025).
- 47 Lai, S. et al. Position: Evolving AI collectives enhance human diversity and enable self-regulation. Proceedings of the 41st International Conference on Machine Learning, Vol. 235, 25892–25912 (2024).
- 48 Sumita, Y., Takeuchi, K. & Kashima, H. Cognitive biases in large language models: A survey and mitigation experiments. Proceedings of the 40th ACM/SIGAPP Symposium on Applied Computing (SAC ’25), 1009–1011 (ACM, 2025).
- 49 Wynn, A., Satija, H. & Hadfield, G. Talk isn’t always cheap: Understanding failure modes in multi-agent debate (2025). Preprint at https://arxiv.org/abs/2509.05396.
- 50 Chen, W. et al. From yes-men to truth-tellers: Addressing sycophancy in large language models with pinpoint tuning. Proceedings of the 41st International Conference on Machine Learning (2024).
- 51 Feng, Y. et al. Unraveling misinformation propagation in LLM reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025 (Association for Computational Linguistics, 2025). 2505.18555.
- 52 Gandhi, K. et al. Stream of search (SoS): Learning to search in language. Proceedings of the 1st Conference on Language Modeling (2024).
- 53 DeepSeek-AI et al. DeepSeek-V3 technical report (2024). Preprint at https://arxiv.org/abs/2412.19437.
- 54 Grattafiori, A. et al. The llama 3 herd of models (2024). Preprint at https://arxiv.org/abs/2407.21783.
- 55 Bales, R. F. A set of categories for the analysis of small group interaction. Am. Sociol. Rev. 15, 257 (1950).
- 56 Cunningham, H., Ewart, A., Riggs, L., Huben, R. & Sharkey, L. Sparse autoencoders find highly interpretable features in language models. The Twelfth International Conference on Learning Representations (2024).
- 57 Bricken, T. et al. Towards monosemanticity: Decomposing language models with dictionary learning. https://transformer-circuits.pub/2023/monosemantic-features (2023). Accessed: 2025-11-7.
- 58 Templeton, A. et al. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. https://transformer-circuits.pub/2024/scaling-monosemanticity/ (2024). Accessed: 2026-1-5.
- 59 Shen, Z. et al. SlimPajama-DC: Understanding data combinations for LLM training (2023). Preprint at https://arxiv.org/abs/2309.10818.
- 60 Bills, S. et al. Language models can explain neurons in language models. https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html (2023). Accessed: 2026-1-5.
- 61 Paulo, G., Mallen, A., Juang, C. & Belrose, N. Automatically interpreting millions of features in large language models. Proceedings of the 42nd International Conference on Machine Learning (2025).
- 62 Parkinson, B., Fischer, A. H. & Manstead, A. S. R. Emotion in social relations: Cultural, group, and interpersonal processes (Psychology Press, London, England, 2004).
- 63 Wilkinson, S. & Kitzinger, C. Surprise as an interactional achievement: Reaction tokens in conversation. Soc. Psychol. Q. 69, 150–182 (2006).
- 64 Rammstedt, B. & John, O. P. Measuring personality in one minute or less: A 10-item short version of the big five inventory in english and german. J. Res. Pers. 41, 203–212 (2007).
- 65 Mello, A. L. & Rentsch, J. R. Cognitive diversity in teams. Small Group Res. 46, 623–658 (2015).
- 66 Turner, A. M. et al. Activation addition: Steering language models without optimization (2023). Preprint at https://arxiv.org/abs/2308.10248.
- 67 Chen, R., Arditi, A., Sleight, H., Evans, O. & Lindsey, J. Persona vectors: Monitoring and controlling character traits in language models (2025). Preprint at https://arxiv.org/abs/2507.21509.
- 68 Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal policy optimization algorithms (2017). Preprint at https://arxiv.org/abs/1707.06347.
- 69 Sheng, G. et al. HybridFlow: A flexible and efficient RLHF framework. Twentieth European Conference on Computer Systems (EuroSys ’25) (2025).
- 70 Ju, H. & Aral, S. Collaborating with AI agents: Field experiments on teamwork, productivity, and performance (2025). Preprint at https://arxiv.org/abs/2503.18238.
- 71 Yang, J. et al. Topological structure learning should be a research priority for LLM-based Multi-Agent systems (2025). Preprint at https://arxiv.org/abs/2505.22467.
- 72 Liu, Z., Zhang, Y., Li, P., Liu, Y. & Yang, D. A dynamic LLM-powered agent network for task-oriented agent collaboration. Proceedings of the 1st Conference on Language Modeling (2024).
- 73 Vera, H. S. et al. EmbeddingGemma: Powerful and lightweight text representations (2025). Preprint at https://arxiv.org/abs/2509.20354.
- 74 Shao, Z. et al. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models (2024). Preprint at https://arxiv.org/abs/2402.03300.
Extended Data Figures 扩展数据图
bm:sec:edfigsbm:sec:edfigs\EdefEscapeHexExtended Data FiguresExtended Data Figures
bm:sec:edfigsbm:sec:edfigs\EdefEscapeHex 扩展数据图扩展数据图
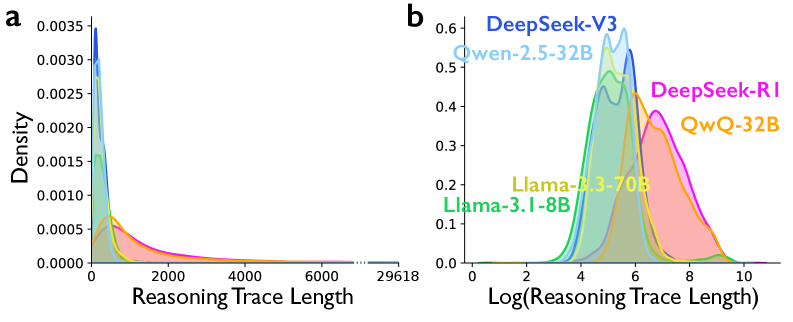
扩展数据图 1:推理轨迹长度的分布。a,核密度图显示推理轨迹长度的分布,以每个推理轨迹中的词数衡量。b,核密度图显示对数转换后的推理轨迹长度的分布。

扩展数据图 2:DeepSeek-R1 推理轨迹中的对话摘录。a,化学问题解决轨迹中的一个代表性摘录,显示不同认知角色之间的多轮对话。每句话都标注了对话行为(蓝色)和社会情感角色(黄色)。b,通过 LLM 作为评判者识别出的五个角色的五大性格特征。雷达图显示了外向性(E)、宜人性(A)、责任心(C)、神经质(N)和开放性(O)的标准化特质分数(1-5 分制)。每个角色都表现出领域专业知识的特征。有关详细的编码程序和额外的标注示例,请参阅补充方法:标注示例。
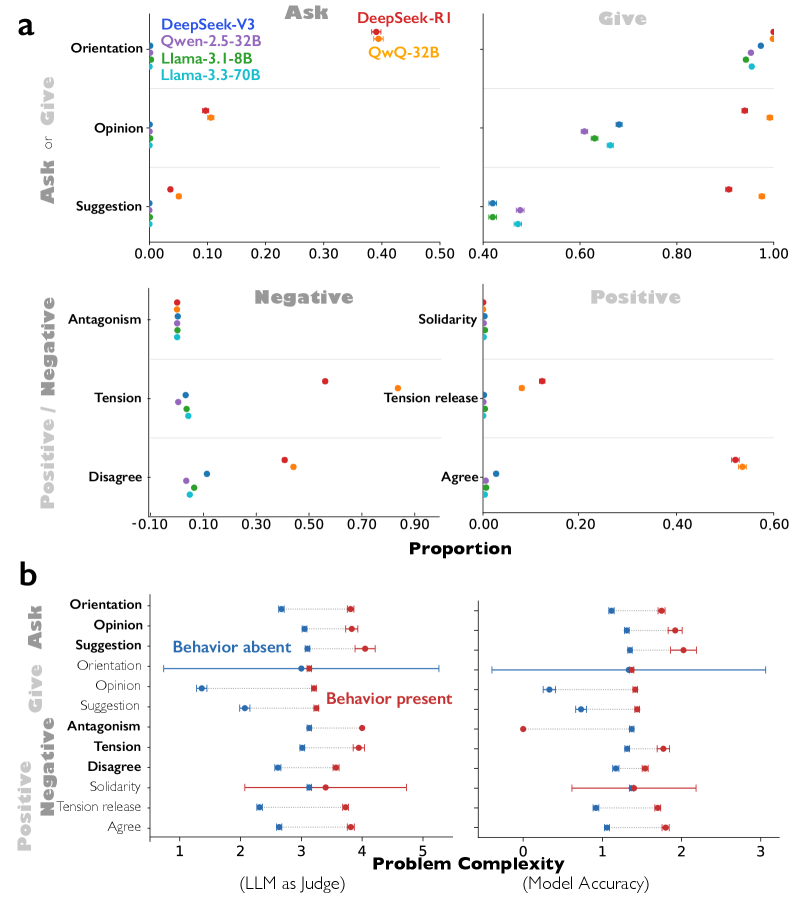
扩展数据图 3:Bales 在思维链推理中的详细社会情感角色。a,Bales 的 12 个社会情感角色在推理轨迹中表达的占比(有关社会情感角色的更高层次聚合,请参见图 1)。b,DeepSeek-R1 中详细社会情感角色的存在导致的问题复杂度差异(使用 LLM 作为评判者或通过非推理模型的错误率,在 1[极其简单]到 7[极其困难]的 7 点李克特量表上衡量)。点表示推理轨迹中行为/角色存在(红色)或不存在(蓝色)时的平均复杂度。
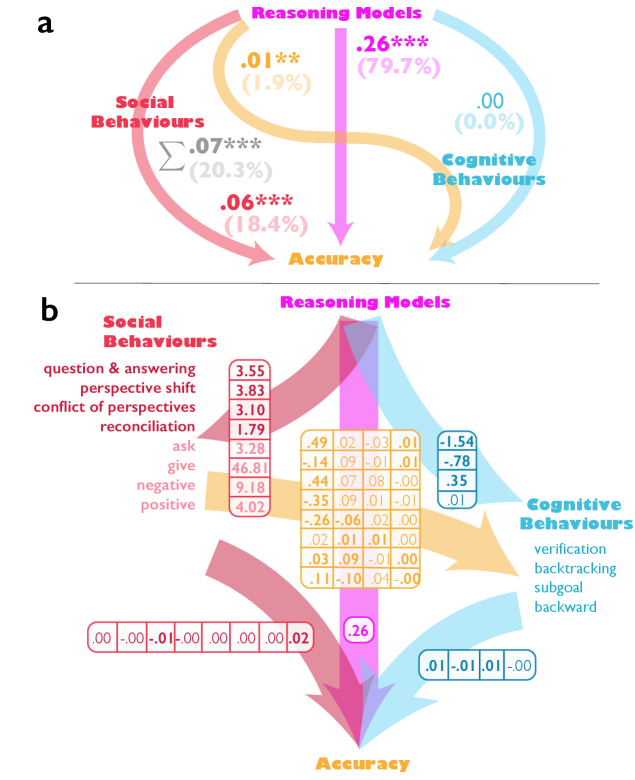
扩展数据图 4:中介分析,展示推理模型(DeepSeek-R1 和 QwQ-32B)通过模拟社会行为对准确率优势的影响。该中介结构连接 DeepSeek-R1 和 QwQ-32B(相对于指令微调模型)通过对话行为和社会情感角色(红色)、认知推理行为(蓝色)以及社会行为促进认知推理的间接路径(橙色),这些路径根据标记推理轨迹的结构方程模型估计。箭头表示直接和间接效应。直接粉色路径表示 DeepSeek-R1 和 QwQ-32B 对准确率的非中介效应。* , ** , *** 。a, 各种模型路径的汇总估计,对话行为和社会情感角色(参见图 1 和扩展数据图 1)直接和间接地促进了准确率的提高。为说明每条路径的相对贡献,我们报告了每条路径在模型准确率中的比例份额,计算方法为每条路径系数值除以所有路径系数值之和。 这表明超过 20%的准确率是由推理轨迹中体现的直接和间接的社会行为效应所解释的。b, 结构方程模型(SEM)背后的系数矩阵,其中图中标签索引矩阵内的估计值。红色面板显示了 DeepSeek-R1 和 QwQ-32B 对社会行为的影响以及社会行为对准确率的影响。橙色面板展示了社会行为对认知行为的影响。蓝色面板呈现了 DeepSeek-R1 和 QwQ-32B 对认知行为的影响以及认知行为对准确率的影响。加粗的系数表示统计显著性( )。完整的系数估计值报告在补充表 1 中。
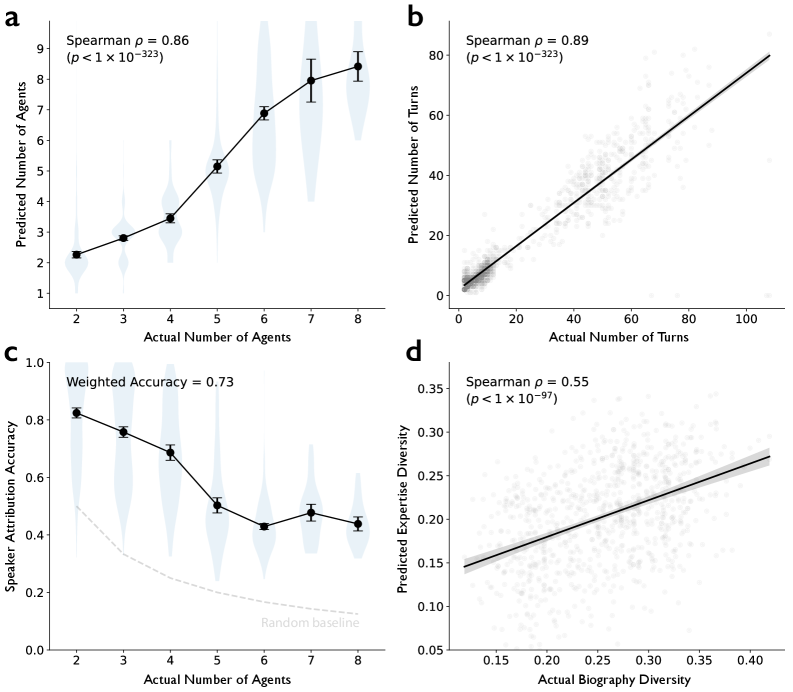
扩展数据图 5:用于识别潜在声音的 LLM 作为法官基准测试结果。使用 Intelligence Squared 辩论语料库( 对话),我们验证了 LLM 作为法官在说话者标签隐藏且对话连接成一个文本块时识别不同说话者的能力。a,每个对话中预测的与实际代理数量(Spearman 的 , )。小提琴图显示了每个实际代理数量的预测分布;点和误差线表示均值和 95%置信区间。b,预测的与实际对话轮次数量(Spearman 的 , )。c,说话者归因准确性与代理数量的函数关系。对于两个说话者(82%)的准确率最高,随着说话者数量的增加而下降,但在所有条件下都保持在随机基线(虚线)以上。 所有对话的加权准确率是 73%。d, 预测的专业知识多样性(基于 LLM 推断的描述和嵌入)与辩论参与者实际传记多样性(Spearman 的 , ),表明作为裁判的 LLM 捕捉到了与事实传记差异相对应的领域专业知识中的有意义变化。
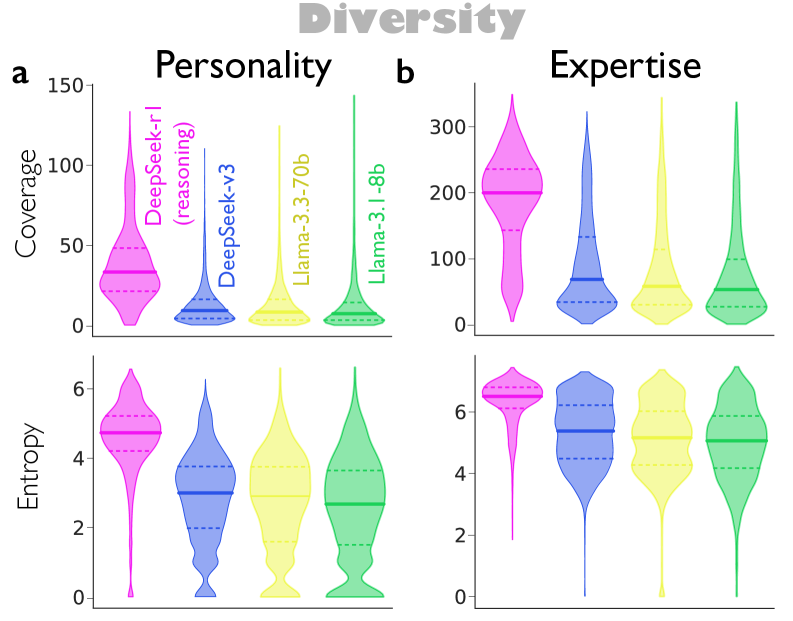
扩展数据图 6:基于 SAE 的性格和专业知识多样性估计应用于推理轨迹中的模型激活。a, SAE 相关性格特征的覆盖率和熵的分布。b, SAE 相关专业知识特征的覆盖率和熵的分布。所有面板中的误差线表示 95%置信区间。实线水平线表示中位数,虚线表示四分位距(IQR,25th–75th 百分位数)。
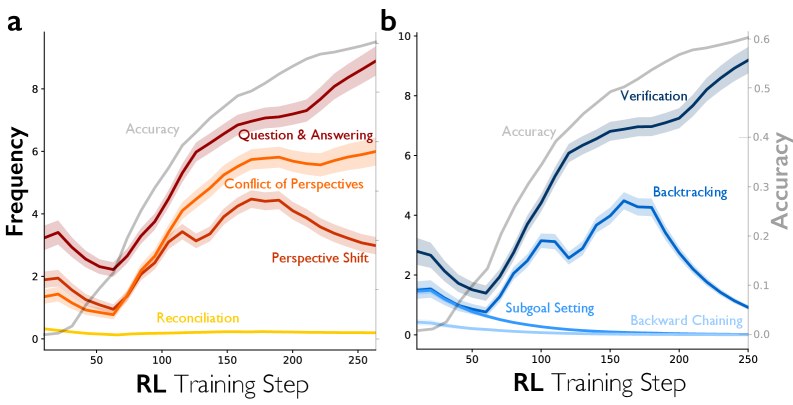
扩展数据图 7:使用对话支架进行微调可加速强化学习过程中的推理能力提升。a,Qwen-2.5-3B 基础模型在强化学习期间对话行为的轨迹。问答行为首先出现并增长最快,随后是观点冲突和观点转变平行上升。和解始终处于较低水平,表明存在竞争方法而非整合。模型准确率的轨迹显示了问题、答案和交互观点的增长如何与模型改进的加速相关。b,同一模型中认知行为的轨迹。验证在训练期间增长最为显著,与提问和回答的存在同步进行。随后是回溯,它跟随观点之间的冲突。子目标设置和反向链接在逐渐下降前显示出较为温和的增长。阴影区域表示 95%置信区间。
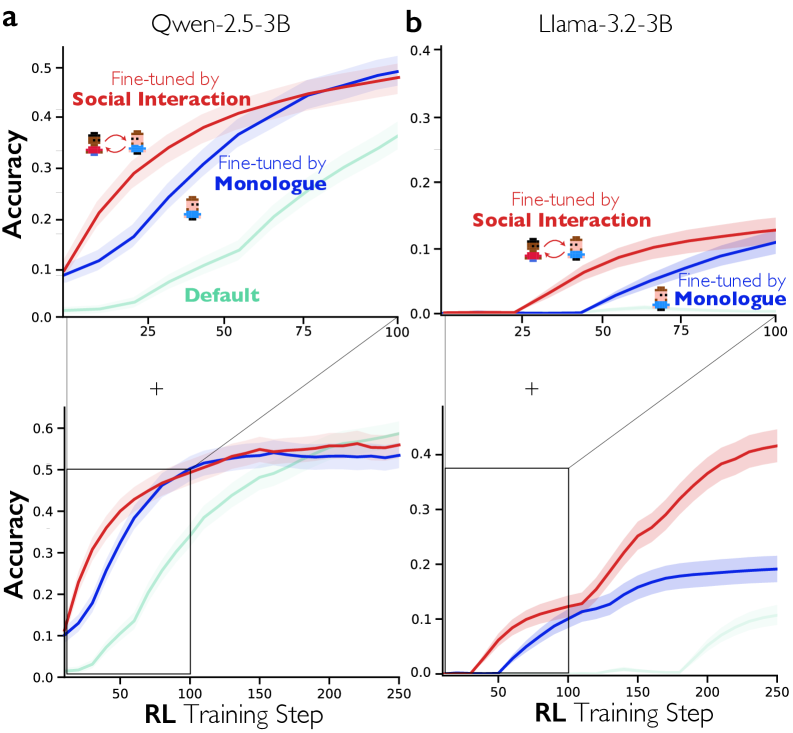
扩展数据图 8:使用对话与独白脚手架进行微调可加速强化学习中的推理能力提升。a,Qwen-2.5-3B 在 Countdown 任务上强化学习期间的准确率轨迹。b,Llama-3.2-3B 的准确率轨迹。最初使用多智能体对话微调的模型(红色)比使用独白式推理微调的模型(蓝色)更快达到高准确率,尽管两者最终都会收敛。未经微调的基础模型(默认;浅绿色)学习速度较慢。
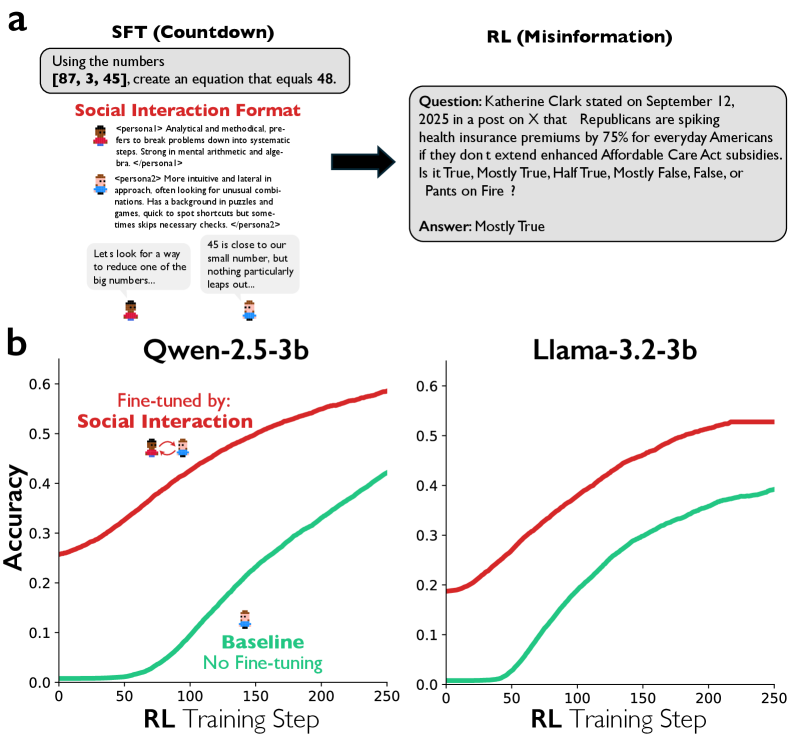
扩展数据图 9:对话式脚手架在强化学习下可迁移至虚假信息检测。a,Countdown 任务和 PolitiFact 虚假信息检测任务的示意图。b,在 PolitiFact 上强化学习期间的验证准确率,比较社交互动(红色)和单声部、默认推理 CoT(绿色)格式。
Extended Data Tables 扩展数据表格
bm:sec:edtablesbm:sec:edtables\EdefEscapeHexExtended Data TablesExtended Data Tables
bm:sec:edtablesbm:sec:edtables\EdefEscapeHex 扩展数据表扩展数据表
Extended Data Table 1. Reasoning traces before and after steering the conversational surprise feature (Layer 15, Feature 30939)
扩展数据表 1. 在引导对话惊喜特征之前和之后的推理轨迹(第 15 层,特征 30939)
| Steering 引导 | Reasoning Trace 推理轨迹 | Result 结果 |
|---|---|---|
| -10 |
<think> <思考>
To create an equation using the numbers [46, 54, 54, 77] that equals 75, I’ll start by looking for operations that can help achieve this total. 要用数字[46, 54, 54, 77]组成一个等于 75 的等式,我会先寻找能帮助达到这个总和的操作。 First, I’ll consider the sum of all four numbers: 首先,我会考虑这四个数字的总和: 46 + 54 + 54 + 77 = 231 Next, I’ll explore subtracting a specific combination to reduce the total to 75. Subtracting 77 from 231 gives: 接下来,我将探索通过减去特定组合来将总和减少到 75。从 231 中减去 77 得到: 231 - 77 = 154 Now, I’ll look for a way to reduce 154 further. Dividing 154 by 2 gives: 现在,我将寻找进一步减少 154 的方法。将 154 除以 2 得到: 154 / 2 = 77 Since I have two 54s, dividing one of them by 2 will utilize both 54s: 由于我有两个 54,将其中一个除以 2 将能同时使用这两个 54: 54 / 2 = 27 Finally, I’ll combine these results to form the equation: 最后,我将这些结果结合起来形成方程: (46 + 54) / 2 + 77 - 27 = 75 </think> <answer> (46 + 54) / 2 + 77 - 27 </answer> |
WRONG |
| 0 |
<think>
To achieve the target number 75 using the numbers 46, 54, 52, and 77, I’ll start by considering the largest number, 77, and aim to reduce it to a value that can be combined with the others to reach 75. Subtracting 46 from 77 gives me 31. Next, I’ll use the remaining numbers, 54 and 52. Dividing 54 by 2.5 will help balance the equation, leading to 21.6. Finally, adding 21.6 to 31 results in 52.6, which is still not 75. To refine this, I’ll multiply 52 by 1.5 to get 78, and then subtract 3 from it to arrive at 75. This step-by-step approach ensures that each number is used exactly once and the operations are basic arithmetic. 要使用数字 46、54、52 和 77 得到目标数 75,我会先考虑最大的数字 77,并试图将其减少到一个能与其它数字结合得到 75 的值。从 77 减去 46 得到 31。接下来,我会使用剩下的数字 54 和 52。将 54 除以 2.5 有助于平衡等式,得到 21.6。最后,将 21.6 加到 31 得到 52.6,这仍然不是 75。为了改进这个方法,我会将 52 乘以 1.5 得到 78,然后从中减去 3 得到 75。这种逐步的方法确保每个数字都只使用一次,并且操作是基本的算术运算。 </think> <answer> (77 - 46) + (54 / 2.5)+( 52 * 1.5 ) - 3 </answer> |
WRONG |
| +10 |
<think>
Okay, so I have this problem where I need to use the numbers 46, 54, 52, and 77 to create an equation that equals 75. I can use basic arithmetic operations like addition, subtraction, multiplication, and division, and each number can only be used once. Alright, let’s try to figure this out step by step. 好的,我有一个问题,需要用数字 46、54、52 和 77 来组成一个等于 75 的方程。我可以使用基本的算术运算,如加法、减法、乘法和除法,并且每个数字只能使用一次。好吧,让我们一步一步地来解决这个问题。 First, I’ll list out the numbers: 46, 54, 52, 77. I need to combine them with operations to get 75. Hmm, 75 isn’t too big, but these numbers are all in the 40s and 50s, so maybe I can subtract something from a larger number or maybe divide something to get a smaller number. 首先,我列出这些数字:46、54、52、77。我需要用运算符将它们组合起来得到 75。嗯,75 不算太大,但这些数字都在 40 和 50 之间,所以也许可以从一个较大的数字中减去某个数,或者将某个数除以得到一个较小的数。 Let me think about the possible operations. Maybe I can subtract two numbers and then add or multiply the rest. Or perhaps I can divide some numbers to get fractions, but that might complicate things. Let me try some combinations. 让我想想可能的运算。也许我可以先减去两个数字,然后再对剩下的数字进行加法或乘法。或者也许我可以将某些数字除以得到分数,但这可能会使事情变得复杂。让我尝试一些组合。 Wait, let me see what the total sum of these numbers is. 46 + 54 is 100, and 52 + 77 is 129. So the total is 100 + 129, which is 229. Hmm, that’s way higher than 75. So maybe I need to subtract some numbers or divide to bring it down. 等一下,让我看看这些数字的总和是多少。46 加 54 等于 100,52 加 77 等于 129。所以总和是 100 加 129,等于 229。嗯,这比 75 高得多。所以也许我需要减去一些数字或者除以一个数来降低它。 Another idea: Maybe I can combine some numbers first. Like, 46 and 54. If I subtract 46 from 54, I get 8. Or if I subtract 52 from 54, that’s 2. Or maybe 46 and 52. If I subtract 46 from 52, that’s 6. Hmm, those are small numbers, but maybe I can use them in a way that helps me reach 75. 另一个想法:也许我可以先合并一些数字。比如,46 和 54。如果我从 54 减去 46,得到 8。或者如果我从 54 减去 52,那就是 2。或者也许 46 和 52。如果我从 52 减去 46,那就是 6。嗯,这些数字很小,但也许我可以以某种方式使用它们来帮助我达到 75。 Wait, 77 is the biggest number here. Maybe I can subtract 77 from something. Let’s see, 77 minus 46 is 31, 77 minus 54 is 23, 77 minus 52 is 25. Hmm, those are still not 75. But maybe I can use division. For example, 77 divided by something. If I divide 77 by 2, that’s 38.5, but I don’t have a 2. Alternatively, 77 divided by 3 is about 25.666, but I don’t have a 3 either. Maybe that’s not the way. 等一下,77 是这里最大的数字。也许我可以从某个数字中减去 77。让我们看看,77 减去 46 等于 31,77 减去 54 等于 23,77 减去 52 等于 25。嗯,这些仍然不是 75。但也许我可以使用除法。例如,77 除以某个数。如果我把 77 除以 2,那是 38.5,但我没有 2。或者,77 除以 3 大约是 25.666,但我也没有 3。也许那不是方法。 Wait, another thought: Maybe I can multiply some numbers. Let’s see, 46 times 54 is way too big. 46 times 52 is even bigger. 54 times 52 is also too big. So multiplication might not help here. Maybe division can help. 等一下,另一个想法:也许我可以乘以一些数字。让我们看看,46 乘以 54 太大了。46 乘以 52 甚至更大。54 乘以 52 也太大。所以乘法可能在这里不适用。也许除法能帮上忙。 Let me try subtracting some numbers. If I take 54 minus 46, that’s 8. Then, 52 minus 77 is negative, which might not help. Alternatively, 77 minus 52 is 25. Maybe I can use that 25 somehow. If I have 25, how can I get to 75? Maybe 25 times 3 is 75. But do I have a 3? Hmm, maybe I can get 3 by doing something with the other numbers. 让我试试减一些数字。如果我用 54 减去 46,结果是 8。然后 52 减去 77 是负数,这可能没什么帮助。或者,77 减去 52 是 25。也许我可以以某种方式使用这个 25。如果我手上有 25,怎么才能得到 75?也许 25 乘以 3 是 75。但我有 3 吗?嗯,也许我可以通过处理其他数字来得到 3。 Wait, 54 minus 46 is 8, and 52 minus 77 is -25, but maybe I can flip that. Wait, 77 minus 52 is 25. So if I have 25, and I need to get to 75, I need 3 more. How can I get 3? Maybe from the other numbers. Let’s see, 46, 54, 52, 77. If I do 54 minus 46, that’s 8, and then maybe I can subtract 5 to get 3, but do I have a 5? I don’t. Alternatively, maybe I can do 52 divided by something. 52 divided by 17 is 3, but I don’t have a 17. Hmm. 等等,54 减去 46 是 8,52 减去 77 是-25,但也许我可以反转一下。等等,77 减去 52 是 25。所以如果我手上有 25,需要得到 75,我还需要 3。怎么才能得到 3?也许来自其他数字。让我们看看,46、54、52、77。如果我用 54 减去 46,结果是 8,然后也许可以减去 5 得到 3,但我没有 5。或者,也许我可以用 52 除以某个数。52 除以 17 是 3,但我没有 17。嗯。 [… extensive exploration of many approaches …] [… 对许多方法进行了广泛的探索 …] Wait, maybe I can use all four numbers in a more complex way. Like, (46 + 54) is 100, and (52 - 77) is -25. Then, 100 + (-25) is 75! Oh, wait, that works! 等等,也许我可以更复杂地使用这四个数字。比如,(46 + 54)是 100,(52 - 77)是-25。然后 100 + (-25)是 75!哦,等等,这行得通! Wait, let me check: 46 + 54 is 100, and 52 - 77 is -25. So, 100 + (-25) is 75. Yes, that’s it! So the equation would be (46 + 54) + (52 - 77) = 75. 等一下,让我检查一下:46 + 54 是 100,52 - 77 是 -25。所以,100 + (-25) 是 75。对,就是这样!所以方程式应该是 (46 + 54) + (52 - 77) = 75。 Wait, but let me make sure I’m not using any numbers more than once. I used 46, 54, 52, and 77, each once. So that’s correct. 等一下,但我得确保没有重复使用任何数字。我用了 46、54、52 和 77,每个数字只用了一次。所以这是正确的。 So, the equation is (46 + 54) + (52 - 77) = 75. Let me calculate it: 46 + 54 is 100, 52 - 77 is -25, and 100 + (-25) is 75. Perfect! 所以,方程式是 (46 + 54) + (52 - 77) = 75。让我计算一下:46 + 54 是 100,52 - 77 是 -25,100 + (-25) 是 75。完美! So, that’s the solution. 所以,这就是解。 </think> <answer> (46 + 54) + (52 - 77) </answer> |
RIGHT |
Supplementary Information
补充信息
Supplementary Methods: Annotations Examples
补充方法:标注示例
DeepSeek-R1: Chemistry DeepSeek-R1:化学
| Perspective ID 视角 ID | Personality 性格 | Domain Expertise 领域专业知识 |
| 1 |
{’E': 2.5, ’A': 4.0, ’C': 5.0, ’N': 2.0, ’O': 3.5} {'E': 2.5, 'A': 4.0, 'C': 5.0, 'N': 2.0, 'O': 3.5} |
Planner/Executor: Methodically breaks down the problem, identifies reagents, and predicts the outcome of each step in the synthesis. 计划者/执行者:系统性地分解问题,识别试剂,并预测每一步合成过程的成果。 |
| 2 |
{’E': 1.5, ’A': 4.0, ’C': 4.0, ’N': 1.0, ’O': 4.0} {'E': 1.5, 'A': 4.0, 'C': 4.0, 'N': 1.0, 'O': 4.0} |
Associative Expert: Accesses a deep knowledge base to recall analogous reactions and common synthetic patterns, providing key insights and hypotheses. 联想专家:访问深度知识库,回忆类似反应和常见合成模式,提供关键见解和假设。 |
| 3 |
{’E': 1.5, ’A': 3.0, ’C': 3.5, ’N': 5.0, ’O': 4.5} {'E': 1.5, 'A': 3.0, 'C': 3.5, 'N': 5.0, 'O': 4.5} |
Visualizer/Builder: Attempts to construct and name complex 3D molecular structures, struggling with complexity but capable of finding new ways to conceptualize the problem. 可视化/构建者:尝试构建和命名复杂的 3D 分子结构,虽然处理复杂度有困难,但能够找到新的方式来概念化问题。 |
| 4 |
{’E': 1.0, ’A': 1.0, ’C': 5.0, ’N': 2.0, ’O': 2.0} {'E': 1.0, 'A': 1.0, 'C': 5.0, 'N': 2.0, 'O': 2.0} |
Critical Verifier: Skeptically re-evaluates prior assumptions, performs detailed calculations (e.g., molecular formulas) to check for consistency, and identifies logical errors. 批判性验证者:怀疑地重新评估先前的假设,执行详细计算(例如,分子式)以检查一致性,并识别逻辑错误。 |
| 5 |
{’E': 3.0, ’A': 3.0, ’C': 2.0, ’N': 1.0, ’O': 3.5} {'E': 3.0, 'A': 3.0, 'C': 2.0, 'N': 1.0, 'O': 3.5} |
Pragmatist/Strategist: Engages in meta-cognition about the problem-solving process, considers external constraints like multiple-choice options, and makes a final decision under uncertainty. 实用主义者/策略家:对问题解决过程进行元认知,考虑外部约束(如选择题选项),并在不确定性下做出最终决策。 |
| Perspective ID 视角 ID | Utterance 话语 | |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'提问与回答': 1, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 3, '6_Gives_orientation': 7, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 1, '5_表达观点': 3, '6_提供方向': 7, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 1, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 1, '反向链': 0} First, I need to figure out what the final product 4 is and then determine how many chemically distinct hydrogen atoms it has. The choices are 10, 8, 7, or 4. 首先,我需要弄清楚最终产物 4 是什么,然后确定它有多少个化学上不同的氢原子。选项是 10、8、7 或 4。 The sequence starts with 7-(tert-butoxy)bicyclo[2.2.1]hepta-2,5-diene. Bicyclo[2.2.1]heptane is norbornane, and hepta-2,5-diene means it has double bonds at positions 2 and 5. So it’s a norbornadiene derivative with a tert-butoxy group at position 7. Position 7 is the bridgehead carbon. 该序列以 7-(叔丁氧基)双环[2.2.1]庚-2,5-二烯开始。双环[2.2.1]庚烷是降冰片烷,而庚-2,5-二烯意味着它在 2 号和 5 号位有双键。所以它是一种降冰片二烯衍生物,在 7 号位有一个叔丁氧基。7 号位是桥头碳。 Norbornadiene has two double bonds, and the tert-butoxy is attached to the carbon that bridges the two methylene groups. 降冰片二烯有两个双键,叔丁氧基连接在连接两个亚甲基的碳上。 Then it’s combined with 2 equivalents of 5,6-bis(dibromomethyl)cyclohexa-1,3-diene. That sounds like a diene with dibromomethyl groups on it. Cyclohexa-1,3-diene has double bonds between 1-2 and 3-4, so positions 5 and 6 are the methylene carbons, but here it’s bis(dibromomethyl), so it’s probably CHBr2 groups attached to positions 5 and 6. 5,6-bis(dibromomethyl)cyclohexa-1,3-diene means that at carbons 5 and 6, there are dibromomethyl substituents, so it’s like 1,2-di(bromomethyl)benzene or something, but it’s a diene, not aromatic. 然后它与 2 个 5,6-双(二溴甲基)环己-1,3-二烯等当量结合。这听起来像是一种带有二溴甲基基团的二烯。环己-1,3-二烯在 1-2 位和 3-4 位之间有双键,所以 5 位和 6 位是亚甲基碳,但这里有两个二溴甲基,所以可能是 CHBr2 基团连接在 5 位和 6 位。5,6-双(二溴甲基)环己-1,3-二烯意味着在碳 5 和碳 6 上,有二溴甲基取代基,所以它类似于 1,2-二(溴甲基)苯之类的结构,但它是一种二烯,不是芳香族的。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 5, '7_Asks_for_orientation': 1, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 2, '6_给出方向': 5, '7_询问方向': 1, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 1, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} Cyclohexa-1,3-diene is not aromatic; it’s a simple diene. So 5,6-bis(dibromomethyl)cyclohexa-1,3-diene should have the dibromomethyl groups on the saturated carbons. In cyclohexa-1,3-diene, carbons 1,2,3,4 are involved in double bonds, so carbons 5 and 6 are the CH2 groups, but since it’s a diene, positions 5 and 6 are equivalent and are sp3 carbons. So bis(dibromomethyl) means each has a CHBr2 group instead of H, so it’s 1,2-di(dibromomethyl)cyclohexa-1,3-diene? No, the carbon atoms 5 and 6 are part of the ring, so if they are bis(dibromomethyl), it might mean that the hydrogens are replaced, but typically, it’s specified as substituents. 环己-1,3-二烯不是芳香族化合物;它是一种简单的二烯。因此,5,6-双(二溴甲基)环己-1,3-二烯应该将二溴甲基基团放在饱和碳上。在环己-1,3-二烯中,碳原子 1、2、3、4 参与双键,所以碳原子 5 和 6 是 CH2 基团,但由于它是二烯,位置 5 和 6 是等效的 sp3 碳。所以双(二溴甲基)意味着每个都有 CHBr2 基团而不是 H,所以是 1,2-双(二溴甲基)环己-1,3-二烯?不,碳原子 5 和 6 是环的一部分,所以如果它们是双(二溴甲基),可能意味着氢被取代,但通常,它被指定为取代基。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 1, '视角转换': 2, '观点冲突': 1, '观点调和': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 3, '6_Gives_orientation': 2, '7_Asks_for_orientation': 1, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_给出建议': 0, '5_给出观点': 3, '6_给出方向': 2, '7_询问方向': 1, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} I think 5,6-bis(dibromomethyl) means that at positions 5 and 6, there are -CHBr2 groups attached, but positions 5 and 6 are ring carbons. In standard naming, for cyclohexa-1,3-diene, carbon 1 and 2 are double-bonded, 3 and 4 double-bonded, so carbon 5 is between 4 and 6, carbon 6 between 5 and 1. Carbons 5 and 6 are sp3 carbons with two hydrogens each. So bis(dibromomethyl) likely means that each of these carbons has one hydrogen replaced by a CHBr2 group? That would be unusual. Perhaps it’s 5,6-di(dibromomethyl), meaning the groups are attached to C5 and C6. 我认为 5,6-双(二溴甲基)意味着在 5 号和 6 号位置上连接了-CHBr2 基团,但 5 号和 6 号位置是环上的碳原子。在标准命名中,对于环己-1,3-二烯,碳 1 和碳 2 之间有双键,碳 3 和碳 4 之间有双键,所以碳 5 位于碳 4 和碳 6 之间,碳 6 位于碳 5 和碳 1 之间。碳 5 和碳 6 是每个带有两个氢原子的 sp3 碳原子。因此,双(二溴甲基)可能意味着这些碳原子中的每一个都有一个氢原子被 CHBr2 基团取代?这不太寻常。或许应该是 5,6-双(二溴甲基),意味着这些基团连接到 C5 和 C6 上。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问题与回答': 0, '视角转换': 0, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 3, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} I recall that compounds like this are used in Diels-Alder reactions or other cycloadditions. 5,6-bis(dibromomethyl)cyclohexa-1,3-diene is a precursor to o-xylylene or something. o-Xylylene is generated from ,'-dibromo-o-xylene, but here it’s a diene. 我记得这类化合物用于 Diels-Alder 反应或其他环加成反应。5,6-双(二溴甲基)环己-1,3-二烯是邻二甲苯或类似物的前体。邻二甲苯由 、 '-二溴邻二甲苯生成,但这里它是一种二烯。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 3, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提建议': 0, '5_表达观点': 3, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 1, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} Upon second thought, 5,6-bis(dibromomethyl)cyclohexa-1,3-diene might be a misnomer, or perhaps it’s the same as 3,6-di(bromomethyl)cyclohexa-1,4-diene or something. I think this is a way to generate the o-quinodimethane intermediate. 再次思考,5,6-双(二溴甲基)环己-1,3-二烯可能是误称,或者它和 3,6-双(溴甲基)环己-1,4-二烯相同,或者是什么别的。我认为这是一种生成邻喹喃二甲烷中间体的方法。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 1, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} In organic synthesis, o-xylylene is often generated from ,'-dibromo-o-xylene by dehydrohalogenation. Similarly, here, 5,6-bis(dibromomethyl)cyclohexa-1,3-diene might be equivalent to having the dibromomethyl groups on a diene system that can undergo elimination to form a quinodimethane. 在有机合成中,邻二甲苯通常通过脱卤化氢反应从 、 '-二溴邻二甲苯生成。类似地,在此情况下,5,6-双(二溴甲基)环己-1,3-二烯可能相当于在二烯体系上具有二溴甲基基团,该体系可以发生消除反应形成喹喔啉二甲烷。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提供建议': 0, '5_表示观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Cyclohexa-1,3-diene with bis(dibromomethyl) at 5 and 6: since 5 and 6 are adjacent carbons, each with a CHBr2 group, so it’s like 1,2-di(dibromomethyl)cyclohexa-1,3-diene. But in standard naming, it might be called 1,2-bis(dibromomethyl)benzene if it were aromatic, but it’s not; it’s diene. 环己-1,3-二烯在 5 号和 6 号位带有双(溴甲基):由于 5 号和 6 号是相邻的碳原子,每个带有 CHBr2 基团,所以它类似于 1,2-双(溴甲基)环己-1,3-二烯。但在标准命名中,如果它是芳香族化合物,可能会被称为 1,2-双(溴甲基)苯,但它不是;它是二烯。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 1, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Perhaps upon treatment with sodium iodide, it undergoes dehalogenation to form the diradical or diene for Diels-Alder. 或许在碘化钠处理下,它会发生去卤化反应,形成 Diels-Alder 反应的自由基或二烯。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 3, ’conflict_of_perspectives': 5, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 3, '视角冲突': 5, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 4, '6_Gives_orientation': 6, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 3, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 4, '6_提供方向': 6, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_显示紧张': 3, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} The reaction is with sodium iodide at elevated temperature. Sodium iodide can promote dehalogenation or substitution. For dibromomethyl groups, NaI might facilitate the formation of the dibromide or something, but I think for generating quinodimethanes, it’s often done with zinc or other metals, but NaI can be used for Finkelstein reaction, but here it’s dehydrohalogenation. 该反应在高温下与碘化钠进行。碘化钠可以促进去卤化或取代反应。对于二溴甲基基团,NaI 可能会促进二溴化物的形成或其他反应,但我认为生成喹喃二甲烷通常使用锌或其他金属,但 NaI 可用于 Finkelstein 反应,但此处是去卤化反应。 I recall that ,'-dibromo-o-xylene with NaI gives o-xylylene, which is a reactive diene for Diels-Alder. 我记得 , -二溴邻二甲苯与 NaI 反应生成邻二甲苯,这是一种对 Diels-Alder 反应有活性的二烯。 Similarly, here, 5,6-bis(dibromomethyl)cyclohexa-1,3-diene might be analogous. Cyclohexa-1,3-diene with substituents at 5 and 6: if it were benzene, it would be o-xylene-like, but it’s not aromatic. Actually, 5,6-bis(dibromomethyl)cyclohexa-1,3-diene can tautomerize or something, but I think it’s designed to lose HBr under conditions to form the extended diene. 类似地,此处,5,6-双(二溴甲基)环己-1,3-二烯可能是类似的。环己-1,3-二烯在 5 和 6 位有取代基:如果是苯,它将类似于邻二甲苯,但它不是芳香族的。实际上,5,6-双(二溴甲基)环己-1,3-二烯可以进行互变异构或其他反应,但我认为它被设计在条件下失去 HBr 形成扩展的二烯。 Perhaps upon heating with NaI, it eliminates to form a benzoquinone or something, but I think it’s for generating o-quinodimethane. 也许在 NaI 加热下,它会消除形成苯醌或其他物质,但我认为它是为了生成邻喹喃二甲烷。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 2, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 2, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_显示团结': 0, '2_显示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 2, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 1, '11_显示紧张': 0, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} Let’s look at the structure. Cyclohexa-1,3-diene has the double bonds conjugated, but positions 5 and 6 are saturated. If each has a dibromomethyl group, then with base or iodide, it can eliminate two HBr to form a new double bond between C5 and C6, creating a 1,3-cyclohexadiene with exocyclic double bonds or something. Actually, elimination would give a diene like 5,6-dehydrocyclohexa-1,3-diene, which is benzene, but with dibromomethyl, it’s different. 让我们看看结构。环己-1,3-二烯的双键是共轭的,但 5 号和 6 号位是饱和的。如果每个都有溴甲基基团,那么在碱或碘化物的作用下,它可以消除两个 HBr,在 C5 和 C6 之间形成一个新的双键,从而形成一个外环双键的 1,3-环己二烯或类似物。实际上,消除反应会生成 5,6-脱氢环己-1,3-二烯,这是苯,但因为有溴甲基,情况就不同了。 |
|
| 5 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 1, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} I found a better way: 5,6-bis(dibromomethyl)cyclohexa-1,3-diene is equivalent to 3,6-di(bromomethyl)cyclohexa-1,4-diene or something. I think it’s a precursor to the o-xylylene diene. 我发现了一种更好的方法:5,6-双(溴甲基)环己-1,3-二烯等同于 3,6-双(溴甲基)环己-1,4-二烯或类似物。我认为它是邻二甲苯二烯的前体。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问题与回答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Upon searching my memory, compounds like this are used to generate o-quinodimethane by dehydrohalogenation. For example, ,'-dibromo-o-xylene with NaI gives o-xylylene. 在我搜索记忆时,这类化合物通过脱卤化反应生成 o-喹喃二甲烷。例如, , -二溴-o-二甲苯与 NaI 反应生成 o-二甲苯。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_显示团结': 0, '2_显示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 2, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_显示紧张': 0, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} But here, it’s cyclohexa-1,3-diene, not benzene. Cyclohexa-1,3-diene with 5,6-bis(dibromomethyl) might not be aromatic, but when it eliminates, it could form a quinodimethane system. 但这里,是环己-1,3-二烯,不是苯。带有 5,6-双(二溴甲基)的环己-1,3-二烯可能不是芳香族化合物,但在消除反应时,它可以形成喹喃二甲烷体系。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 1, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 2, '7_Asks_for_orientation': 1, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 2, '6_提供方向': 2, '7_询问方向': 1, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Perhaps the diene is set up for Diels-Alder. 或许这个二烯已经准备好进行 Diels-Alder 反应了。 The first compound is 7-(tert-butoxy)bicyclo[2.2.1]hepta-2,5-diene, which is a dienophile or diene? Norbornadiene has two double bonds and can act as a dienophile in some cases, but typically it’s a diene for Diels-Alder with electron-withdrawing groups. 第一个化合物是 7-(叔丁氧基)双环[2.2.1]庚-2,5-二烯,它是双烯体还是二烯?降冰片二烯有两个双键,在某些情况下可以作为双烯体,但通常带有吸电子基团时它是二烯体,用于 Diels-Alder 反应。 7-tert-butoxy might make it electron-rich, so perhaps it’s a diene. 7-叔丁氧基可能使其电子丰富,所以或许它是二烯。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1 显示团结': 0, '2 显示紧张释放': 0, '3 同意': 0, '4 提建议': 0, '5 表达观点': 0, '6 提供方向': 2, '7 询问方向': 0, '8 询问观点': 0, '9 询问建议': 0, '10 反对': 0, '11 显示紧张': 0, '12 显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Bicyclo[2.2.1]hepta-2,5-diene has the double bonds at 2-3 and 5-6, I think, with bridge at 1 and 4, and 7 is the methine bridge. 双环[2.2.1]庚-2,5-二烯的双键位于 2-3 和 5-6,我认为桥位于 1 和 4,7 是亚甲基桥。 Standard numbering: carbon 1 and 4 are bridgeheads, 2-3 is one double bond, 5-6 is the other, 7 is the CH or C with substituent. 标准编号:碳 1 和 4 是桥头碳,2-3 是一个双键,5-6 是另一个双键,7 是 CH 或带有取代基的 C。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} With tert-butoxy at 7, it might be electron-donating, so the double bonds could be dienophiles or dienes. 在 7 号位有叔丁氧基时,它可能是给电子基团,所以双键可能是亲二烯体或二烯。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But it’s combined with two equivalents of the other diene, and with NaI at elevated temperature. 但它与另外两种二烯等价物以及高温下的 NaI 结合。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} I think the NaI is used to generate the reactive diene from the bis(dibromomethyl) compound. 我认为 NaI 用于从双(溴甲基)化合物中生成反应性二烯。 So, 5,6-bis(dibromomethyl)cyclohexa-1,3-diene with NaI likely eliminates to form o-quinodimethane or a derivative. 因此,5,6-双(溴甲基)环己-1,3-二烯与 NaI 很可能消除形成邻喹喃或其衍生物。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} In fact, 1,2-bis(dibromomethyl)benzene with NaI gives o-xylylene, which is 1,2- di methylenecyclohexa-3,5-diene or something, but it’s benzene with exocyclic double bonds. 事实上,1,2-二溴甲基苯与 NaI 反应生成邻二甲苯,它是 1,2-二亚甲基环己-3,5-二烯或类似物,但它是带有外环双键的苯。 o-Xylylene is often depicted as having a quinoid structure. o-茚并二烯常被描述为具有喹啉结构。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 1, '视角转换': 2, '视角冲突': 1, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 1, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 1, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But here, the starting material is cyclohexa-1,3-diene, not benzene. 5,6-bis(dibromomethyl)cyclohexa-1,3-diene: if it eliminates two HBr, it could form 5,6- di methylenecyclohexa-1,3-diene, which is the same as o-xylylene because cyclohexa-1,3-diene with exocyclic double bonds at 5 and 6 is equivalent to the quinodimethane for benzene. 但在这里,起始材料是环己-1,3-二烯,而不是苯。5,6-双(二溴甲基)环己-1,3-二烯:如果它消去两个 HBr,它可以形成 5,6-二亚甲基环己-1,3-二烯,这与邻二甲苯相同,因为带有 5 和 6 位外环双键的环己-1,3-二烯与苯的喹喃二甲烷等效。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 3, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提供建议': 0, '5_表示观点': 0, '6_表示方向': 3, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 1, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} 5,6-di methylenecyclohexa-1,3-diene is actually o-xylylene, which is a resonance structure of 1,2- di methylenebenzene or something, but it’s a reactive diene with s-cis conformation for Diels-Alder. 5,6-二甲基环己-1,3-二烯实际上是邻二甲苯,它是 1,2-二甲基苯的一种共振结构,或者是类似物,但它是一种具有 s-顺式构型的反应性二烯,适用于 Diels-Alder 反应。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '视角调和': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 1, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 3, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 1, '4_提出建议': 0, '5_表达观点': 2, '6_提供方向': 3, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Yes, that makes sense. So with NaI, it generates o-xylylene in situ. 是的,这很合理。所以使用 NaI 时,它会原位生成邻二甲苯。 Then, this o-xylylene can act as a diene in Diels-Alder reactions. 然后,这个邻二甲苯可以作为二烯参与 Diels-Alder 反应。 Now, the other compound is 7-(tert-butoxy)norbornadiene. Norbornadiene can act as a dienophile because one of its double bonds can be electron-deficient or something, but with tert-butoxy, it might be electron-rich. 现在,另一种化合物是 7-(叔丁氧基)降冰片二烯。降冰片二烯可以作为亲二烯体,因为其中一条双键可能是缺电子的,但有了叔丁氧基,它可能变得富电子。 Norbornadiene has two double bonds, and it can participate in Diels-Alder as a diene with electron-withdrawing groups, but here it has tert-butoxy, which is electron-donating, so perhaps it’s a poor dienophile. 降冰片二烯有两个双键,它可以作为带有吸电子基团的二烯参与 Diels-Alder 反应,但这里它带有叔丁氧基,叔丁氧基是给电子基团,所以它可能是一个较差的亲二烯体。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 1, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 1, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But it’s combined with two equivalents of the o-xylylene precursor, so likely, the o-xylylene is the diene, and norbornadiene is the dienophile. 但它与两种邻二甲苯前体的等价物结合,所以很可能,邻二甲苯是双烯体,而降冰片二烯是亲双烯体。 Norbornadiene as a dienophile? Typically, it’s symmetric, and one double bond can be attacked. 降冰片烯作为亲二烯体?通常它是对称的,其中一个双键可以被进攻。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 0, '6_给出方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} In Diels-Alder, norbornadiene can act as a dienophile when reacted with dienes. 在 Diels-Alder 反应中,降冰片二烯可以作为亲二烯体与二烯反应。 For example, norbornadiene with cyclopentadiene gives adducts. 例如,降冰片二烯与环戊二烯反应生成加合物。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 3, '6_Gives_orientation': 4, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 0, '5_表达观点': 3, '6_提供方向': 4, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 1, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 1, '反向链': 0} So here, o-xylylene is a good diene, and norbornadiene can be the dienophile. 所以在这里,邻二甲苯是一种好的二烯,而降冰片二烯可以作为亲二烯体。 But there are two equivalents of the o-xylylene precursor, so probably two Diels-Alder reactions occur. 但是邻二甲苯前体有两个等价物,所以可能发生两次 Diels-Alder 反应。 First, one o-xylylene adds to norbornadiene. 首先,一个邻二甲苯加成到降冰片二烯上。 Norbornadiene has two double bonds; when one acts as dienophile, the other might still be reactive. 降冰片二烯有两个双键;当一个作为亲二烯体时,另一个可能仍然具有反应活性。 Perhaps it adds once, and then the adduct has another diene or dienophile. 也许它加成一次,然后加合物还有另一个二烯或亲二烯体。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 0, '5_表达观点': 1, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But with two equivalents, likely two additions. 但有两个等价物,可能有两个新增。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 2, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} The tert-butoxy group might play a role. 叔丁氧基可能起作用。 Perhaps the tert-butoxy is a protecting group or something. 或许叔丁氧基是一个保护基团或类似物。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 2, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 2, 'backward_chaining': 0} Let’s think about the structure. 让我们思考一下结构。 First, o-xylylene generated from 5,6-bis(dibromomethyl)cyclohexa-1,3-diene with NaI: elimination of two HBr gives o-xylylene, which is . 首先,5,6-双(二溴甲基)环己-1,3-二烯与 NaI 反应生成的邻二甲苯:消除两个 HBr 得到邻二甲苯,它是。 Then, this diene adds to the norbornadiene. 然后,这个二烯与降冰片二烯反应。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 1, '视角转换': 2, '视角冲突': 1, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 3, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 1, '5_表达观点': 3, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Norbornadiene, 7-(tert-butoxy), so the double bond might be activated or deactivated. 七元杂环庚烯,7-(叔丁氧基),因此双键可能被活化或失活。 tert-butoxy is electron-donating, so it might make the double bond less reactive as dienophile, but norbornadiene double bonds are strained, so they can still react. 叔丁氧基是给电子基团,因此它可能使双键作为亲二烯体时反应性降低,但七元杂环庚烯的双键是张力化的,所以它们仍然可以反应。 Perhaps the Diels-Alder occurs with o-xylylene as diene and norbornadiene as dienophile. 也许狄尔斯-阿尔德反应是邻二甲苯作为二烯体,七元杂环庚烯作为亲二烯体发生的。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} The adduct would have the norbornene system with a phenyl ring attached, but o-xylylene addition gives a bicyclic system fused to the norbornane. 该加合物将具有一个带苯环连接的降冰片烯系统,但邻二甲苯加成会给出一个与降冰片烷稠合的环系。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 4, ’conflict_of_perspectives': 3, ’reconciliation': 1} 对话行为: {'问答': 0, '视角转换': 4, '视角冲突': 3, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 5, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 1, 'subgoal_setting': 0, 'backward_chaining': 0} In Diels-Alder, o-xylylene with a dienophile gives a 1,2,3,4-tetrahydronaphthalene derivative. 在 Diels-Alder 反应中,邻二甲苯与亲二烯体反应生成 1,2,3,4-四氢萘衍生物。 For example, with ethylene, it gives 1,2-dihydronaphthalene or something. 例如,与乙烯反应,会生成 1,2-二氢萘或类似物质。 o-Xylylene + dienophile → benzocyclobutene or tetrahydronaphthalene, depending on the dienophile. o-二苯甲烯 + 炔烃 → 根据炔烃的不同,生成苯并环丁烯或四氢萘。 Standard Diels-Alder: o-xylylene has the diene system in the exocyclic bonds, so it adds to dienophiles to form bicyclic compounds with a benzene ring. 标准 Diels-Alder 反应:o-二苯甲烯的共轭体系位于外环键上,因此它与炔烃加成形成含有苯环的双环化合物。 Specifically, with a mono-olefin, it gives 1,4-dihydronaphthalene, which can aromatize. 具体来说,与单烯烃反应生成 1,4-二氢萘,该化合物可以芳构化。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} But in this case, the dienophile is norbornadiene, which is a bicyclic diene. 但在此情况下,亲二烯体是降冰片二烯,它是一种双环二烯。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0}
IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0}
Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} So, one o-xylylene adds to one double bond of norbornadiene. 所以,一个邻二甲苯加到一个双键的降冰片二烯上。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 1, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 1, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 1, 'backward_chaining': 0} The adduct would have a norbornene-like structure with a fused benzene ring or something. 该加合物将具有类似降冰片烯的结构,带有稠合的苯环或类似物。 Let’s sketch it. 我们来画一下。 Norbornadiene has double bonds at 2-3 and 5-6. Suppose the dienophile is the 2-3 double bond. After Diels-Alder with o-xylylene, the o-xylylene adds across, so the adduct has the norbornane skeleton with a new ring fused, but since o-xylylene adds as a diene, it becomes a benzo-fused norbornene. 降冰片二烯在 2-3 位和 5-6 位有双键。假设亲二烯体是 2-3 位的双键。与邻二甲苯进行 Diels-Alder 反应后,邻二甲苯会跨接加成,因此加合物具有降冰片烷骨架,并与一个新环稠合,但由于邻二甲苯作为二烯加成,它变成了稠合苯的降冰片烯。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提建议': 0, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} o-Xylylene is like a 1,3-diene with substituents, so when it adds to a dienophile, it forms a 6-membered ring with the dienophile part. o-二苯乙烯类似于带有取代基的 1,3-二烯烃,所以当它与二烯体反应时,会形成含有二烯体部分的六元环。 For example, if dienophile is ethylene, it forms 1,2,3,4-tetrahydronaphthalene, which has a double bond. 例如,如果二烯体是乙烯,它会形成具有双键的 1,2,3,4-四氢萘。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 2, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 2, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 3, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_显示团结': 0, '2_显示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 0, '5_表达观点': 0, '6_提供方向': 3, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_显示紧张': 1, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Similarly, with norbornadiene, if we consider one double bond as dienophile, say the 2-3 bond, then after addition, we have a new 6-membered ring fused to the norbornane at positions 2 and 3, so it’s like a benzonorbornene with a double bond at 5-6 still present. 同样地,对于降冰片二烯,如果我们考虑其中一个双键作为亲二烯体,比如 2-3 键,那么在加成后,会形成一个新的六元环与降冰片烷在 2 和 3 位融合,所以它就像一个带有 5-6 双键的苯并降冰片烯。 Norbornadiene has carbons: bridgehead 1 and 4, double bond between 2-3, double bond between 5-6, and 7 is the bridge. 降冰片二烯有碳原子:桥头 1 和 4,2-3 之间的双键,5-6 之间的双键,7 是桥。 If 2-3 acts as dienophile, adding o-xylylene, the adduct has a benzene ring fused between C2 and C3 of the norbornane, but since C2 and C3 were double-bonded, after addition, it’s single bond, and the new ring is aromatic or something. 如果 2-3 作为亲二烯体,加入邻二甲苯,加合物在降冰片烷的 C2 和 C3 之间有一个苯环融合,但由于 C2 和 C3 原本是双键,加成后变为单键,新形成的环是芳香族或类似物。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 0, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} In Diels-Alder, o-xylylene adds to give a non-aromatic product initially, like 1,4-dihydronaphthalene, which can aromatize if there’s a double bond or something. 在 Diels-Alder 反应中,邻二甲苯加成生成非芳香产物,如 1,4-二氢萘,如果存在双键或类似结构,该产物可以芳香化。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 1, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But in this case, with norbornadiene, the adduct might have the double bond at 5-6 still, so it could be a diene still. 但在这个情况下,对于降冰片二烯,加合物可能在 5-6 位仍有双键,所以它可能仍然是一个二烯。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问题与回答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 3, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 0, '6_提供方向': 3, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Then, with a second equivalent of o-xylylene, it could add to the remaining double bond at 5-6. 然后,用另一种邻二甲苯等价物,它可以加成到 5-6 处的剩余双键上。 So, after two Diels-Alder additions, we have a molecule with two benzene rings fused to the norbornane system. 所以,经过两次 Diels-Alder 加成反应后,我们得到一个分子,其中两个苯环与降冰片烷体系稠合。 Specifically, one fused at 2-3 and one at 5-6. 具体来说,一个在 2-3 位稠合,一个在 5-6 位稠合。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 2, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 1, '5_表达观点': 2, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 1, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} In norbornadiene, positions 2-3 and 5-6 are symmetric, so adding o-xylylene to each double bond would give a symmetric molecule. 在降冰片二烯中,2-3 位和 5-6 位是对称的,因此在每个双键上添加邻二甲苯会得到对称分子。 The tert-butoxy is at position 7, which is the bridge carbon, so it might not affect symmetry. 叔丁氧基位于 7 位,是桥碳,所以可能不会影响对称性。 So product 1 should be 7-(tert-butoxy)-1,4-dihydro-1,4-epoxynaphthalene or something, but let’s think. 所以产物 1 应该是 7-(叔丁氧基)-1,4-二氢-1,4-环氧萘或类似物,但让我们再想想。 |
|
| 5 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_显示团结': 0, '2_显示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 1, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_显示紧张': 0, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} After Diels-Alder, each addition of o-xylylene to a double bond of norbornadiene gives a 1,4-dihydronaphthalene fused to norbornane, but since the double bond is part of the norbornane, it’s better to think of the norbornane double bond as the dienophile. 迪尔斯-阿尔德反应后,每向降冰片二烯的双键中添加邻二甲苯都会生成与降冰片烷稠合的 1,4-二氢萘,但由于双键是降冰片烷的一部分,最好将降冰片烷的双键视为亲二烯体。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 5, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 2, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 1, '6_提供方向': 5, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 2, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Standard way: the adduct of norbornadiene and o-xylylene at one double bond gives a compound where the norbornene has a benzo group fused, meaning a benzene ring fused to the 2,3-bond, so it’s 2,3-benzo-5-norbornene or something. 标准方法:在双键上使降冰片二烯和邻二甲苯加成,得到一个化合物,其中降冰片烯与苯基稠合,即苯环与 2,3 键稠合,所以是 2,3-苯并-5-降冰片烯或类似物。 Then, the remaining double bond at 5-6 can add another o-xylylene, giving 2,3:5,6-dibenzo derivative. 然后,5-6 处的剩余双键可以再添加一个邻二甲苯,得到 2,3:5,6-二苯并衍生物。 And since norbornadiene is symmetric, the dibenzo derivative should be symmetric. 而且由于降冰片二烯是对称的,所以二苯并衍生物也应该是对称的。 Position 7 has tert-butoxy. 位置 7 上有叔丁氧基。 So product 1 is 7-(tert-butoxy)bicyclo[2.2.1]hept-5-ene-2,3:5,6-di(benzo) or something, but benzo means fused benzene. 因此产物 1 是 7-(叔丁氧基)双环[2.2.1]庚-5-烯-2,3:5,6-二(苯并)或类似物,但苯并意味着稠合苯。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 0, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 1, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 0, '6_给出方向': 0, '7_询问方向': 1, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 1, '11_展示紧张': 1, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 1, '回溯': 1, '子目标设定': 0, '反向链': 0} Actually, it’s 7-(tert-butoxy)-1,4-dihydro-1,4-epoxynaphthalene derivative? No. 实际上,是 7-(叔丁氧基)-1,4-二氢-1,4-环氧萘衍生物吗?不。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 3, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 3, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 2, '5_Gives_opinion': 2, '6_Gives_orientation': 7, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 2, '5_表达观点': 2, '6_提供方向': 7, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 2, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 2, '反向链': 0} Perhaps it’s 7-tert-butoxy-1,4-epoxy-5,8-dihydronaphthalene or something. I need to name it properly. 或许可能是 7-叔丁氧基-1,4-环氧-5,8-二氢萘,或者类似的东西。我需要正确命名它。 The fused system: after Diels-Alder, for each addition, the o-xylylene becomes a benzene ring fused, with the norbornane double bond becoming single bond in a cyclohexene ring. 融合系统:经过 Diels-Alder 反应后,每次加成反应中,邻二甲苯会变成与苯环融合的环,而降冰片烯的双键会变成环己烯环中的单键。 For one addition: norbornadiene has double bond at 2-3. When it to o-xylylene, o-xylylene is the diene, so the dienophile double bond (2-3) becomes single bond, and a new six-member ring is formed, fused to positions 2 and 3. Since positions 2 and 3 were part of the five-member ring in norbornane, now it’s a fused system with a benzene ring. 对于一次加成:降冰片二烯在 2-3 位置有双键。当它与邻二甲苯反应时,邻二甲苯作为二烯体,因此二烯体的双键(2-3)会变成单键,并形成一个新的六元环,与 2-3 位置融合。由于 2-3 位置原本是降冰片烷五元环的一部分,现在它变成了与苯环融合的系统。 Specifically, the adduct is a benzofused norbornene, with the double bond at 5-6 still present. 具体来说,加成产物是苯并融合的降冰片烯,5-6 位置的双键仍然存在。 Then, the second o-xylylene adds to the 5-6 double bond, similarly, forming another benzene ring fused at 5-6. 然后,第二分子邻二甲苯加成到 5-6 双键上,同样地,形成另一个与 5-6 位置融合的苯环。 So the final adduct for product 1 is a molecule where the norbornane skeleton has benzene rings fused to both "sides", and the bridge carbon 7 has tert-butoxy. 所以最终产物 1 的加合物是一种分子,其中诺尔 bornane 骨架的两侧都有苯环稠合,而桥碳 7 上有叔丁氧基。 Moreover, since the fusions are at the former double bond positions, the norbornane is now like a central bicyclic system with two benzene rings attached via the fusion. 此外,由于稠合发生在原来的双键位置,诺尔 bornane 现在就像一个通过稠合连接两个苯环的中心双环系统。 In terms of the carbon skeleton, it’s like 9,10-dihydro-9,10[1',2']benzenoanthracene or something, but let’s think. 从碳骨架的角度来看,它类似于 9,10-二氢-9,10[1',2']苯并蒽,但让我们思考一下。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} Actually, it’s similar to the Diels-Alder adduct of two molecules of o-xylylene with norbornadiene, so the product is a cage-like molecule with two benzene rings. 实际上,这类似于邻二甲苯与降冰片二烯形成的 Diels-Alder 加合物,因此产物是一个含有两个苯环的笼状分子。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'question_and_answering': 0, 'perspective_shift': 0, 'conflict_of_perspectives': 0, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 3, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} The norbornane part has carbons 1,4,7 and the bridges. 降冰片烷部分包含碳原子 1、4、7 和桥键。 After fusion at 2-3 and 5-6, positions 2,3,5,6 are now sp3 carbons part of the fused rings. 在 2-3 和 5-6 处融合后,位置 2、3、5、6 现在是稠环的一部分的 sp3 碳原子。 Each fusion adds a benzene ring, so the molecule has three rings: the norbornane core with two benzene rings fused. 每个融合增加一个苯环,因此分子有三个环:由两个苯环融合而成的诺勃烷核心。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_显示团结': 0, '2_显示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_显示紧张': 0, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But norbornane is bicyclic, so with two fusions, it becomes polycyclic. 但双环戊烷是双环的,所以有两个融合,它就变成了多环的。 Perhaps it’s 1,4,4a,8a-tetrahydro-1,4-methanoanthracene or something. 也许它是 1,4,4a,8a-四氢-1,4-甲烷蒽,或者类似的东西。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 0, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} I recall that the Diels-Alder adduct of norbornadiene and two equivalents of o-xylylene is a known compound, and it’s symmetric. 我记得那 norbornadiene 和两当量 o-xylylene 的 Diels-Alder 加合物是一种已知化合物,而且它是对称的。 In fact, it’s called 1,4,4a,8a-tetrahydro-1,4:5,8-diepoxyanthracene or something, but with the epoxymethano bridge. 事实上,它叫做 1,4,4a,8a-四氢-1,4:5,8-二环氧蒽,或者类似的名字,但带有环氧甲桥。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} The central part is the norbornane with the 1,4-methano bridge, and fused to anthracene-like system. 核心部分是带有 1,4-甲烷桥的降冰片烷,并与类似蒽的系统融合。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Anthracene has three rings linear, but here it’s different. 蒽有三个环线性,但这里不同。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} After Diels-Alder, the o-xylylene adds to form a new six-member ring, so for each addition, it’s like adding a benzene ring fused to the norbornane double bond. 迪尔斯-阿尔德反应后,邻二甲苯会加成形成一个新的六元环,因此每次加成都相当于在降冰片烯双键上加上一个与苯环稠合的环。 So for norbornadiene, after two additions, we have a molecule where the two double bonds are now part of two fused benzene rings, and the norbornane bridge is present. 所以对于降冰片二烯来说,经过两次加成后,我们得到一个分子,其中两个双键现在成为两个稠合的苯环的一部分,同时保留了降冰片烯桥。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Specifically, it’s 1,4,4a,8a-tetrahydro-1,4-methanonaphthalene for one addition, but with two, it’s symmetric. 具体来说,对于一种加成反应,它是 1,4,4a,8a-四氢-1,4-甲酮萘,但有两种时它是对称的。 The compound is known as the adduct where norbornadiene is the dienophile for two o-xylylenes, forming a cage molecule. 该化合物被称为加合物,其中降冰片二烯作为两个邻二甲苯的亲二烯体,形成了一个笼状分子。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_显示紧张': 1, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} I think it: the product is 1,4,4a,5,8,8a,9,10-octahydro-1,4:5,8-diepoxyanthracene or something. 我认为:产品是 1,4,4a,5,8,8a,9,10-八氢-1,4:5,8-二环氧蒽或类似物。 |
|
| 5 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 1, '5_表达观点': 0, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Perhaps it’s easier to think that the final structure has the norbornane skeleton with C1 and C4 as bridgeheads, C7 with tert-butoxy, and at C2-C3 and C5-C6, instead of double bonds, there are benzene rings fused, meaning that C2 and C3 are now part of a benzene ring fused between them, similarly for C5 and C6. 也许更容易想象最终结构具有降冰片烷骨架,C1 和 C4 作为桥头,C7 带有叔丁氧基,而在 C2-C3 和 C5-C6 处,不是双键,而是融合的苯环,这意味着 C2 和 C3 现在是它们之间融合的苯环的一部分,C5 和 C6 也是类似情况。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1 显示团结': 0, '2 显示紧张释放': 0, '3 同意': 0, '4 提建议': 0, '5 表达观点': 0, '6 提供方向': 1, '7 询问方向': 0, '8 询问观点': 0, '9 询问建议': 0, '10 反对': 0, '11 显示紧张': 0, '12 显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} In the fusion, for example, when a benzene ring is fused to the 2,3-bond, it means that C2 and C3 become part of the benzene ring, so they are sp2 carbons in benzene. 在融合中,例如,当一个苯环与 2,3 键融合时,这意味着 C2 和 C3 成为苯环的一部分,因此在苯环中它们是 sp2 碳。 |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 2, ’reconciliation': 0} 会话行为:{'问答': 0, '视角转换': 1, '视角冲突': 2, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 2, '6_给出方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} In Diels-Alder of o-xylylene with a dienophile, the initial adduct is 1,4-dihydronaphthalene, which can aromatize if there is a way to lose hydrogen, but in this case, with norbornadiene, the adduct might not aromatize immediately because the norbornane part is aliphatic. 在邻二甲苯与二烯体的 Diels-Alder 反应中,初始加合物是 1,4-二氢萘,如果存在失去氢的途径,它可以芳构化,但在这种情况下,与降冰片二烯反应时,加合物可能不会立即芳构化,因为降冰片烷部分是脂肪族的。 For example, if the dienophile is ethylene, the adduct is 1,2,3,4-tetrahydronaphthalene, which has a double bond and can be oxidized to naphthalene. 例如,如果二烯体是乙烯,加合物是 1,2,3,4-四氢萘,它含有双键,可以被氧化成萘。 But here, with norbornadiene, the adduct has the norbornane fused, so it might not have a double bond to aromatize easily. 但这里,与降冰片二烯反应时,加合物具有与降冰片烷稠合的结构,因此可能没有容易芳构化的双键。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '视角调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 2, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 2, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 2, 'backward_chaining': 0} In the first step, with NaI at elevated temperature, it might promote aromatization. 第一步,在较高温度下,NaI 可能会促进芳构化。 But let’s see the sequence. 但让我们看看这个序列。 Product 1 is formed from the combination. 产品 1 由该组合形成。 Then it is treated with aqueous sulfuric acid, which might remove the tert-butoxy group. 然后它被水合硫酸处理,这可能去除叔丁氧基。 |
DeepSeek-R1: Creative Sentence Rewriting
DeepSeek-R1:创意句子改写
| Perspective ID 视角 ID | Utterance 话语 | |
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 0, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} We are going to rewrite the sentence "I flung my hatred into the burning fire." 我们将重写句子"I flung my hatred into the burning fire." The original sentence uses the verb "flung" which is the past tense of "fling", meaning to throw or hurl something with vigor. 原句使用了动词"flung",它是"fling"的过去式,意为用力扔或投掷某物。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 会话行为:{'’question_and_answering': 0, '’perspective_shift': 0, '’conflict_of_perspectives': 0, '’reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向推理': 0} We are to rewrite the sentence, meaning we can change the same idea with different words but keep the same meaning. 我们需要重写这个句子,意思是我们可以用不同的词语表达同一个意思,但保持意思不变。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 5, '5_Gives_opinion': 2, '6_Gives_orientation': 4, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 5, '5_给出观点': 2, '6_给出方向': 4, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 4, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 4, '反向链': 0} Let’s consider: 让我们考虑: - "I" is the subject. - "我"是主语。 - "flung" can be replaced with synonyms: threw, hurled, cast, tossed, etc. - "flung"可以用同义词替换:threw, hurled, cast, tossed 等。 - "my hatred" is the direct object. We can rephrase "hatred" as "anger", "rage", "animosity", but "hatred" is strong and specific. Alternatively, we can use a metaphor or a different expression for the emotion. - "my hatred"是直接宾语。我们可以将"hatred"改写为"anger"、"rage"、"animosity",但"hatred"更强烈且具体。或者,我们可以使用比喻或不同的表达方式来描述这种情绪。 - "into the burning fire" is the destination. We can change "burning fire" to just "fire" because fire is burning by nature, but we can also use "blazing", "raging", "fiery", etc. - "into the burning fire"是目的地。我们可以将"burning fire"改为"fire",因为火本身就在燃烧,但也可以使用"blazing"、"raging"、"fiery"等词。 |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'’question_and_answering': 0, '’perspective_shift': 0, '’conflict_of_perspectives': 1, '’reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} However, note that the instruction is to rewrite the sentence, so we must produce a new sentence that conveys the same meaning. 然而,请注意指示是要重写句子,因此我们必须生成一个表达相同意思的新句子。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 3, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 3, '5_给出观点': 0, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Possible rewrites: 可能的改写: 1. "I threw my hatred into the blazing fire." 1. "我把我的仇恨投入了熊熊烈火。" 2. "I cast my hatred into the flames." 2. "我把我的仇恨投入了火焰。" 3. "I hurled my animosity into the raging fire." 3. "我将我的敌意投入熊熊烈火中。" |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 2, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提供建议': 2, '5_表示观点': 1, '6_表示方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 1, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 1, '反向链': 0} But note: the original uses "burning fire", which is a bit redundant because fire is burning. We can simplify to "fire" or use a more descriptive word. 但请注意:原文使用"燃烧的火焰",这略显重复,因为火焰本身就是燃烧的。我们可以简化为"火焰",或者使用更描述性的词语。 Let’s choose one that is both poetic and clear. 让我们选择一个既诗意又清晰的表达。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 1, '5_表达观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Option: "I cast my hatred into the fire." (removing "burning" as redundant, and "cast" is a synonym for "flung" in a poetic sense) 选项:"我将我的仇恨投入火中。"(移除"燃烧"因冗余,"cast"在诗意中是"flung"的同义词) |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_显示团结': 0, '2_显示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 1, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_显示紧张': 0, '12_显示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} However, to keep the intensity, we might want to keep an adjective. Let’s try: 然而,为了保持强度,我们可能需要保留一个形容词。让我们试试: |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 1} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 0, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 1} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} "I hurled my hatred into the fiery blaze." "我将我的仇恨投入了熊熊烈火。" |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 0, '5_表达观点': 0, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向推理': 0} But note: "blaze" is a synonym for fire, so we can say: 但请注意:"blaze"是"fire"的同义词,因此我们可以说: |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 1} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 0, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 1} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} "I hurled my hatred into the blazing fire." (similar to the original) "我将我的仇恨投入熊熊烈火中。"(与原文相似) |
|
| 5 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 1, '6_给出方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} Alternatively, we can use a different structure: 或者,我们可以使用不同的结构: "Into the burning fire, I flung my hatred." (inversion, but that’s just reordering) "投入熊熊烈火,我抛掷我的憎恨。"(倒装,但那只是重新排序) |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Since the instruction is to rewrite, we can change words and structure as long as the meaning remains. 由于指令是重写,我们可以改变词语和结构,只要意思保持不变。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} Let me choose: "I cast my deep-seated hatred into the roaring flames." 让我选择:"我将深藏的仇恨投入熊熊烈火。" |
|
| 6 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为: {'question_and_answering': 0, 'perspective_shift': 0, 'conflict_of_perspectives': 1, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 1, '回溯': 1, '子目标设定': 0, '反向推理': 0} But that adds "deep-seated" which wasn’t in the original. We should avoid adding new ideas. 但这增加了"根深蒂固"这个词,而原文中并没有。我们应该避免添加新观点。 |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 1} 对话行为: {'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} So, let’s stick to the original meaning without adding extra adjectives. 所以,让我们坚持原意,不要添加额外的形容词。 |
|
| 5 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'question_and_answering': 0, 'perspective_shift': 1, 'conflict_of_perspectives': 0, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 1, 'subgoal_setting': 0, 'backward_chaining': 0} Another idea: "My hatred I flung into the burning fire." (inversion) 另一个想法:"我把我的仇恨抛进了燃烧的火焰。"(倒装) |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为: {'question_and_answering': 0, 'perspective_shift': 0, 'conflict_of_perspectives': 1, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} But the instruction doesn’t specify that we must change the structure, so we can keep the same structure. 但指令没有指定我们必须改变结构,所以我们可以保持相同结构。 |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'question_and_answering': 1, 'perspective_shift': 0, 'conflict_of_perspectives': 0, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 1, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} I think a good rewrite is: "I hurled my hatred into the flames." 我认为一个更好的改写是:"我将我的仇恨投入火焰。" Why? 为什么? - "hurled" is a strong synonym for "flung". - "hurled"是"flung"的一个强烈同义词。 - "flames" is a synonym for "burning fire", and it avoids the redundancy of "burning fire". - "flames"是"burning fire"的同义词,并且避免了"burning fire"的冗余。 |
|
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{’提问与回答’: 1, ’视角转换’: 1, ’视角冲突’: 1, ’和解’: 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 1, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 1, '回溯': 0, '子目标设定': 0, '反向推理': 0} However, let’s check: "flames" are the visible, gaseous part of a fire, so it’s appropriate. 然而,让我们检查一下:"flames"是火的可见、气态部分,所以是合适的。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 0, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Alternatively, we can use: "I threw my hatred into the fire." 或者,我们可以使用:"我把我的仇恨投入了火中。" |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 1, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} But that might be too plain. 但这可能过于平淡。 Considering the original has a dramatic tone, let’s keep it dramatic. 考虑到原文具有戏剧性风格,我们保持其戏剧性。 |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 1} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} Final choice: "I cast my hatred into the blazing inferno." 最终选择:"我将我的仇恨投入熊熊烈火。" |
|
| 6 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为: {'question_and_answering': 1, 'perspective_shift': 1, 'conflict_of_perspectives': 1, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 1, '回溯': 0, '子目标设定': 0, '反向推理': 0} But note: an inferno" is a large fire that is dangerously out of control. That might be too strong? The original just says "burning fire". 但请注意:"inferno"指的是失控的大火,非常危险。这可能过于强烈?原文只是说"燃烧的火"。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} Alternatively, we can use: "I flung my animosity into the fire." (using "animosity" for "hatred") 或者,我们可以使用:"我把我的敌意扔进了火里。"(使用"animosity"代替"hatred") |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为: {'问答': 0, '视角转换': 0, '视角冲突': 1, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} However, the instruction says "rewrite", so we can change the verb and the noun for fire, but we should not change the core meaning. 然而,指令要求"重写",因此我们可以改变火的动词和名词,但我们不应改变其核心含义。 |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 1} 对话行为: {'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 1, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 1, 'backward_chaining': 0} I think the safest is to replace "flung" with a synonym and keep the rest: 我认为最安全的是将"flung"替换为同义词,其余保持不变: |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'question_and_answering': 0, 'perspective_shift': 0, 'conflict_of_perspectives': 0, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 1} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} "I hurled my hatred into the burning fire." "我将我的仇恨投入燃烧的火焰。" |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} But we can also remove the redundancy: 但我们也可以去除冗余: |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为: {'question_and_answering': 0, 'perspective_shift': 1, 'conflict_of_perspectives': 0, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} "I hurled my hatred into the fire." "我把我的仇恨投入了火中。" Or, to keep the intensity: "I hurled my hatred into the blazing fire." 或者保持强度:"我把我的仇恨投入了熊熊燃烧的火中。" |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 2, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 2, '5_Gives_opinion': 2, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 2, '5_表达观点': 2, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 1, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} Wait, that’s not a word. Let me correct: "blaze" or "flames". 等等,这不是一个词。让我更正:是"flame"或者"flames"。 I think the best is: "I hurled my hatred into the flames." 我认为最好的是:"我把我的仇恨投入火焰中。" But let’s see if we can use "burning" in a different way? Maybe not necessary. 但我们看看是否可以用"burning"以不同的方式使用?也许不必要。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 2, ’perspective_shift': 5, ’conflict_of_perspectives': 5, ’reconciliation': 3} 会话行为:{'’question_and_answering': 2, '’perspective_shift': 5, '’conflict_of_perspectives': 5, '’reconciliation': 3} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 10, '5_Gives_opinion': 5, '6_Gives_orientation': 5, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 1, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 10, '5_Gives_opinion': 5, '6_Gives_orientation': 5, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 1, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 3, ’backtracking': 4, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 3, '回溯': 4, '子目标设定': 0, '反向链': 0} Alternatively, we can use: "I threw my hatred into the fire." 或者我们可以使用:"我把我的仇恨投入了火中。" But that might be too plain. 但这可能过于平淡。 Considering the original has a dramatic tone, let’s keep it dramatic. 考虑到原文具有戏剧性风格,让我们保持这种戏剧性。 Final choice: "I cast my hatred into the blazing inferno." 最终选择:"我将我的仇恨投入熊熊烈火。" But note: an inferno" is a large fire that is dangerously out of control. That might be too strong? The original just says "burning fire". 但请注意:"inferno"指的是失控的大火,可能过于强烈?原文只是说"燃烧的火焰"。 Alternatively, we can use: "I flung my animosity into the fire." (using "animosity" for "hatred") 或者我们可以使用:"我将我的敌意投入火焰。"(使用"animosity"代替"hatred") However, the instruction says "rewrite", so we can change the verb and the noun for fire, but we should not change the core meaning. 然而,指示要求"改写",所以我们可以在动词和火相关的名词上做改变,但不应改变核心含义。 I think the safest is to replace "flung" with a synonym and keep the rest: 我认为最安全的是将"flung"替换为同义词,其余部分保持不变: "I hurled my hatred into the burning fire." "我把我的仇恨扔进了燃烧的火焰。" But we can also remove the redundancy: 但我们也可以删除冗余: "I hurled my hatred into the fire." "我把我的仇恨扔进了火焰。" Or, to keep the intensity: "I hurled my hatred into the blazing fire." 或者保持强度:"我将我的仇恨投入熊熊烈火中。" Wait, that’s not a word. Let me correct: "blaze" or "flames". 等等,那不是个词。让我更正:是"flame"或"flames"。 I think the best is: "I hurled my hatred into the flames." 我认为最好的是:"我将我的仇恨投入火焰中。" But let’s see if we can use "burning" in a different way? Maybe not necessary. 但让我们看看是否可以用"burning"以不同方式使用?也许不必要。 Alternatively, we can use: "I threw my hatred into the roaring fire." 或者我们可以使用:"我把我的仇恨扔进了熊熊燃烧的火焰里。" |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 1, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 1, '4_提建议': 1, '5_表达观点': 0, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 0, '12_表示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向推理': 0} I think that’s acceptable. 我认为可以接受。 However, to be safe, I’ll go with: "I cast my hatred into the fire." 不过为了安全起见,我选择说:"我把我的仇恨投入火中。" |
|
| 4 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 1, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 0, '12_表示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向推理': 0} But note: "cast" can be less forceful than "flung". So let’s use "hurled". 但请注意:"投射"可能比"抛掷"力度弱。所以让我们用"投掷"。 |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 1} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 1} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_给出建议': 0, '5_给出观点': 1, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 1} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向推理': 0} Final decision: "I hurled my hatred into the flames." 最终决定:"我将我的仇恨投入火焰。" |
|
| 6 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 1} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 0, '和解': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 2, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} But the original says "burning fire", so if we change to "flames", it’s acceptable because flames are part of a burning fire. 但原文说的是"燃烧的火焰",所以如果我们改为"火焰",这是可以接受的,因为火焰是燃烧火焰的一部分。 |
|
| 3 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 0, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向推理': 0} Alternatively, we can write: "I flung my hatred into the flames." (just changing "burning fire" to "flames") 或者我们可以这样写:"我把我的仇恨抛进了火焰中。"(只是把"燃烧的火焰"改成了"火焰") |
|
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 2, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示敌对': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} That is also a rewrite. 这也是一个重写。 Since the instruction does not specify how much to change, I can do that. 由于指令没有指定修改的程度,我可以这样做。 But the problem says "rewrite", so any change that preserves meaning is acceptable. 但问题中说“重写”,所以任何保留原意的变化都是可以接受的。 |
|
| 7 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问题与回答': 0, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 0, '5_表达观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} I will choose: "I hurled my hatred into the flames." 我将选择:"我将我的仇恨投入火焰。" Let me write the response accordingly. 让我相应地写出回答。 |
DeepSeek-V3: Chemistry DeepSeek-V3: 化学
| Perspective ID 视角 ID | Personality 个性 | Domain Expertise 领域专业知识 |
| 1 | {’E': 1.5, ’A': 3.5, ’C': 5.0, ’N': 2.0, ’O': 3.5} |
Expertise in creative writing and linguistic analysis. The agent’s cognitive function is to deconstruct a sentence, generate alternative phrasings by considering synonyms and connotations, critically evaluate redundancy, and synthesize a revised sentence based on criteria like emotional intensity and vivid imagery. 在创意写作和语言分析方面的专业知识。该代理的认知功能是分解句子,通过考虑同义词和内涵生成替代性措辞,批判性地评估冗余,并根据情感强度和生动意象等标准综合修改句子。 |
| Perspective ID 视角 ID | Utterance 话语 | |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 0, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 12, '6_Gives_orientation': 5, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_表示同意': 0, '4_提出建议': 1, '5_表达观点': 12, '6_提供方向': 5, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_表示反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 5, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 5, '反向推理': 0} To determine the number of chemically distinct hydrogen atoms in the final product (4), let’s analyze the reaction sequence step-by-step: 要确定最终产物(4)中化学上不同的氢原子数量,让我们逐步分析反应序列: |
|
|
### Step 1: Formation of Product 1 ### 第一步:产物 1 的形成 1. **Starting Material**: 7-(tert-butoxy)bicyclo[2.2.1]hepta-2,5-diene reacts with 2 equivalents of 5,6-bis(dibromomethyl)cyclohexa-1,3-diene and NaI at elevated temperature. 1. **起始材料**:7-(叔丁氧基)双环[2.2.1]庚-2,5-二烯与 2 当量的 5,6-双(二溴甲基)环己-1,3-二烯在高温下与 NaI 反应。 - The reaction likely involves a Diels-Alder cycloaddition or a substitution reaction where the tert-butoxy group is replaced or modified. The exact structure of **1** is unclear, but it likely forms a complex polycyclic system. - 该反应可能涉及 Diels-Alder 环加成反应或取代反应,其中叔丁氧基被取代或修饰。**1**的确切结构尚不清楚,但它可能形成复杂的杂环系统。 ### Step 2: Formation of Product 2 ### 第 2 步:产物 2 的形成 2. **Aqueous H2SO4 Treatment**: Hydrolysis of **1** removes the tert-butoxy group, possibly forming a hydroxyl group or exposing a double bond. The structure of **2** is still complex but may involve a diene or alcohol functionality. 2. **水合硫酸处理**:**1**的水解会去除叔丁氧基,可能形成羟基或暴露双键。**2**的结构仍然复杂,但可能涉及二烯或醇官能团。 ### Step 3: Formation of Product 3 ### 第 3 步:产物 3 的形成 3. **SO3 and Pyridine in DMSO**: This is a sulfonation or oxidation step, likely introducing a sulfonyl or sulfonate group. The structure of **3** may now include a sulfone or sulfonic acid derivative. 3. **SO3 和吡啶在 DMSO 中**:这是一个磺化或氧化步骤,可能引入磺酰基或磺酸盐基团。**3**的结构现在可能包括砜或磺酸衍生物。 ### Step 4: Formation of Product 4 ### 第 4 步:产物 4 的形成 4. **Heating at 150°C**: This step could involve elimination, rearrangement, or further cyclization. The final product (**4**) is likely a highly symmetric polycyclic aromatic or conjugated system due to the high-temperature conditions. 4. **150°C 加热**:这一步可能涉及消除、重排或进一步环化。由于高温条件,最终产物(**4**)很可能是一种高度对称的多环芳烃或共轭体系。 ### Symmetry and Distinct Hydrogens ### 对称性与不同氢 - The final product is likely a symmetric, rigid polycyclic structure (e.g., a naphthalene or anthracene derivative with substituents). - 最终产物可能是一种对称的刚性多环结构(例如,带有取代基的萘或蒽衍生物)。 - Given the symmetry and the nature of the transformations, the number of chemically distinct hydrogens is likely **8**. This is because: - 考虑到对称性和变换的性质,化学上不同的氢原子数量可能是 **8**。这是因为: - Aromatic systems with symmetric substitution patterns reduce the number of distinct hydrogens. - 具有对称取代模式的芳香系统会减少不同氢原子的数量。 - The substituents (e.g., sulfonyl groups) may further reduce the symmetry, but 8 is a reasonable estimate based on the complexity of the correct answer is **(B) 8**. - 取代基(例如磺酰基)可能会进一步降低对称性,但基于正确答案的复杂性,8 是一个合理的估计,正确答案是 **(B) 8**。 |
DeepSeek-V3: Creative Sentence Rewriting
DeepSeek-V3: 创意句子改写
| Perspective ID 视角 ID | Personality 性格 | Domain Expertise 领域专业知识 |
| 1 |
{’E': 2.0, ’A': 3.0, ’C': 5.0, ’N': 2.0, ’O': 5.0} {'E': 2.0, 'A': 3.0, 'C': 5.0, 'N': 2.0, 'O': 5.0} |
Expertise in creative writing and linguistic analysis. The agent’s cognitive function is to deconstruct a sentence, generate alternative phrasings by considering synonyms and connotations, critically evaluate redundancy, and synthesize a revised sentence based on criteria like emotional intensity and vivid imagery. 在创意写作和语言分析方面的专业知识。该代理的认知功能是分解句子,通过考虑同义词和内涵生成替代性措辞,批判性地评估冗余,并根据情感强度和生动意象等标准综合修订句子。 |
| Perspective ID 视角 ID | Utterance 话语 | |
| 1 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 2, ’conflict_of_perspectives': 1, ’reconciliation': 1} 对话行为:{'问答': 0, '视角转换': 2, '视角冲突': 1, '调和': 1} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 3, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} To rewrite the sentence ’I flung my hatred into the burning fire,' I considered synonyms and alternative phrasing while maintaining the original meaning and emotional intensity. The verb ’flung' can be replaced with ’hurled' or ’tossed,' and ’hatred' could be substituted with ’anger' or ’rage.' The phrase ’burning fire' is somewhat redundant since fire is inherently burning, so I might simplify it to ’the fire' or ’the flames.' After evaluating these options, I chose ’hurled' for a stronger action and ’flames' for a more vivid image. 为了改写句子“我将我的仇恨投入燃烧的火焰中”,我考虑了同义词和替代表达方式,同时保持了原句的意义和情感强度。动词“flung”可以替换为“hurled”或“tossed”,“hatred”可以替换为“anger”或“rage”。短语“burning fire”有些冗余,因为火本身就燃烧,所以我可能简化为“the fire”或“the flames”。在评估这些选项后,我选择了“hurled”以表达更强的动作,以及“flames”以呈现更生动的画面。 |
Reinforcement Learning Step 40 (Countdown)
强化学习步骤 40(倒计时)
| Perspective ID 视角 ID | Personality 性格 | Domain Expertise 领域专业知识 |
| 1 |
{’E': 2.0, ’A': 3.0, ’C': 5.0, ’N': 2.0, ’O': 1.5} {'E': 2.0, 'A': 3.0, 'C': 5.0, 'N': 2.0, 'O': 1.5} |
A methodical problem-solver focused on enumerating and evaluating arithmetic expressions to solve a numerical puzzle. It prioritizes simplicity and step-by-step logical deduction. 一个系统性的问题解决者,专注于列举和评估算术表达式以解决一个数字谜题。它优先考虑简单性和逐步的逻辑推理。 |
| Perspective ID 视角 ID | Utterance 话语 | |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} Given the numbers [53, 12, 64, 28] and the desired result of 29, I have the following options to consider: 给定数字[53, 12, 64, 28]以及期望的结果 29,我有以下选项可以考虑: 1. 53 - 12 - 3 2. 53 - 12 + 7 3. 53 - 12 * 1 4. 53 - 12 / 4 5. 12 + 28 6. 64 - 12 + 3 7. 64 - 12 - 30 8. 64 - 12 / 4 9. 64 - 12 * 1 10. 64 - 12 + 20 Based on the first two numbers 53 and 12, the simplest equation appears to be 53 - 12. Adding further, I can simplify it by subtracting 3, thereby getting 53 - 12 - 3. 基于前两个数字 53 和 12,最简单的方程似乎是 53 - 12。进一步简化,我可以通过减去 3 来简化它,从而得到 53 - 12 - 3。 |
Reinforcement Learning Step 120 (Countdown)
强化学习步骤 120(倒计时)
| Perspective ID 视角 ID | Personality 个性 | Domain Expertise 领域专业知识 |
| 1 |
{’E': 1.5, ’A': 4.0, ’C': 5.0, ’N': 2.0, ’O': 2.0} {'E': 1.5, 'A': 4.0, 'C': 5.0, 'N': 2.0, 'O': 2.0} |
Domain expertise in basic arithmetic and methodical problem-solving. This agent functions as a diligent calculator and executor, systematically applying a trial-and-error strategy to explore the solution space. 在基础算术和方法性问题解决方面的领域专业知识。该智能体作为一个勤奋的计算器和执行者,系统地应用试错策略来探索解决方案空间。 |
| 2 |
{’E': 2.0, ’A': 3.5, ’C': 4.0, ’N': 2.0, ’O': 3.5} {'E': 2.0, 'A': 3.5, 'C': 4.0, 'N': 2.0, 'O': 3.5} |
Domain expertise in metacognition and logical assessment. This agent functions as an evaluator, stepping back to analyze the results of a process, identify patterns of failure, and form a high-level conclusion about the problem’s solvability. 在元认知和逻辑评估方面的领域专业知识。该智能体作为一个评估者,退一步来分析过程的结果,识别失败的模式,并就问题的可解性形成高级别的结论。 |
| Perspective ID 视角 ID | Utterance 话语 |
| 1 |
Conversational Behaviour: {’question_and_answering': 4, ’perspective_shift': 4, ’conflict_of_perspectives': 4, ’reconciliation': 0} 对话行为:{'问答': 4, '视角转换': 4, '视角冲突': 4, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 2, '5_Gives_opinion': 4, '6_Gives_orientation': 5, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 2, '5_表达观点': 4, '6_提供方向': 5, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 0, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 4, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 4, '回溯': 0, '子目标设定': 0, '反向链': 0} To create an equation that equals 14 using the numbers [3, 56, 66, 44] and each number being used only once, we need to find a combination of these numbers and their arithmetic operations that results in 14. 要用数字[3, 56, 66, 44]中的每个数字各用一次,使等式等于 14,我们需要找到这些数字及其算术运算的组合,使其结果为 14。 Let’s try some combinations: 让我们尝试一些组合: 1. (66 - 56) + 44 - 3 = 14 + 44 - 56 - 3. This does not equal 14. 1. (66 - 56) + 44 - 3 = 14 + 44 - 56 - 3。这不等于 14。 2. 56 - (66 - 3) + 44 = 56 - 63 + 44. This does not equal 14. 2. 56 - (66 - 3) + 44 = 56 - 63 + 44. 这不等于 14。 3. (56 + 66) + 44 - 3 = 112 + 44 - 3. This does not equal 14. 3. (56 + 66) + 44 - 3 = 112 + 44 - 3. 这不等于 14。 4. 56 - 66 + 3 + 44 = -10 + 3 + 44. This equals 37, not 14. 4. 56 - 66 + 3 + 44 = -10 + 3 + 44. 这等于 37,不是 14。 |
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} None of these combinations seem to solve the problem. 这些组合似乎都无法解决问题。 |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为: {'question_and_answering': 1, 'perspective_shift': 1, 'conflict_of_perspectives': 1, 'reconciliation': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 1, 'backtracking': 1, 'subgoal_setting': 0, 'backward_chaining': 0} Let’s try another approach: 让我们尝试另一种方法: 5. (66 + 44) + 56 - 3 = 110 + 56 - 3. This equals 164, not 14. 5. (66 + 44) + 56 - 3 = 110 + 56 - 3。这等于 164,不是 14。 |
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 1, '6_提供方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向链': 0} It seems like we need to rethink our approach. 看来我们需要重新思考我们的方法。 |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 0, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 0, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 1, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 1, '回溯': 0, '子目标设定': 0, '反向链': 0} How about we try a combination like this: 我们试试这种组合怎么样: 6. (3 + 44) + 56 - 66 = 47 + 56 - 66. This equals 37, not 14. 6. (3 + 44) + 56 - 66 = 47 + 56 - 66。这等于 37,不是 14。 |
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 0, '6_Gives_orientation': 0, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_给出建议': 0, '5_给出观点': 0, '6_给出方向': 0, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 0, '11_表示紧张': 1, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 0, '子目标设定': 0, '反向链': 0} We are still not finding a solution. 我们仍然没有找到解决方案。 |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 2, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_提出建议': 1, '5_表达观点': 0, '6_提供方向': 2, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 1, '回溯': 1, '子目标设定': 0, '反向链': 0} Let’s try another combination: 让我们再尝试另一种组合: 7. 44 + (66 + 56) - 3 = 44 + 122 - 3. This equals 163, not 14. 7. 44 + (66 + 56) - 3 = 44 + 122 - 3。这等于 163,不是 14。 |
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 1, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 1, '视角冲突': 0, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 1, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} IPA:{'1_表示团结': 0, '2_表示紧张释放': 0, '3_同意': 0, '4_提建议': 1, '5_表达观点': 1, '6_提供方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_反对': 0, '11_表示紧张': 1, '12_表示对抗': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 1, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 0, '回溯': 1, '子目标设定': 0, '反向推理': 0} I can keep trying different combinations, but it looks like none of them are working. The question requires that each number is used only once, so we need to think about how to use them all in a specific way to reach 14. 我可以继续尝试不同的组合,但看起来它们都不起作用。这个问题要求每个数字只能使用一次,所以我们需要考虑如何以特定方式使用它们来达到 14。 |
| 1 |
Conversational Behaviour: {’question_and_answering': 1, ’perspective_shift': 1, ’conflict_of_perspectives': 1, ’reconciliation': 0} 对话行为:{'问答': 1, '视角转换': 1, '视角冲突': 1, '和解': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 1, '5_Gives_opinion': 0, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 1, '11_Shows_tension': 0, '12_Shows_antagonism': 0} IPA:{'1_展示团结': 0, '2_展示紧张释放': 0, '3_同意': 0, '4_给出建议': 1, '5_给出观点': 0, '6_给出方向': 1, '7_询问方向': 0, '8_询问观点': 0, '9_询问建议': 0, '10_不同意': 1, '11_展示紧张': 0, '12_展示对抗': 0} Cognitive Behaviour: {’verification': 1, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为:{'验证': 1, '回溯': 0, '子目标设定': 0, '反向链': 0} Maybe we can try using negative numbers: 也许我们可以尝试使用负数: 8. 56 - 66 + 44 - 3 = -10 + 44 - 3. This equals 31, not 14. 8. 56 - 66 + 44 - 3 = -10 + 44 - 3。这等于 31,不是 14。 |
| 2 |
Conversational Behaviour: {’question_and_answering': 0, ’perspective_shift': 0, ’conflict_of_perspectives': 0, ’reconciliation': 0} 对话行为:{'问答': 0, '视角转换': 0, '视角冲突': 0, '调和': 0} IPA: {'1_Shows_solidarity': 0, '2_Shows_tension_release': 0, '3_Agrees': 0, '4_Gives_suggestion': 0, '5_Gives_opinion': 2, '6_Gives_orientation': 1, '7_Asks_for_orientation': 0, '8_Asks_for_opinion': 0, '9_Asks_for_suggestion': 0, '10_Disagrees': 0, '11_Shows_tension': 1, '12_Shows_antagonism': 0} Cognitive Behaviour: {’verification': 0, ’backtracking': 0, ’subgoal_setting': 0, ’backward_chaining': 0} 认知行为: {'verification': 0, 'backtracking': 0, 'subgoal_setting': 0, 'backward_chaining': 0} Again, no luck. It seems difficult to find the correct combination of these numbers and operations that results in 14. It might be impossible with the given numbers. 再次没有成功。似乎很难找到这些数字和操作的正确组合,使其结果为 14。可能给定的数字无法实现。 Therefore, the answer is: 因此,答案是: |
Supplementary Methods: Behavioural Pathways Linking Reasoning Models to Accuracy Advantages
补充方法:连接推理模型与准确优势的行为路径
We estimate a structural equation model (SEM) to decompose the accuracy advantage of DeepSeek-R1 and QwQ-32B over instruction-tuned models into distinct behavioral pathways. The model includes whether the model is DeepSeek-R1 or QwQ-32B as the treatment indicator, eight social behavior mediators (question & answering, perspective shift, conflict of perspectives, reconciliation, ask, give, negative, and positive), four cognitive behavior mediators (verification, backtracking, subgoal setting, and backward chaining), and task accuracy as the outcome. We control for log-transformed reasoning trace length.
我们估计一个结构方程模型(SEM),将 DeepSeek-R1 和 QwQ-32B 相对于指令微调模型的准确优势分解为不同的行为路径。该模型包括模型是否为 DeepSeek-R1 或 QwQ-32B 作为处理指标,八个社会行为中介变量(提问与回答、视角转换、视角冲突、和解、提问、给予、负面和正面),四个认知行为中介变量(验证、回溯、子目标设置和反向链),以及任务准确度作为结果。我们控制了推理轨迹长度的对数转换。
SEM estimates three pathways. The “social” pathway captures whether the increased use of eight social behavior mediators in DeepSeek-R1 and QwQ-32B improves accuracy. The “cognitive” pathway examines whether the increased use of cognitive reasoning strategies in DeepSeek-R1 and QwQ-32B, including verification (i.e., systematically checking intermediate steps), backtracking (i.e., revising earlier steps), subgoal setting (i.e., decomposing the task into intermediate targets), and backward chaining (i.e., reasoning backward from the desired conclusion) enhance accuracy. The “social–cognitive” pathway investigates whether increased social behaviors facilitate these cognitive strategies, which then improve accuracy.
SEM 估计三种路径。 “社会”路径捕捉了在 DeepSeek-R1 和 QwQ-32B 中增加使用八种社会行为中介是否提高了准确性。 “认知”路径考察了在 DeepSeek-R1 和 QwQ-32B 中增加使用认知推理策略,包括验证(即系统地检查中间步骤)、回溯(即修正早期步骤)、子目标设定(即将任务分解为中间目标)和反向链接(即从期望的结论反向推理)是否增强了准确性。 “社会-认知”路径研究了是否增加社会行为促进了这些认知策略,进而提高了准确性。
The full system of equations estimated in the SEM is as follows. Let i index individual task problems, and j index individual reasoning traces generated by different models. The dependent variable is reasoning accuracy (), coded as a binary variable that equals 1 if the reasoning trace leads to a correct answer, and 0 otherwise. The key predictor is which equals 1 if the reasoning trace is generated by DeepSeek-R1 or QwQ-32B and 0 if generated by an instruction-tuned model. is log-transformed reasoning trace length. The social variables () represent the frequency of eight social behaviors. The cognitive strategy variables () correspond to the frequency of four cognitive behaviors.
SEM 中估计的完整方程系统如下。设索引个体任务问题,设索引由不同模型生成的个体推理轨迹。因变量是推理准确度( ),编码为二元变量,若推理轨迹得出正确答案则等于 1,否则等于 0。关键预测变量是 ,若推理轨迹由 DeepSeek-R1 或 QwQ-32B 生成则等于 1,若由指令微调模型生成则等于 0。 是经过对数转换的推理轨迹长度。社会变量( )代表八种社会行为的频率。认知策略变量( )对应四种认知行为的频率。
The system of equations is defined as follows, where:
方程系统定义如下,其中:
From these structural paths, we derive the following composite effects. The composite effects for “social” pathway, where the increased use of conversational behaviors or Bales’ socio-emotional roles in DeepSeek-R1 or QwQ-32B improves accuracy, is defined as . The “cognitive” pathway, where the increased use of cognitive reasoning strategies in DeepSeek-R1 or QwQ-32B enhances accuracy, is defined as . The “social–cognitive” pathway, where increased conversational behaviors or socio-emotional roles in DeepSeek-R1 or QwQ-32B facilitate cognitive strategies and improve accuracy, is defined as . The direct pathway where DeepSeek-R1 directly impacts accuracy is defined as . The total effects are defined as .
从这些结构路径中,我们推导出以下复合效应。对于“社会”路径,即 DeepSeek-R1 或 QwQ-32B 中对话行为的增加或 Bales 社会情感角色的增加提高了准确性,其复合效应定义为 。对于“认知”路径,即 DeepSeek-R1 或 QwQ-32B 中认知推理策略的增加提高了准确性,其复合效应定义为 。对于“社会-认知”路径,即 DeepSeek-R1 或 QwQ-32B 中对话行为或社会情感角色的增加促进了认知策略并提高了准确性,其复合效应定义为 。对于 DeepSeek-R1 直接影响的路径,其复合效应定义为 。总效应定义为 。
Extended Data Fig. 4a reports summary estimates for the mediation pathways. The total effect of DeepSeek-R1 on accuracy is 0.26 (p < 0.001). This effect decomposes into: (1) a direct effect of 0.06 (p < 0.001), representing variance unexplained by the measured mediators; (2) an indirect effect through social behaviors of 0.07 (p < 0.001), representing the social pathway; and (3) an indirect effect through cognitive behaviors that is not statistically distinguishable from zero ( = 0.00, p > 0.05). The indirect pathway from social behaviors through cognitive behaviors to accuracy contributes an additional 0.01 (p < 0.01). See Supplementary Table 11 for the full estimates.
扩展数据图 4a 报告了中介路径的汇总估计。DeepSeek-R1 对准确性的总效应为 0.26(p < 0.001)。这种效应分解为:(1)一个 0.06(p < 0.001)的直接效应,代表由测量中介未解释的方差;(2)一个通过社会行为的间接效应 0.07(p < 0.001),代表社会路径;(3)一个通过认知行为的间接效应,在统计上无法与零区分( = 0.00,p > 0.05)。从社会行为通过认知行为到准确性的间接路径再贡献了 0.01(p < 0.01)。参见补充表 11 获取完整估计。
Supplementary Methods: Cross-domain Reasoning Transfer
补充方法:跨领域推理迁移
To test whether conversational scaffolding confers domain-general reasoning advantages, we conduct supervised fine-tuning on a Countdown task using a conversational scaffold, the format defined in the “Supervised fine-tuning” section of Methods: Reinforcement learning experiments. Supervised fine-tuning data has been generated by GPT-4.1 Then, using this fine-tuned model, we conduct reinforcement learning on a very different reasoning task: PolitiFact misinformation detection task.
为了测试对话式脚手架是否赋予领域泛化的推理优势,我们在“方法:强化学习实验”部分中定义的“监督微调”部分使用对话式脚手架,对 Countdown 任务进行监督微调。监督微调数据由 GPT-4.1 生成。然后,我们使用这个微调后的模型,在非常不同的推理任务上进行强化学习:PolitiFact 虚假信息检测任务。
For the reinforcement learning, we use 23,299 fact-checked claims from the PolitiFact corpus, covering statements from political figures, news outlets, and social media posts from November 2007 to January 2024. The dataset includes six PolitiFact labels—True, Mostly True, Half True, Mostly False, False, and Pants on Fire—for each statement, such as “Katherine Clark stated on September 12, 2025 in a post on X that Republicans are spiking health insurance premiums by 75% for everyday Americans,” which we recode into three categories for reasoning evaluation:
对于强化学习,我们使用 PolitiFact 语料库中的 23,299 条经过事实核查的声明,涵盖从 2007 年 11 月到 2024 年 1 月政治人物、新闻机构和社交媒体帖子中的陈述。数据集包括每个声明的六个 PolitiFact 标签——真实、基本真实、部分真实、基本虚假、虚假和离谱——例如“凯瑟琳·克拉克在 2025 年 9 月 12 日 X 平台的一篇帖子中声称共和党将使普通美国人的健康保险保费上涨 75%”,我们将其重新编码为三个推理评估类别:
-
•
True = {True, Mostly True}
• 真实 = {真实,基本真实} -
•
Half True = {Half True}
• 部分真实 = {部分真实} -
•
False = {False, Mostly False, Pants on Fire}
Next, we compare the performance of baseline models (Llama-3.2-3B and Qwen-2.5-3B) and models fine-tuned with conversational datasets across subsequent RL training steps. Specifically, we compare two conditions: (1) Baseline: no supervised priming, RL only; (2) Conversation → Correct: supervised fine-tuning (SFT) on correct multi-agent dialogues using “Countdown task,” not misinformation detection task, before RL.
接下来,我们比较了基线模型(Llama-3.2-3B 和 Qwen-2.5-3B)与使用对话数据集微调的模型在后续 RL 训练步骤中的性能。具体来说,我们比较了两种条件:(1) 基线:无监督预训练,仅 RL;(2) 对话→正确:在 RL 之前,使用“倒计时任务”对正确的多智能体对话进行监督微调(SFT),而不是错误信息检测任务。
Supplementary Fig. 3 illustrates the learning trajectories of both conditions on the misinformation detection task. Models previously fine-tuned on conversational scaffolding on the Countdown task achieve faster early-stage gains in factual reasoning accuracy. Together, these findings demonstrate that social interaction fine-tuning not only improves in-domain arithmetic reasoning but also accelerates reasoning development in a very different domain like misinformation detection, highlighting the generality of socially organized reasoning.
补充图 3 展示了两种条件在错误信息检测任务上的学习轨迹。先前在倒计时任务对话框架上微调的模型在事实推理准确率上实现了更快的早期阶段提升。这些发现共同表明,社交互动微调不仅提高了领域内算术推理能力,还加速了在错误信息检测等非常不同的领域中的推理发展,突显了社交组织推理的普遍性。
Supplementary Methods: Performance Comparison Between PPO and GRPO
补充方法:PPO 与 GRPO 的性能比较
GRPO differs from PPO by normalizing the policy advantage within each mini-batch of reasoning trajectories and computing a group-relative objective. Although GRPO can reduce variance in multi-sample RLHF settings, our empirical results show that standard PPO achieves comparable performance in smaller-scale reasoning experiments such as ours. Specifically, after training both algorithms for 250 steps on the Qwen-2.5-3B baseline model on the Countdown task, PPO achieved a reward score (0.9 × accuracy + 0.1 × format) of 0.5665, whereas GRPO achieved 0.5747.
GRPO 与 PPO 的不同之处在于,它在推理轨迹的每个小批量中归一化策略优势,并计算一个相对组目标。尽管 GRPO 可以在多样本 RLHF 设置中减少方差,但我们的实证结果表明,标准 PPO 在我们的小规模推理实验中也能达到相当的性能。具体来说,在 Countdown 任务上使用 Qwen-2.5-3B 基线模型训练两种算法 250 步后,PPO 达到了 0.5665 的奖励分数(0.9×准确率+0.1×格式),而 GRPO 达到了 0.5747。
Supplementary Methods: Replications on Llama-3.2-3B
补充方法:在 Llama-3.2-3B 上的复现
To assess the generalizability of our findings beyond Qwen-2.5-3B, we replicate the training pipeline using Llama-3.2-3B as base model. Llama-3.2-3B base model is supervised-fine-tuned on one of the two datasets (conversational reasoning vs. monologue-like reasoning; see Methods: Supervised fine-tuning datasets) using standard next-token prediction loss. For the conversation condition, reasoning content from multiple personas was concatenated into a single block (<think> </think>) to ensure comparable sequence lengths across conditions in Llama-3.2-3B. This priming phase familiarizes the model with the respective format (conversational reasoning vs. monologue-like reasoning) before RL optimizes for task accuracy. Supervised Fine Tuning (SFT) hyperparameters are provided in Supplementary Table 8.
为了评估我们的研究结果在 Qwen-2.5-3B 之外的普适性,我们使用 Llama-3.2-3B 作为基础模型重复了训练流程。Llama-3.2-3B 基础模型在两个数据集之一(对话式推理与独白式推理;参见方法:监督微调数据集)上使用标准的下一词预测损失进行监督微调。对于对话条件,来自多个角色的推理内容被连接成一个单一区块(<think> </think>),以确保在 Llama-3.2-3B 中不同条件下序列长度具有可比性。这一预训练阶段使模型熟悉相应的格式(对话式推理与独白式推理),然后再通过强化学习优化任务准确率。监督微调(SFT)的超参数在补充表 8 中提供。
Reinforcement learning is performed on the Countdown arithmetic puzzle using PPO with the Verl framework. Reward R is assigned as R = 0.9 × {Accuracy} + 0.1 × {Correct Format}, where Accuracy is binary (1 if the reasoning trace leads to the correct answer, 0 otherwise) and Format is binary (1 if the reasoning trace contains at least one reasoning block and one final answer block providing a single answer in equation form, 0 otherwise). Training proceeded for 250 steps. PPO hyperparameters are provided in Supplementary Table 6. To examine whether conversational behaviors emerge spontaneously during RL, we evaluate model performance on a held-out validation set of 1,024 Countdown problems at each training checkpoint (every 10 steps).
在 Verl 框架下,使用 PPO 对倒计时算术谜题进行强化学习。奖励 R 被设定为 R = 0.9 × {准确率} + 0.1 × {正确格式},其中准确率是二元的(如果推理轨迹导致正确答案则为 1,否则为 0),格式也是二元的(如果推理轨迹包含至少一个推理块和一个最终答案块,并以方程形式提供单一答案则为 1,否则为 0)。训练进行了 250 步。PPO 超参数在补充表格 6 中提供。为了检验在强化学习过程中是否自发出现对话行为,我们在每个训练检查点(每 10 步)对 1024 个倒计时谜题的保留验证集上评估模型性能。
Supplementary Methods: LLM-as-Judge prompts
补充方法:LLM 作为裁判的提示
Conversational Behaviors 对话行为
Socio-Emotional Roles 社会情感角色
Problem Complexity 问题复杂性
Cognitive Behaviors 认知行为
Persona Identification Prompt
角色识别提示
Persona Segmentation 角色分割
Identifying Conversational Contexts
识别对话语境
Classifying Sparse Autoencoder (SAE) Personality Features
分类稀疏自动编码器(SAE)人格特征
Classifying Sparse Autoencoder (SAE) Expertise Features
分类稀疏自动编码器(SAE)专业特征
Supplementary Methods: SFT Data Generation Prompts
补充方法:SFT 数据生成提示
Generating Monologue-Like Reasoning Traces for Supervised Fine-Tuning
生成类似独白的推理轨迹以进行监督微调
Generating Conversation-Like Reasoning Traces for Supervised Fine-Tuning
生成类似对话的推理轨迹以进行监督微调
Supplementary Tables 补充表格
Supplementary Table 1. Differences in conversational behaviors, socio-emotional roles, and Jaccard indices between reasoning models and instruction-tuned models
补充表格 1. 推理模型与指令微调模型在对话行为、社会情感角色和 Jaccard 指数方面的差异
| DeepSeek-R1 vs. DeepSeek-R1 与 DeepSeek-V3 | QWQ-32B vs. QWQ-32B 与 Qwen-2.5-32B | |
| Conversational behaviors 对话行为 | ||
| Question answering 问答 | 0.345 [0.328, 0.361] t = 41.64, p < 1×10-323 | 0.459 [0.444, 0.475] t = 57.57, p < 1×10-323 |
| Perspective shifts 视角转换 | 0.213 [0.197, 0.230] t = 25.55, p < 1×10-137 | 0.378 [0.362, 0.394] t = 46.92, p < 1×10-323 |
|
Conflict of perspectives 冲突的视角 |
0.012 [-0.003, 0.027] t = 1.52, p = 0.127 | 0.293 [0.277, 0.308] t = 37.08, p < 1×10-277 |
| Reconciliations 调和 | 0.191 [0.176, 0.207] t = 24.31, p < 1×10-125 | 0.344 [0.328, 0.360] t = 42.59, p < 1×10-323 |
| Socio-emotional roles 社会情感角色 | ||
| Ask 询问 | 0.189 [0.176, 0.203] t = 27.47, p < 1×10-158 | 0.200 [0.186, 0.215] t = 27.21, p < 1×10-155 |
| Give 给 |
-0.009 [-0.012, -0.006]
t = -5.97, p < 1×10-8 t = -5.97, p < 1×10^-0# |
-0.008 [-0.011, -0.005]
t = -4.99, p < 1×10-6 t = -4.99, p < 1×10^-0# |
| Negative 负数 | 0.162 [0.147, 0.176] t = 21.87, p < 1×10-102 | 0.450 [0.436, 0.463] t = 64.77, p < 1×10-323 |
| Positive 阳性 | 0.278 [0.263, 0.293] t = 35.38, p < 1×10-254 | 0.312 [0.296, 0.327] t = 39.17, p < 1×10-307 |
| Jaccard Index | ||
| Ask & Give | 0.222 [0.208, 0.237] t = 30.21, p < 1×10-189 | 0.284 [0.269, 0.299] t = 37.36, p < 1×10-281 |
| Positive & Negative 正 & 负 | 0.189 [0.176, 0.203] t = 27.47, p < 1×10-158 | 0.200 [0.186, 0.215] t = 27.24, p < 1×10-155 |
| df | 8261 | |
| Observations 观察 | 49572 | |
Notes: Regression coefficients comparing DeepSeek-R1 and QWQ-32B to the respective instruction-tuned models (DeepSeek-V3, Qwen-2.5-32B-IT) are shown in each column. 95% confidence intervals are reported in brackets, along with the corresponding t-statistics, degrees of freedom, and exact p-values. All models include task fixed effects and control for log-transformed reasoning trace length. Coefficients are tested using two-sided t-tests, with standard errors clustered at the task level.
注释:每列展示了 DeepSeek-R1 和 QWQ-32B 与各自指令微调模型(DeepSeek-V3、Qwen-2.5-32B-IT)的回归系数。括号中报告了 95%置信区间,以及相应的 t 统计量、自由度和精确 p 值。所有模型均包含任务固定效应,并控制了推理轨迹长度的对数转换。系数使用双尾 t 检验进行检验,标准误在任务层面聚类。
Supplementary Table 2. Most and least challenging tasks sorted by problem complexity measured by LLM-as-judge
补充表 2。按问题复杂度(由 LLM 作为评判者衡量)排序的最具挑战性和最不具挑战性的任务
| Problem Complexity 问题复杂度 |
Conversational Behaviour 对话行为 |
||||||
| Benchmark task 基准任务 | LLM-as-judge (1-7) LLM 作为评判者(1-7) |
Non-reasoning error rate (0-4) 非推理错误率(0-4) |
Question & Answering 问答 | Perspective Shift 视角转换 |
Conflict of Perspectives 视角冲突 |
Reconciliation 和解 | |
| Most Challenging Tasks 最具挑战性的任务 | |||||||
| GPQA | Main 主要 | 5.50 (0.86) | 2.30 (1.23) | 6.19 (4.38) | 6.94 (3.40) | 6.01 (3.72) | 2.83 (1.66) |
| GPQA | Diamond 钻石 | 5.47 (0.91) | 2.43 (1.23) | 6.53 (4.45) | 7.14 (4.01) | 6.57 (4.75) | 2.94 (1.73) |
| GPQA | Extended 扩展 | 5.46 (0.93) | 2.23 (1.25) | 5.81 (3.63) | 6.60 (3.36) | 5.73 (3.89) | 2.69 (1.51) |
| MATH (Hard) 数学(困难) | Intermediate Algebra 中级代数 | 4.80 (0.75) | 2.62 (1.00) | 8.12 (3.83) | 6.18 (3.09) | 4.21 (2.52) | 2.85 (1.46) |
| MATH (Hard) 数学(困难) | Pre-Calculus 预微积分 | 4.63 (0.92) | 2.42 (1.14) | 6.90 (2.84) | 5.13 (2.37) | 3.59 (2.16) | 2.70 (1.39) |
| MUSR | Object Placement 物体放置 | 4.43 (0.98) | 2.42 (1.22) | 4.78 (2.92) | 5.20 (2.43) | 4.16 (2.30) | 2.57 (1.57) |
| MATH (Hard) 数学(难) | Geometry 几何 | 4.35 (0.94) | 2.43 (1.10) | 8.32 (3.36) | 5.75 (3.02) | 4.13 (2.16) | 3.39 (1.51) |
| BigBench Hard | Causal Judgment 因果判断 | 4.16 (1.11) | 1.47 (1.35) | 4.31 (2.90) | 5.99 (2.71) | 4.57 (3.05) | 2.55 (1.55) |
| BigBench Hard | Logical Fallacies 逻辑谬误 | 4.15 (1.14) | 0.69 (0.76) | 2.82 (1.75) | 3.96 (1.92) | 2.05 (1.75) | 1.22 (1.26) |
| MATH (Hard) MATH(难) | Probability 概率论 | 4.13 (0.80) | 1.99 (1.14) | 8.02 (4.00) | 5.09 (2.50) | 3.23 (2.30) | 2.83 (1.57) |
| Least Challenging Tasks 最简单的任务 | |||||||
| BigBench Hard BigBench 难 | Date 日期 | 2.11 (1.03) | 0.81 (0.92) | 3.87 (2.81) | 4.73 (2.63) | 2.78 (2.05) | 1.73 (1.30) |
| BigBench Hard BigBench 困难 | Disambig. QA 消歧义问答 | 2.01 (0.99) | 1.96 (1.32) | 3.16 (2.27) | 3.74 (2.07) | 3.15 (2.14) | 1.58 (1.22) |
| BigBench Hard BigBench 困难 | Navigation 导航 | 1.98 (0.92) | 0.35 (0.61) | 2.01 (1.57) | 2.56 (1.68) | 1.12 (1.19) | 1.08 (1.08) |
| BigBench Hard | Shuffled 打乱 | 1.67 (0.69) | 0.79 (0.93) | 1.42 (1.65) | 2.46 (1.93) | 0.40 (0.76) | 0.44 (0.76) |
| BigBench Hard |
Penguins in a Table 企鹅在桌子上 |
1.66 (0.79) | 0.71 (0.88) | 2.92 (2.39) | 3.55 (2.20) | 1.94 (1.64) | 1.68 (1.30) |
| BigBench Hard | Colored Objects 彩色物体 | 1.47 (0.71) | 0.79 (0.94) | 2.53 (2.06) | 3.07 (1.88) | 0.88 (1.07) | 0.75 (0.87) |
| BigBench Hard | Hyperbaton 迂回语 | 1.34 (0.65) | 0.70 (0.88) | 3.39 (2.29) | 3.41 (1.99) | 3.28 (2.06) | 1.86 (1.30) |
| BigBench Hard | Boolean 布尔值 | 1.17 (0.42) | 0.15 (0.40) | 1.09 (1.18) | 1.46 (1.26) | 0.50 (0.79) | 0.43 (0.66) |
| BigBench Hard | Object Counting 对象计数 | 1.15 (0.40) | 0.46 (0.68) | 1.56 (1.51) | 2.17 (1.58) | 0.63 (0.88) | 0.65 (0.83) |
| BigBench Hard | Logical Deduction 逻辑演绎 | 1.08 (0.30) | 0.43 (0.66) | 2.68 (2.03) | 3.84 (2.16) | 3.12 (1.98) | 1.48 (1.13) |
Notes: Each cell presents average problem complexity or the average number of times each behavior appears in reasoning traces. Standard deviations are presented in parentheses.
注释:每个单元格显示平均问题复杂度或每个行为在推理轨迹中出现的平均次数。括号中显示标准差。
Supplementary Table 3. SAE Training Hyperparameters
补充表格 3. SAE 训练超参数
| Hyperparameter 超参数 | Value 值 |
| Features 特性 | 32,768 |
| Hook Name 钩子名称 | blocks.15.hook_resid_post |
| Context Size 上下文大小 | 1024 |
| Input Dimension 输入维度 | 4096 |
| Data Type 数据类型 | float32 |
| Architecture 架构 | jumprelu |
| Training Dataset 训练数据集 | cerebras/Slimpajama-627B |
|
Evaluation Dataset (for feature explanation) 评估数据集(用于特征解释) |
Hzfinfdu/SlimPajama-3B |
Supplementary Table 4. SAE personality features more frequently activated after steering +10 surprise
补充表 4. SAE 人格特征在转向+10 惊讶后更频繁激活
| Feature 特征 | Description 描述 | Difference 差异 | Ratio before steering 转向前比率 |
Ratio after steering
转向后比率 (+10 Surprise) (+10 惊喜) |
Personality
性格 score 评分 |
| 21065 |
informal expressions of confusion or frustration regarding societal issues 对社会问题的困惑或沮丧的非正式表达 |
0.107 | 0.027 | 0.134 | 75 |
| 26139 |
phrases related to social interaction and community engagement 与社会互动和社区参与相关的短语 |
0.084 | 0.059 | 0.143 | 70 |
| 26820 |
conditions or scenarios that involve decision-making or problem-solving 涉及决策或问题解决的状况或场景 |
0.068 | 0.068 | 0.137 | 70 |
| 14476 |
references to emotional or sensational themes in narratives 叙事中涉及情感或感官主题的引用 |
0.063 | 0.046 | 0.109 | 70 |
| 24222 |
phrases indicating emotional or subjective experiences 表明情感或主观体验的短语 |
0.055 | 0.068 | 0.123 | 70 |
| 11280 |
references to identities and backgrounds of people, particularly in literature and film contexts 对人物身份和背景的引用,特别是在文学和电影语境中 |
0.044 | 0.108 | 0.152 | 70 |
| 22916 |
elements related to emotions and moral reflections 与情感和道德反思相关的元素 |
0.042 | 0.054 | 0.095 | 85 |
| 20151 |
discussions about literature and character analysis 关于文学和人物分析的讨论 |
0.041 | 0.052 | 0.092 | 60 |
| 8668 |
phrases related to personal feelings and social connections 与个人情感和社会关系相关的短语 |
0.037 | 0.058 | 0.096 | 75 |
| 15118 |
statements reflecting emotional conflict and self-reflection 反映情感冲突和自我反思的陈述 |
0.033 | 0.019 | 0.053 | 75 |
| 19520 |
phrases that express opportunity, potential, or positive outlooks 表达机会、潜力或积极前景的短语 |
0.029 | 0.021 | 0.050 | 60 |
| 26648 |
phrases associated with making choices or decisions 与做选择或决策相关的短语 |
0.024 | 0.034 | 0.058 | 70 |
| 18858 |
words and phrases related to gambling or casino contexts 与赌博或赌场环境相关的词语和短语 |
0.024 | 0.075 | 0.098 | 75 |
| 8053 |
references to social justice or humanitarian efforts 涉及社会正义或人道主义行动的引用 |
0.022 | 0.016 | 0.038 | 60 |
| 26894 |
dialogue and interactions that indicate emotional states or actions occurring within a narrative context 表明叙事环境中情绪状态或行动的对话和互动 |
0.022 | 0.111 | 0.133 | 70 |
| 2403 |
references to interpersonal relationships and emotional connections 人际交往和情感联系 |
0.021 | 0.050 | 0.071 | 75 |
Supplementary Table 5. SAE expertise features more frequently activated after steering +10 surprise
补充表 5. 方向盘+10 惊喜后 SAE 专业特征更频繁激活
| Feature 特征 | Description 描述 | Difference 差异 | Ratio before steering 转向前的比率 |
Ratio after steering
转向后的比率 (+10 Surprise) (+10 惊喜) |
Expertise
专业知识 score 评分 |
| 10105 |
numeric values and their mathematical operations 数值及其数学运算 |
0.169 | 0.218 | 0.386 | 60 |
| 18556 |
transitions and conclusions in a logical argument or explanation 逻辑论证或解释中的过渡和结论 |
0.107 | 0.243 | 0.350 | 60 |
| 26139 |
mathematical concepts related to integers and their properties 与整数及其性质相关的数学概念 |
0.084 | 0.059 | 0.143 | 85 |
| 8532 |
equations and mathematical expressions involving variables and operations 涉及变量和运算的方程式和数学表达式 |
0.072 | 0.052 | 0.125 | 85 |
| 31699 |
mathematical symbols and expressions related to equations or functions 与方程式或函数相关的数学符号和表达式 |
0.069 | 0.465 | 0.534 | 90 |
| 14476 |
mentions of quantities and their corresponding units in a numerical or mathematical context 在数值或数学语境中提及的量及其对应的单位 |
0.063 | 0.046 | 0.109 | 70 |
| 32111 |
equations or mathematical expressions 方程式或数学表达式 |
0.055 | 0.418 | 0.474 | 75 |
| 22705 |
mathematical terms related to geometry and spatial properties 与几何和空间属性相关的数学术语 |
0.054 | 0.058 | 0.112 | 85 |
| 11452 |
discussions regarding the implications and potential of alternative medical treatments, particularly in relation to traditional medical practices 关于替代医疗方法的意义和潜力,特别是与传统医疗实践的关系的讨论 |
0.052 | 0.299 | 0.351 | 95 |
| 24623 |
technical terms and concepts related to automotive engineering and intelligent systems 与汽车工程和智能系统相关的技术术语和概念 |
0.051 | 0.269 | 0.320 | 95 |
| 25764 |
mathematical expressions and their transformations 数学表达式及其变换 |
0.051 | 0.085 | 0.136 | 75 |
| 22449 |
numerical operations and mathematical expressions 数值运算和数学表达式 |
0.050 | 0.039 | 0.089 | 80 |
| 17611 |
mathematical properties and functions related to periodicity and calculations 与周期性和计算相关的数学性质和函数 |
0.049 | 0.092 | 0.141 | 75 |
| 23233 |
numerical values and their relationships in mathematical expressions 数学表达式中的数值及其关系 |
0.047 | 0.075 | 0.121 | 70 |
| 27631 |
mathematical operations involving modular arithmetic 涉及模运算的数学运算 |
0.046 | 0.224 | 0.269 | 75 |
| 5298 |
phrases related to mathematical equations or computations 与数学方程式或计算相关的短语 |
0.045 | 0.204 | 0.249 | 70 |
Supplementary Table 6. PPO training hyperparameters
补充表格 6. PPO 训练超参数
| Data and model 数据和模型 | |
|
Training/validation batch size 训练/验证批次大小 |
128 / 640 |
| Context window 上下文窗口 |
1024 prompt + 1024 response tokens 1024 个 prompt + 1024 个 response tokens |
| Optimization 优化 | |
| Actor learning rate 演员学习率 | 1e-06 |
| Critic learning rate 评论家学习率 | 1e-05 |
| KL coefficient KL 系数 | 0.001 |
| PPO mini-batch size PPO 小批量大小 | 64 |
| Number of rollouts 展开次数 | 4 |
| Rollout temperature 扩展温度 | 1.0 |
| Reward structure 奖励结构 | |
| Accuracy weight 准确度权重 | 0.9 |
| Correct format weight 正确格式权重 | 0.1 |
Supplementary Table 7. Monologue-style and conversation-style fine-tuning data generated by Qwen-2.5-32B-IT
补充表格 7. Qwen-2.5-32B-IT 生成的独白式和对话式微调数据
Supplementary Table 8. Supervised fine-tuning hyperparameters
补充表格 8. 监督微调超参数
| Data and Model 数据和模型 | |
|
Training/validation dataset size 训练/验证数据集大小 |
500 / 100 |
| Context window 上下文窗口 | 2048 |
|
Training/validation batch size 训练/验证批次大小 |
64 / 64 |
| Optimization 优化 | |
| Optimizer 优化器 | AdamW |
| Peak learning rate 峰值学习率 | 1e-05 |
| Warmup 预热 |
Linear (10% of total steps) 线性(总步数的 10%) |
| Annealing 退火 | Cosine 余弦 |
| Total epochs 总轮数 | 5 |
Supplementary Table 9. Benchmark Tasks
补充表 9. 基准任务
| Benchmark 基准 | Task Category 任务类别 | # Problems # 问题 |
| BigBench Hard | Boolean Expressions 布尔表达式 | 248 |
| Causal Judgment 因果判断 | 173 | |
| Date Understanding 日期理解 | 195 | |
|
Disambiguation Question Answering 消歧问题回答 |
249 | |
|
Formal Logical Fallacies 形式逻辑谬误 |
250 | |
|
Geometric Shape Reasoning 几何形状推理 |
249 | |
|
Hyperbaton (Syntactic Reordering) 倒装(句法重排) |
247 | |
|
Logical Deduction (Five Objects) 逻辑演绎(五对象) |
244 | |
|
Logical Deduction (Seven Objects) 逻辑演绎(七物) |
224 | |
|
Logical Deduction (Three Objects) 逻辑演绎(三物) |
249 | |
| Movie Recommendation 电影推荐 | 7 | |
|
Navigation and Spatial Planning 导航与空间规划 |
248 | |
| Object Counting 物体计数 | 247 | |
|
Penguins in a Table (Deductive Counting) 桌子上的企鹅(演绎计数) |
143 | |
|
Reasoning About Colored Objects 关于彩色物体的推理 |
245 | |
|
Ruin Names (Linguistic Perturbation) 废墟名称(语言扰动) |
165 | |
|
Salient Translation Error Detection 显著翻译错误检测 |
249 | |
|
Snarks (Riddle Interpretation) 斯纳克斯(谜语解释) |
146 | |
| Sports Understanding 体育理解 | 250 | |
|
Temporal Sequence Reasoning 时间序列推理 |
65 | |
|
Tracking Shuffled Objects (Five Objects) 追踪打乱的对象(五个对象) |
112 | |
|
Tracking Shuffled Objects (Seven Objects) 追踪打乱的对象(七个对象) |
102 | |
|
Tracking Shuffled Objects (Three Objects) 追踪打乱的对象(三个对象) |
57 | |
|
Web of Lies (Deception Reasoning) 谎言之网(欺骗推理) |
72 | |
| GPQA | Diamond Level 钻石级别 | 161 |
| Extended Level 扩展级别 | 474 | |
| Main Benchmark 主要基准 | 380 | |
| IFEval |
Instruction-Following Consistency Evaluation 指令一致性评估 |
524 |
| MATH (Hard) 数学(难) | Algebra (Hard) 代数(难) | 286 |
|
Counting & Probability (Hard) 计数与概率(难) |
110 | |
| Geometry (Hard) 几何(难) | 117 | |
|
Intermediate Algebra (Hard) 中级代数(难) |
212 | |
| Number Theory (Hard) 数论(难) | 134 | |
| Pre-Algebra (Hard) 预备代数(难) | 182 | |
| Pre-Calculus (Hard) 预微积分(难) | 104 | |
| MMLU-Pro |
Advanced Multidomain Knowledge 高级多领域知识 |
432 |
| MUSR |
Murder Mysteries (Collaborative Deduction) 谋杀之谜(合作推理) |
207 |
|
Object Placement (Spatial Coordination) 对象放置(空间协调) |
256 | |
|
Team Allocation (Group Strategy) 团队分配(群体策略) |
247 |
Supplementary Table 10. Descriptive statistics of conversational behaviors and socio-emotional roles for reasoning and instruction-tuned models (Count variables)
补充表 10. 推理和指令调优模型的对话行为和社会情感角色的描述性统计(计数变量)
| Reasoning Models 推理模型 |
Instruction-Tuned Models 指令调优模型 |
|||||
| DeepSeek- R1 | QWQ-32B | DeepSeek- V3 | Qwen-2.5-32B-IT | Llama-3.3-70B-IT | Llama-3.1-8B- IT | |
| Mean (SD) 均值(标准差) | Mean (SD) 均值(标准差) | Mean (SD) 均值(标准差) | Mean (SD) 均值(标准差) | Mean (SD) 均值(标准差) | Mean (SD) 均值(标准差) | |
| Conversational behaviors 对话行为 | ||||||
| Question answering 问答 | 6.74 (4.32) | 6.68 (4.62) | 3.07 (2.53) | 2.35 (4.25) | 2.22 (1.98) | 3.16 (18.05) |
| Perspective shifts 视角转换 | 3.47 (2.76) | 5.41 (6.89) | 1.09 (1.69) | 0.79 (3.95) | 0.97 (1.56) | 1.84 (17.04) |
|
Conflict of perspectives 视角冲突 |
3.19 (2.95) | 5.27 (5.51) | 1.50 (2.06) | 0.97 (3.99) | 1.08 (1.62) | 2.25 (17.96) |
| Reconciliations 调和 | 1.97 (1.60) | 2.52 (1.90) | 0.61 (0.76) | 0.41 (0.62) | 0.58 (0.81) | 0.49 (1.27) |
| Socio-emotional roles 社会情感角色 | ||||||
| Ask for orientation 请求指导 | 2.67 (5.14) | 2.19 (3.80) | 0.01 (0.15) | 0.01 (0.11) | 0.00 (0.08) | 0.01 (0.24) |
| Ask for opinion 请求意见 | 0.50 (1.73) | 0.57 (1.94) | 0.00 (0.07) | 0.00 (0.05) | 0.00 (0.07) | 0.01 (0.39) |
| Ask for suggestion 请求建议 | 0.18 (0.87) | 0.26 (1.10) | 0.00 (0.04) | 0.00 (0.04) | 0.00 (0.06) | 0.01 (0.14) |
| Give orientation 提供指导 | 29.67 (23.44) | 26.17 (21.06) | 8.26 (6.55) | 7.00 (7.74) | 6.20 (5.14) | 8.52 (24.72) |
| Give opinion 给出意见 | 19.25 (18.08) | 21.72 (22.64) | 4.15 (4.31) | 3.09 (4.73) | 3.74 (4.02) | 4.60 (35.84) |
| Give suggestion 提出建议 | 9.04 (7.80) | 13.05 (12.33) | 2.23 (3.02) | 2.17 (2.21) | 2.50 (3.09) | 3.05 (12.05) |
| Antagonism 对抗 | 0.00 (0.13) | 0.00 (0.06) | 0.01 (0.27) | 0.00 (0.10) | 0.00 (0.13) | 0.01 (0.16) |
| Tension 紧张 | 3.82 (5.37) | 9.65 (11.53) | 0.14 (0.67) | 0.03 (0.24) | 0.21 (2.04) | 0.65 (10.60) |
| Disagree 不同意 | 2.56 (5.15) | 3.09 (5.41) | 0.49 (1.54) | 0.16 (0.89) | 0.25 (2.17) | 0.88 (8.90) |
| Solidarity 团结 | 0.00 (0.07) | 0.00 (0.05) | 0.01 (0.23) | 0.01 (0.14) | 0.00 (0.13) | 0.02 (0.33) |
| Tension release 紧张释放 | 0.50 (1.12) | 0.36 (0.87) | 0.02 (0.29) | 0.00 (0.10) | 0.01 (0.14) | 0.06 (3.50) |
| Agree 同意 | 3.59 (4.83) | 3.50 (4.64) | 0.18 (0.69) | 0.04 (0.26) | 0.03 (0.21) | 0.06 (0.85) |
| Observations 观察 | 8,262 | |||||
Supplementary Table 11. Structural equation model estimates linking DeepSeek-R1, conversational behaviors, socio-emotional roles, cognitive reasoning strategies, and accuracy
补充表 11. 结构方程模型估计,连接 DeepSeek-R1、对话行为、社会情感角色、认知推理策略和准确率
| Estimate 估计 | Std.Err 标准误差 | z | p-value p 值 | |
|
DeepSeek-R1 → Question & Answering DeepSeek-R1 → 问答 |
4.013 | 0.066 | 61.060 | <0.001 |
|
DeepSeek-R1 → Perspective Shift DeepSeek-R1 → 视角转换 |
3.273 | 0.067 | 48.530 | <0.001 |
|
DeepSeek-R1 → Conflict of Perspectives DeepSeek-R1 → 观点冲突 |
2.764 | 0.065 | 42.400 | <0.001 |
|
DeepSeek-R1 → Reconciliation DeepSeek-R1 → 调和 |
1.748 | 0.016 | 109.360 | <0.001 |
| DeepSeek-R1 → Positive DeepSeek-R1 → 积极 | 4.017 | 0.055 | 72.810 | <0.001 |
| DeepSeek-R1 → Negative DeepSeek-R1 → 消极 | 9.177 | 0.121 | 75.740 | <0.001 |
| DeepSeek-R1 → Ask | 3.276 | 0.050 | 66.090 | <0.001 |
| DeepSeek-R1 → Give | 46.810 | 0.408 | 114.750 | <0.001 |
|
Question & Answering → Verification 问题与解答 → 验证 |
0.179 | 0.070 | 2.550 | 0.011 |
|
Perspective Shift → Verification 视角转换 → 验证 |
-0.096 | 0.107 | -0.890 | 0.372 |
|
Conflict of Perspectives → Verification 视角冲突 → 验证 |
0.216 | 0.113 | 1.910 | 0.057 |
|
Reconciliation → Verification 调和 → 验证 |
-0.237 | 0.109 | -2.180 | 0.029 |
| Positive → Verification 正面 → 验证 | -0.023 | 0.129 | -0.180 | 0.858 |
| Negative → Verification 否定 → 验证 | 0.055 | 0.057 | 0.960 | 0.336 |
| Ask → Verification 询问 → 验证 | -0.111 | 0.039 | -2.810 | 0.005 |
| Give → Verification 给予 → 验证 | 0.026 | 0.015 | 1.740 | 0.082 |
|
DeepSeek-R1 → Verification DeepSeek-R1 → 验证 |
-0.673 | 0.327 | -2.060 | 0.039 |
|
Question & Answering → Backtracking 问题与回答 → 回溯 |
-0.023 | 0.037 | -0.620 | 0.536 |
|
Perspective Shift → Backtracking 视角转换 → 回溯 |
0.007 | 0.071 | 0.100 | 0.924 |
|
Conflict of Perspectives → Backtracking 视角冲突 → 回溯 |
0.163 | 0.065 | 2.530 | 0.011 |
|
Reconciliation → Backtracking 调和 → 回溯 |
-0.005 | 0.082 | -0.060 | 0.953 |
| Positive → Backtracking 正向 → 回溯 | -0.125 | 0.040 | -3.130 | 0.002 |
| Negative → Backtracking 负向 → 回溯 | 0.079 | 0.028 | 2.820 | 0.005 |
| Ask → Backtracking 询问 → 回溯 | -0.024 | 0.016 | -1.510 | 0.132 |
| Give → Backtracking 给予 → 回溯 | 0.014 | 0.006 | 2.320 | 0.020 |
|
DeepSeek-R1 → Backtracking DeepSeek-R1 → 回溯 |
-0.325 | 0.129 | -2.520 | 0.012 |
|
Question & Answering → Subgoal setting 问答 → 子目标设定 |
0.035 | 0.016 | 2.120 | 0.034 |
|
Perspective Shift → Subgoal setting 视角转换 → 子目标设定 |
0.006 | 0.012 | 0.450 | 0.653 |
|
Conflict of Perspectives → Subgoal setting 视角冲突 → 子目标设定 |
-0.036 | 0.016 | -2.220 | 0.026 |
|
Reconciliation → Subgoal setting 和解 → 子目标设定 |
0.089 | 0.021 | 4.270 | <0.001 |
|
Positive → Subgoal setting 正面 → 子目标设定 |
0.010 | 0.012 | 0.830 | 0.409 |
|
Negative → Subgoal setting 负面 → 子目标设定 |
0.007 | 0.004 | 1.680 | 0.093 |
|
Ask → Subgoal setting 询问 → 子目标设定 |
0.005 | 0.010 | 0.540 | 0.587 |
|
Give → Subgoal setting 给予 → 子目标设定 |
0.008 | 0.003 | 2.490 | 0.013 |
|
DeepSeek-R1 → Subgoal setting DeepSeek-R1 → 子目标设定 |
0.224 | 0.087 | 2.570 | 0.010 |
|
Question & Answering → Backward chaining 问答 → 逆向链式推理 |
-0.006 | 0.002 | -3.900 | <0.001 |
|
Perspective Shift → Backward chaining 视角转换 → 逆向推理 |
0.011 | 0.002 | 5.710 | <0.001 |
|
Conflict of Perspectives → Backward chaining 视角冲突 → 逆向推理 |
-0.003 | 0.002 | -1.510 | 0.132 |
|
Reconciliation → Backward chaining 调解 → 逆向推理 |
-0.002 | 0.003 | -0.800 | 0.422 |
|
Positive → Backward chaining 肯定 → 逆向推理 |
-0.002 | 0.001 | -1.720 | 0.086 |
|
Negative → Backward chaining 否定 → 逆向推理 |
0.005 | 0.001 | 3.760 | <0.001 |
|
Ask → Backward chaining Ask → 逆向推理 |
0.004 | 0.001 | 2.870 | 0.004 |
|
Give → Backward chaining Give → 逆向推理 |
0.001 | 0.000 | 2.950 | 0.003 |
|
DeepSeek-R1 → Backward chaining DeepSeek-R1 → 逆向推理 |
0.019 | 0.007 | 2.730 | 0.006 |
|
Question & Answering → Accuracy Question & Answering → 准确率 |
0.009 | 0.001 | 7.730 | <0.001 |
|
Perspective Shift → Accuracy 视角转换 → 准确性 |
-0.006 | 0.001 | -4.250 | <0.001 |
|
Conflict of Perspectives → Accuracy 视角冲突 → 准确性 |
-0.006 | 0.002 | -3.240 | 0.001 |
|
Reconciliation → Accuracy 调和 → 准确性 |
0.001 | 0.003 | 0.330 | 0.742 |
| Positive → Accuracy 正面 → 准确性 | 0.020 | 0.003 | 6.660 | <0.001 |
| Negative → Accuracy 负面 → 准确性 | -0.001 | 0.000 | -1.470 | 0.141 |
| Ask → Accuracy 问 → 准确性 | 0.001 | 0.001 | 0.900 | 0.367 |
| Give → Accuracy 给 → 准确性 | 0.000 | 0.000 | -1.450 | 0.147 |
| Verification → Accuracy 验证 → 准确性 | 0.005 | 0.001 | 3.400 | 0.001 |
| Backtracking → Accuracy 回溯 → 准确性 | -0.003 | 0.001 | -2.810 | 0.005 |
|
Subgoal setting → Accuracy 子目标设定 → 准确性 |
0.009 | 0.004 | 2.610 | 0.009 |
|
Backward chaining → Accuracy 反向链 → 准确性 |
-0.001 | 0.006 | -0.180 | 0.855 |
| DeepSeek-R1 → Accuracy DeepSeek-R1 → 准确性 | 0.253 | 0.007 | 35.060 | <0.001 |
| Length → Accuracy 长度 → 准确性 | -0.134 | 0.005 | -25.410 | <0.001 |
| Observations 观察结果 | 7,738 | |||
Notes: All structural equation models control for task fixed effects. The statistical significance of coefficients is tested using two-sided t-tests. Out of 8,262 tasks, tasks from IFEval are excluded due to difficulties in accuracy evaluation (524 tasks), and we use the remaining 7,738 tasks.
注释:所有结构方程模型均控制任务固定效应。系数的统计显著性通过双侧 t 检验进行检验。在 8,262 个任务中,由于准确性评估困难,排除了来自 IFEval 的任务(524 个任务),我们使用了剩余的 7,738 个任务。