
A Novel Approach to Scalable and Automatic Topic-Controlled Question Generation in Education
一种用于教育领域的可扩展和自动主题控制问题生成的新方法
(2025 年;不可用;不可用;不可用)
Abstract. 摘要。
The development of Automatic Question Generation (QG) models has the potential to significantly improve educational practices by reducing the teacher workload associated with creating educational content. This paper introduces a novel approach to educational question generation that controls the topical focus of questions. The proposed Topic-Controlled Question Generation (T-CQG) method enhances the relevance and effectiveness of the generated content for educational purposes. Our approach uses fine-tuning on a pre-trained T5-small model, employing specially created datasets tailored to educational needs. The research further explores the impacts of pre-training strategies, quantisation, and data augmentation on the model’s performance. We specifically address the challenge of generating semantically aligned questions with paragraph-level contexts, thereby improving the topic specificity of the generated questions. In addition, we introduce and explore novel evaluation methods to assess the topical relatedness of the generated questions. Our results, validated through rigorous offline and human-backed evaluations, demonstrate that the proposed models effectively generate high-quality, topic-focused questions. These models have the potential to reduce teacher workload and support personalised tutoring systems by serving as bespoke question generators. With its relatively small number of parameters, the proposals not only advance the capabilities of question generation models for handling specific educational topics but also offer a scalable solution that reduces infrastructure costs. This scalability makes them feasible for widespread use in education without reliance on proprietary large language models like ChatGPT.
自动问题生成(QG)模型的发展有潜力通过减少教师创建教育内容的工作量来显著改善教育实践。本文介绍了一种控制问题主题焦点的教育问题生成新方法。所提出的主题控制问题生成(T-CQG)方法增强了生成内容的教育相关性和有效性。我们的方法基于预训练的 T5-small 模型进行微调,采用专门为教育需求创建的数据集。研究进一步探讨了预训练策略、量化和数据增强对模型性能的影响。我们特别解决了在段落级上下文中生成语义一致的问题的挑战,从而提高了生成问题的主题特异性。此外,我们引入并探索了新的评估方法来评估生成问题的主题相关性。 我们的结果通过严格的离线评估和人工审核验证,证明所提出的模型能够有效生成高质量、主题聚焦的问题。这些模型有潜力减轻教师工作负担,并通过作为定制化问题生成器来支持个性化辅导系统。凭借其相对较少的参数数量,该提案不仅提升了问题生成模型处理特定教育主题的能力,还提供了一种可扩展的解决方案,从而降低了基础设施成本。这种可扩展性使得它们在教育领域广泛使用成为可能,而无需依赖 ChatGPT 等专有大型语言模型。
教育问题生成、形成性评估、总结性评估、个性化测试、自然语言处理
会议:LAK25:第 15 届国际学习分析与知识会议;2025 年 3 月 3 日至 7 日;爱尔兰都柏林††booktitle: LAK25: The 15th International Learning Analytics and Knowledge Conference (LAK 2025), March 03–07, 2025, Dublin, Ireland
会议名称:LAK25:第 15 届国际学习分析与知识会议(LAK 2025),2025 年 3 月 3 日至 7 日,爱尔兰都柏林††doi: 10.1145/3706468.3706487
doi:10.1145/3706468.3706487††isbn: 979-8-4007-0701-8/25/03
isbn:979-8-4007-0701-8/25/03††ccs: Computing methodologies Natural language generation
ccs:计算方法 自然语言生成††ccs: Computing methodologies Information extraction
ccs:计算方法 信息提取††ccs: Applied computing Interactive learning environments
ccs:应用计算 交互式学习环境
1. Introduction 1. 引言
One of the most significant and pertinent challenges facing education systems today is the teachers’ workload. It is argued to be the main reason behind issues associated with teachers’ retention in the profession as well as the lack of interest among graduate students to go into teaching professions. On the other hand, according to the Global Report on Teachers published by the Teacher Task Force and UNESCO, 44 million additional teachers will be needed by 2030 to meet Sustainable Development Goal 4 (SDG4), which aims to achieve universal primary and secondary education for all (UNESCO and International Task Force on Teachers for Education
2030, 2024), without any improvements to the status quo. Among these concerns, generative AI in education is seen as an opportunity to ’transform a teacher’s day-to-day work’ (for Education, 2024) by reducing their workload and improving educational outcomes through the automation of routine tasks.
当今教育系统面临的最重要和最紧迫的挑战之一是教师的工作量。有人认为这是导致教师职业流失问题以及毕业生对教学职业缺乏兴趣的主要原因。另一方面,根据教师任务小组和联合国教科文组织发布的《教师全球报告》,到 2030 年,为了实现可持续发展目标 4(SDG4),即让所有人人享有全民初级和中等教育(联合国教科文组织和国际教育 2030 教师任务小组,2024 年),在不改变现状的情况下,将需要额外 44 万名教师。在这些担忧中,教育领域的生成式人工智能被视为一个机会,可以通过减少工作量并通过自动化常规任务来提高教育成果,从而“改变教师日常的工作”(教育,2024 年)。
Creating lesson materials and generating topic-specific, relevant, and age-appropriate questions for teaching have long been identified as time-intensive tasks for teachers, and an area where increased consistency is also expected to improve educational outcomes for students (Giannakos et al., 2024). Although learning analytics and AI in Education researchers have long explored ways to support teachers’ question generation capabilities through data-driven insights and models, attempts on Topic-Controlled Question Generation (T-CQG) have been less successful, primarily due to the lack of quality in the generated content. The use of large language models (LLMs) in teacher-facing interfaces, however, has the potential to address these quality concerns by leveraging recent advancements in NLP for automatic educational question generation (EdQG). EdQG can help teachers reduce the labor-intensive task of generating questions to promote classroom discussions, design formative and summative assessments, create lesson hooks, or address student misconceptions which are all activities that teachers consider among the most time-consuming in their profession (for Education, 2024). Although most issues related to teachers’ workload are complex, ecosystem-level socio-technical challenges (Cukurova et al., 2023), T-CQG can serve as a small yet important practical step towards enhancing teachers’ productivity, aiming to mitigate workload and address issues related to teacher retention and attraction to the profession.
创建教学材料和生成与主题相关、适合年龄且恰当的问题,长期以来一直被认为是教师耗时的工作,也是期望通过提高一致性来改善学生学习成果的领域(Giannakos 等人,2024)。尽管学习分析和教育人工智能研究人员长期以来通过数据驱动的见解和模型探索支持教师问题生成能力的方法,但主题控制问题生成(T-CQG)方面的尝试不太成功,主要是因为生成内容的质量不高。然而,在面向教师界面的使用大型语言模型(LLMs),可以通过利用自然语言处理(NLP)的最新进展来自动生成教育问题(EdQG),从而解决这些质量方面的担忧。EdQG 可以帮助教师减少生成问题的劳动密集型任务,以促进课堂讨论、设计形成性评估和总结性评估、创建课程钩子或解决学生的误解,这些活动都是教师认为在其职业中最耗时的活动(教育,2024)。 尽管与教师工作负担相关的大多数问题都很复杂,属于生态系统层面的社会技术挑战(Cukurova 等,2023 年),但 T-CQG(主题控制型问题生成)可以作为一个小而重要的实践步骤,朝着提高教师生产力的方向发展,旨在减轻工作负担,并解决与教师留任和吸引人才相关的问题。
In addition to their potential to support teachers, EdQG (and T-CQG) models can be integrated into learning management systems (LMSs) and intelligent tutoring systems (ITSs), to advance the system’s capability to perform precise diagnostics on learner’s knowledge gaps. The responses received from learners can inform the learning analytics pipeline more precisely and frequently to have a refined learner state representation, that can empower the system with targeted interventions. However, such interventions require advancements to generic neural network question generation models that do not have the ability to contextualise generation with constraints.
除了支持教师外,EdQG(以及 T-CQG)模型可以集成到学习管理系统(LMS)和智能辅导系统(ITS)中,以提升系统对学习者知识差距进行精确诊断的能力。学习者提供的反馈可以更精确、更频繁地输入学习分析流程,从而形成更精细的学习者状态表示,使系统能够实施有针对性的干预。然而,此类干预需要改进通用神经网络问题生成模型,这些模型缺乏在约束条件下进行情境化生成的能力。
The novelties that we introduce through this work are three-fold. We 1) propose a novel method to generate a dataset with contrastive examples in order to effectively train a T-CQG model and 2) validate and propose novel ways of evaluating the topical relatedness of the generations to the controlled topic using semantic relatedness metrics while 3) this is the only work that attempts in using a very small language model (sLM) with parameters, and succeeds in producing a T-CQG neural model.
我们通过这项工作引入的新颖之处有三方面。我们 1) 提出了一种生成具有对比示例的数据集的新方法,以有效地训练 T-CQG 模型,2) 验证并提出了使用语义相关性指标评估生成内容与控制主题相关性的新方法,同时 3) 这是唯一尝试使用参数非常小的语言模型(sLM)并成功生成 T-CQG 神经模型的工作。
2. Problem Definition, Background Research, and Research Questions
2.问题定义、背景研究和研究问题
In this section, we introduce the formal problem definition and prior work, leading to the research questions.
在本节中,我们介绍了正式的问题定义和先前的工作,引出研究问题。
2.1. Problem Definition 2.1.问题定义
Although language models have been employed for question generation, their application in educational settings has only recently begun to be systematically explored with a heavy focus on the potential practical applications of proprietary models (e.g. GPT models’ prompt engineering and RAG applications for question generation). While existing research in relevant academic communities with a more technical focus explores generating questions from descriptive texts (Du et al., 2017; Wang et al., 2018), the task remains highly complex and there is less focus on the educational value of the generated questions in evaluations. Context plays a crucial role in the educational value of EdQG, yet much existing work has focused primarily on generating questions from sentences, paragraphs, or structured data in isolation (Hu et al., 2018; Lopez et al., 2021), with limited attention given to topic-controlled question generation in a given context.
尽管语言模型已被用于生成问题,但它们在教育环境中的应用直到最近才开始系统地探索,重点主要集中在专有模型的潜在实际应用上(例如 GPT 模型的提示工程和用于问题生成的 RAG 应用)。而相关学术领域内更侧重技术的研究则探索从描述性文本中生成问题(Du 等人,2017;Wang 等人,2018),但这项任务仍然非常复杂,且在评估中较少关注生成问题的教育价值。上下文在 EdQG(教育问题生成)的教育价值中起着至关重要的作用,然而大量现有工作主要集中于独立地从句子、段落或结构化数据中生成问题(Hu 等人,2018;Lopez 等人,2021),对在特定上下文中进行主题控制的问题生成关注有限。
Topic-controlled question generation takes a target topic in addition to the descriptive text as context into account while generating the models’ outputs. On the other hand, traditional approaches which take sentences or paragraphs as inputs without contextual topic-control tend to generate questions that arbitrarily combine or select concepts and topics which are likely to be of limited practical value to professionals like teachers. From the learners’ points of view, prior research also suggests a strong correlation between the personalisation of testing and knowledge retention (Bahrick et al., 1993), which further supports the importance of topic-controlled question generation. Developing comprehensive, high quality and relevant educational question sets across different topics can significantly enhance teaching practice and support students through intelligent tutoring systems that provide personalised learning to diverse learners.
主题控制式问题生成在生成模型输出时会考虑目标主题以及描述性文本作为上下文。另一方面,传统方法在不进行主题控制的情况下将句子或段落作为输入,往往生成的问题会任意组合或选择概念和主题,这些内容对教师等专业人士可能缺乏实际价值。从学习者的角度来看,已有研究表明测试的个性化与知识保留之间存在强相关性(Bahrick 等人,1993 年),这进一步支持了主题控制式问题生成的重要性。开发涵盖不同主题的全面、高质量且相关的教育问题集,可以显著提升教学实践,并通过为不同学习者提供个性化学习的智能辅导系统来支持学生。
In the scope of this work, we define topic-controlled question generation (T-CQG) as follows. Let us suppose a learner has already consumed learning materials that contain the knowledge context containing various topics . A goal of a teacher or an intelligent system is then to generate a question , where is an educational question about the target topic , where , and consists of a sequence of tokens of arbitrary length . This task requires that the question is not only contextually relevant to the paragraph context , but also closely aligned with the thematic focus defined by topic . The probability incorporates the coherence and relevance of each token in the sequence, rendering the generation process highly sensitive to both the context and the topic. This task can be mathematically defined to identify the optimal question that maximises the conditional probability as per equation 1.
在本工作的范围内,我们将主题控制问题生成(T-CQG)定义如下。假设学习者 已经消费了包含知识背景 的学习材料,其中包含各种主题 。教师或智能系统的目标则是生成一个问题 ,其中 是一个关于目标主题 的教育问题, ,而 由任意长度的标记序列 组成 。这项任务要求问题不仅与段落背景 在语境上相关,而且与主题 定义的主题焦点紧密一致。概率 包含了序列中每个标记的连贯性和相关性,使得生成过程对语境和主题都非常敏感。这项任务可以通过数学定义来识别能够最大化条件概率的最优问题 ,如方程 1 所示。
| (1) |
where, denotes the conditional probability that also depends on the tokens .
其中, 表示的条件概率也取决于 标记。
2.2. Related Work 2.2. 相关工作
Question Generation (QG) involves automatically generating questions from a specific text passage or a document. The main goal of QG is to produce questions that are not only syntactically and semantically correct but also contextually relevant and meaningful for the intended use. There has been a growing use of computational models to generate contextually relevant and grammatically correct questions (Wang et al., 2024). In educational contexts specifically, QG has been implemented in various systems including intelligent tutoring systems (Yadav et al., 2023), writing support systems (Pinto et al., 2023), and knowledge assessment platforms (Kuo et al., 2023).
问题生成(QG)涉及从特定文本段落或文档中自动生成问题。QG 的主要目标是产生不仅语法和语义正确,而且对预期用途具有上下文相关性和意义的问题。近年来,计算模型被越来越多地用于生成上下文相关且语法正确的问题(Wang 等人,2024)。在教育领域,QG 已被应用于各种系统,包括智能辅导系统(Yadav 等人,2023)、写作支持系统(Pinto 等人,2023)和知识评估平台(Kuo 等人,2023)。
Existing research categorises QG into two types: answer-aware and answer-agnostic (Zhang et al., 2021). In answer-aware QG, the target answer is predetermined, and questions are generated to correspond with this answer within the given text context. On the other hand, answer-agnostic QG does not provide the target answer to the language model, allowing for more open-ended question generation which are considered to be educationally more valuable. However, answer-agnostic QG is a more challenging task for NLP research. Early research in answer-agnostic QG relied heavily on rule-based techniques that required experienced educators to develop rules that could convert declarative sentences into interrogative forms (Heilman and Smith, 2010; Adamson et al., 2013). These methods, while effective, are labour-intensive and time-consuming, demanding significant manual effort in creating high-quality, handcrafted rules (Chen et al., 2021), which inherently limits their scalability and diversity in question generation. These limitations led more recent research investigations to focus on data-driven neural network (NN) approaches.
现有研究将问题生成(QG)分为两种类型:答案感知型与答案非感知型(Zhang 等人,2021)。在答案感知型 QG 中,目标答案预先确定,问题生成是为了在给定文本语境中与该答案相对应。另一方面,答案非感知型 QG 不向语言模型提供目标答案,允许生成更开放的问题,这些问题被认为在教育上更有价值。然而,答案非感知型 QG 对自然语言处理(NLP)研究来说是一项更具挑战性的任务。早期的答案非感知型 QG 研究高度依赖基于规则的技巧,这些技巧需要经验丰富的教育者开发规则,将陈述句转换为疑问句形式(Heilman 和 Smith,2010;Adamson 等人,2013)。虽然这些方法有效,但它们劳动密集且耗时,需要大量人工工作来创建高质量的手工规则(Chen 等人,2021),这本质上限制了它们在问题生成中的可扩展性和多样性。这些局限性促使近期的研究更多地关注数据驱动的神经网络(NN)方法。
Early implementations of QG practices with data-driven approaches predominantly utilized sequence-to-sequence (seq2seq) architectures incorporating Recurrent Neural Networks (RNNs) (Du et al., 2017). More recently, the focus shifted towards employing end-to-end techniques facilitated by deep neural networks (Zhang et al., 2021). For instance, (Dathathri et al., 2020) and (Khalifa et al., 2021) utilised GPT-2 combined with either an attribute classifier or training another autoregressive language model to guide the generated text towards a topic. However, these approaches typically generated content that is too broadly categorised (such as a category being ’science’), failing to achieve the level of topic specificity required for them to be of real-world value for educational practitioners. On the other hand, a more targeted approach by (Hu et al., 2018) employing an LSTM model equipped with a pre-decoding mechanism, demonstrated the ability to generate questions on detailed topics. This model, though promising in its specificity, was only applied at the sentence level, limiting its utility for broader educational applications. More contemporary models leverage pre-trained transformers like GPT (Blobstein et al., 2023; Elkins et al., 2024) (Decoder Only) and T5 (Text-to-Text Transfer Transformer) (Vachev et al., 2022; Bulathwela et al., 2023) (Endoder-Decoder). These advanced NLP approaches like transformer architectures have shown to be effective in generating coherent and relevant questions for specified texts (Faraby et al., 2024). However, their use in meaningful and relevant educational question generation needs further explorations and evaluations in educational contexts (Bulathwela et al., 2023; Vachev et al., 2022). In short, the problem of topic-specific question generation as scoped in section 2.1 has been of interest to multiple researchers in the past, yet it is still an open challenge for the community.
早期采用数据驱动方法进行 QG 实践主要使用了包含循环神经网络(RNNs)的序列到序列(seq2seq)架构(Du 等人,2017)。最近,研究重点转向采用深度神经网络支持端到端技术(Zhang 等人,2021)。例如,(Dathathri 等人,2020)和(Khalifa 等人,2021)利用 GPT-2 结合属性分类器或训练另一个自回归语言模型来引导生成文本朝向特定主题。然而,这些方法通常生成过于宽泛分类的内容(例如一个类别为“科学”),未能达到所需的主题特异性,因此对于教育实践者而言缺乏实际应用价值。另一方面,(Hu 等人,2018)采用配备预解码机制的 LSTM 模型进行更具针对性的方法,展示了生成详细主题问题的能力。尽管该模型在特异性方面具有前景,但仅应用于句子级别,限制了其在更广泛教育应用中的实用性。 更多现代模型利用预训练的转换器,如 GPT(Blobstein 等人,2023 年;Elkins 等人,2024 年)(仅解码器)和 T5(文本到文本迁移转换器)(Vachev 等人,2022 年;Bulathwela 等人,2023 年)(编码器-解码器)。这些先进的自然语言处理方法,如转换器架构,已被证明在为指定文本生成连贯且相关的问题方面是有效的(Faraby 等人,2024 年)。然而,它们在教育环境中生成有意义且相关的问题方面的应用需要进一步探索和评估(Bulathwela 等人,2023 年;Vachev 等人,2022 年)。简而言之,如第 2.1 节所述的特定主题问题生成问题,过去一直引起多位研究人员的兴趣,但它仍然是一个开放的挑战。
One of the significant challenges in research utilising pre-trained transformer architectures for the scoped problem is the issue of making generated content more specifically aligned with the particular topics studied and its contextual considerations. Previous literature in AI in Education research proposed multiple approaches when linking knowledge components of topics to generated learning materials such as questions. The most common approach is expert human labelling, but it is challenging to be scaled even though its accuracy is unmatched (Yudelson et al., 2013) and considered as gold-standard. Due to the scaling challenges of expert human labelling, recent works have also proposed methods such as entity linking (Brank et al., 2017; Ferragina and Scaiella, 2010) that provide scalability even if it tends to sacrifice some accuracy. Another proposed approach is the so-called ”Wikification” which is the practice of using Wikipedia as a source for semantic annotations (Zhang and Rettinger, 2014). The approach has demonstrated significant advancements in recent years and offers considerable potential for automatically extracting concepts from Wikipedia entries to generate topic-specific educational materials (Bulathwela et al., 2021). Additionally, since there has been extensive research on Wikipedia for its potential for semantic labelling of AI-generated content, its concept relatedness metrics that are based on its link structure, page co-occurrence etc. (Ponza et al., 2020) are well developed and can represent semantic relatedness between Wikipedia concepts to a high accuracy. However, the use of approaches that allow scalable solutions such as Wikification (Brank et al., 2017) in educational question generation models is yet to be explored in detail in learning analytics.
在利用预训练的 Transformer 架构进行特定领域问题的研究中,一个重要的挑战是如何使生成内容更精确地与所研究的具体主题相一致,并考虑其上下文因素。AI 教育研究领域的先前文献在将主题的知识组件与生成式学习材料(如问题)联系起来时,提出了多种方法。最常见的方法是专家人工标注,尽管其准确率无与伦比(Yudelson 等,2013 年)并被视为黄金标准,但这种方法难以扩展。由于专家人工标注的扩展挑战,近期的研究也提出了诸如实体链接(Brank 等,2017 年;Ferragina 和 Scaiella,2010 年)等方法,这些方法虽然倾向于牺牲一些准确率,但提供了可扩展性。另一种提出的方法是所谓的“维基化”,即使用维基百科作为语义标注的来源(Zhang 和 Rettinger,2014 年)。 该方法近年来取得了显著进展,并展现出相当大的潜力,能够自动从维基百科条目中提取概念,以生成特定主题的教育材料(Bulathwela 等人,2021)。此外,鉴于维基百科在语义标注人工智能生成内容方面的潜力已得到广泛研究,其基于链接结构、页面共现等概念相关度指标(Ponza 等人,2020)已相当成熟,能够以高精度表示维基百科概念之间的语义相关性。然而,在学习教育分析中,尚未详细探索允许可扩展解决方案(如 Wikification,Brank 等人,2017)在教育问题生成模型中的应用。
2.3. Research Questions 2.3 研究问题
This paper aims to address these challenges associated with the topic-controlled EdGQ. We conducted supervised fine-tuning on a pre-trained T5-small model (hereafter referred to as the T5 model), an approach that is preferable and safer for educational entities to manage and control the language model (LM) with minimal infrastructure costs. The fine-tuning process utilised the novel MixSQuAD dataset, an enrichment of the SQuAD dataset (Rajpurkar et al., 2016), which is a commonly used general question generation dataset characterised by its shallow questions. Additionally, we designed experiments to explore the impacts of pre-training strategies, text data augmentation, and model quantisation on the model’s performance. We evaluated the model on the novel MixKhanQ dataset, derived based on the KhanQ dataset (Gong and Pan, 2022), which features human-like, in-depth questions sourced from Khan Academy, an online education platform. This is designed to assess the model’s effectiveness on academic materials, and its ability to generate educationally meaningful questions to explore its practical value for teaching and learning contexts. Based on these steps, the paper proposes a novel set of models that can perform high-precision topic-controlled educational question generation (T-CQG). The research questions addressed through this work are as follows:
本文旨在解决与主题控制型教育问题生成(EdGQ)相关挑战。我们对预训练的 T5-small 模型(以下简称 T5 模型)进行了监督微调,这是一种更适合教育机构管理和控制语言模型(LM),且基础设施成本最低的方法。微调过程使用了新型 MixSQuAD 数据集,该数据集是对 SQuAD 数据集(Rajpurkar 等人,2016 年)的扩展,后者是一个常用的通用问题生成数据集,其特点是问题较为浅显。此外,我们设计了实验,探索了预训练策略、文本数据增强和模型量化对模型性能的影响。我们在基于 KhanQ 数据集(Gong 和 Pan,2022 年)衍生的新型 MixKhanQ 数据集上评估了模型,该数据集具有类似人类、深入的问题,来源于在线教育平台可汗学院。这是为了评估模型在学术材料上的有效性,以及其生成教育意义问题的能力,以探索其在教学和学习环境中的实际价值。 基于这些步骤,论文提出了一套新型模型,能够实现高精度的主题控制教育问题生成(T-CQG)。本研究通过这项工作解决的研究问题如下:
-
•
RQ1: What are the most representative metrics for automated measures of generated questions on their topic relevance considering human evaluations as the ground truth?
• RQ1:在将人类评估作为基准的情况下,哪些是最能代表自动生成的主题相关性的问题度量指标? -
•
RQ2: Is it feasible to fine-tune a pre-trained language model (PLM) to perform T-CQG?
• RQ2:是否可行通过微调预训练语言模型(PLM)来执行 T-CQG? -
•
RQ3: Can further pre-training of the PLM on scientific text improve the quality of T-CQG?
• RQ3: 对 PLM 进行进一步的科学文本预训练能否提高 T-CQG 的质量? -
•
RQ4: How does model quantisation affect the performance of the fine-tuned models while improving scalability?
• RQ4: 模型量化如何在提高可扩展性的同时影响微调模型的性能? -
•
RQ5: To what extent can data augmentation further improve the quality of T-CQG?
• RQ5: 数据增强能在多大程度上进一步提高 T-CQG 的质量?
3. Methodology 3. 方法论
3.1. Datasets Utilised 3.1.使用的数据集
We used the SQuAD 1.1, the Stanford Question Answering Dataset, comprising over 100,000 questions crafted by crowd workers based on a selection of 536 Wikipedia articles (Rajpurkar et al., 2016) as the source for creating new datasets (SQuAD+, MixSQuAD and MixSQuAD2X as described in section 3.2 below) for finetuning the models. When training the TopicQGedu Model (see section 3.3.3 below), we used PeS2O dataset (Soldaini and Lo, 2023), a collection of scientific abstracts, to perform the pre-training as prior work has shown this may increase the model’s performance in educational settings (Bulathwela et al., 2023).
我们使用了斯坦福问答数据集 SQuAD 1.1,该数据集包含超过 10 万个由众包工作者基于 536 篇维基百科文章(Rajpurkar 等人,2016 年)编写的问题,作为创建新数据集(如 3.2 节下所述的 SQuAD+、MixSQuAD 和 MixSQuAD2X)的来源,用于微调模型。在训练主题控制教育问题生成模型(见 3.3.3 节下)时,我们使用了 PeS2O 数据集(Soldaini 和 Lo,2023 年),这是一个科学摘要的集合,用于进行预训练,因为先前研究表明这可能会提高模型在教育环境中的性能(Bulathwela 等人,2023 年)。
For evaluation, we used the KhanQ dataset (Gong and Pan, 2022) as it presents a more relevant challenge for educational question generation. It includes 1,034 high-quality questions in the STEM fields generated by learners, which aim to probe deep understanding of subjects taught in Khan Academy’s online courses 111https://www.khanacademy.org
为评估,我们使用了 KhanQ 数据集(Gong 和 Pan,2022),因为它为教育问题生成提出了更具相关性的挑战。它包含 1,034 个由学习者生成的 STEM 领域高质量问题,旨在探究 Khan Academy 在线课程中教授内容的深度理解。 1 . Despite its smaller size relative to SQuAD, KhanQ aligns more closely with our objective to generate topic-based and relevant educational questions (as per prior work (Fawzi et al., 2024)). To adapt the dataset for topic-based evaluation, we use the same approach as MixSQuAD (section 3.2.2) to create a dataset with contrasting topic-based questions. We refer to the transformed version of the KhanQ dataset as MixKhanQ dataset.
尽管相对于 SQuAD 来说规模较小,但 KhanQ 与我们的目标——生成基于主题的相关教育问题(根据先前工作(Fawzi 等人,2024))——更为一致。为了使数据集适应基于主题的评估,我们采用与 MixSQuAD(第 3.2.2 节)相同的方法来创建一个具有对比性主题问题的数据集。我们将转换后的 KhanQ 数据集版本称为 MixKhanQ 数据集。
3.2. Creating Novel Datasets for T-CQG
3.2.C.创建用于 T-CQG 的新数据集
A core contribution of this work is to introduce a novel data enrichment method that leads to the creation of new datasets that are derived from conventional question generation datasets. As described in 3.1, we derive the new datasets from SQuAD and KhanQ. These datasets already contain the context and the label question from a human (contrast to in equation 1 which denotes the generated question). We append an additional field to the dataset, Topic , and create three novel datasets, 1) SQuAD+, 2) MixSQuAD, and 3) MixSQuAD2X for the T-CQG task. The process of generating the three datasets is presented in figure 1.
这项工作的核心贡献是引入了一种新的数据增强方法,该方法能够从传统的问答生成数据集中创建新的数据集。如 3.1 所述,我们从 SQuAD 和 KhanQ 中推导出这些新数据集。这些数据集已经包含了人类提供的上下文 和标签问题 (与方程 1 中的 表示生成的问句形成对比)。我们向数据集添加了一个额外的字段——主题 ,并创建了三个新的数据集,用于 T-CQG 任务:1) SQuAD+,2) MixSQuAD,3) MixSQuAD2X。生成这三个数据集的过程如图 1 所示。
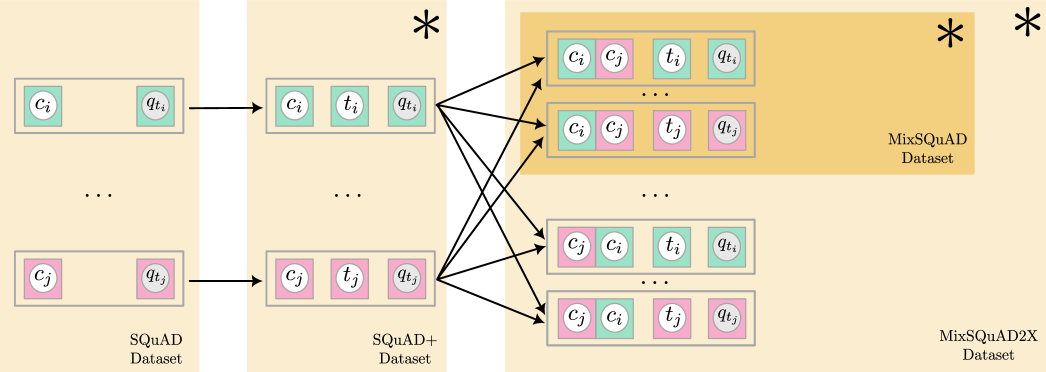
图 1. 模型中从 SQuAD 数据集的上下文 、主题 和目标问题 (阴影为标签)生成不同训练数据集的方法,通过数据集中的两个随机示例,示例 (绿色)和示例 (粉色)进行说明。上下文 和 粘合在一起,是数据集中视为单个字段的连接文本。橙色矩形表示数据集的范围,而(*)标记了新提出的数据集。
3.2.1. Linking the target topic to data points, SQuAD+ dataset
3.2.1.将目标主题链接到数据点,SQuAD+数据集
To identify semantic annotations for every context and question, we employ wikification (Piccinno and Ferragina, 2014), which annotates text inputs with relevant concepts from Wikipedia (). We retain the top 5 concepts for each text (context and question) based on their PageRank scores, which reflect the authority of the concept over the annotated text. To make sure that we can link the topical alignment between the question and the context, we only retain examples where at least one common Wikipedia concept is present between the context and the question pair (i.e. —). We select the concept with the highest PageRank score in the question (most authoritative) as the target topic . This method ensures that the most closely related annotation is selected as the topic for each pair, and confirms that the topic is appropriately aligned with both the context and the question, thus avoiding situations where the topic may be relevant to one but not the other. As a result, both datasets have been enhanced to include paragraph-level contexts , identified topics , and corresponding questions , as shown in figure 1.
为了为每个上下文和问题识别语义标注,我们采用维基化方法(Piccinno 和 Ferragina,2014),该方法使用来自维基百科的相关概念( )对文本输入进行标注。我们根据 PageRank 分数保留每个文本(上下文和问题)的前 5 个概念,这些分数反映了概念对标注文本的权威性。为确保我们能够链接问题与上下文之间的主题一致性,我们仅保留上下文和问题对中至少存在一个共同维基百科概念的情况(即— )。我们选择问题中 PageRank 分数最高的概念(最具权威性)作为目标主题 。这种方法确保为每对选择最密切相关的标注作为主题,并确认主题与上下文和问题都适当对齐,从而避免主题可能仅与其中之一相关的情况。因此,两个数据集都已增强,包括段落级别的上下文 、识别的主题 以及相应的问题 ,如图 1 所示。
3.2.2. MixSQuAD dataset 3.2.2.MixSQuAD 数据集
We also create an enhanced dataset to synthesise a contrastive learning setting while fine-tuning the PLM for T-CQG leading to the MixSQuAD dataset. When creating this dataset, we randomly pick pairs of observations from the SQuAD+ dataset described in section 3.2.1. For each pair of examples and containing and respectively, we create two new examples where they share a common context where the two contexts are concatenated. The data representation of the MixSQuAD dataset is presented in figure 1. This approach aims to enhance the model’s understanding of topics and the relationship between context, topic, and question by serving novel contrastive examples. An added benefit of the novel MixSQuAD dataset is that the context presented to the model during fine-tuning is guaranteed not to be previously encountered in the large corpora used for training foundational models. This method results in a diverse collection of 10,000 mixed data entries in the MixSQuAD dataset, fostering a robust learning environment for the models.
我们还创建了一个增强数据集,用于在微调 PLM 以进行 T-CQG 时合成对比学习环境,从而形成了 MixSQuAD 数据集。在创建这个数据集时,我们从第 3.2.1 节中描述的 SQuAD+数据集中随机挑选观察值对。对于包含 和 的示例对 和 ,我们创建两个新示例,它们共享一个公共上下文 ,其中两个上下文被连接在一起。MixSQuAD 数据集的数据表示如图 1 所示。这种方法旨在通过提供新颖的对比示例来增强模型对主题的理解以及上下文、主题和问题之间关系的学习。新型 MixSQuAD 数据集的一个额外好处是,在微调过程中向模型呈现的上下文保证在用于训练基础模型的大规模语料库中未曾遇到。这种方法在 MixSQuAD 数据集中产生了多样化的 10,000 条混合数据条目,为模型创造了稳健的学习环境。
3.2.3. MixSQuAD2X dataset 3.2.3.MixSQuAD2X 数据集
The MixSQuAD2X dataset is very similar to MixSQuAD dataset, but the main difference is the utilisation of data augmentation to expand the dataset. In contrast to MixSQuAD, we introduce two additional examples to the dataset with the context by reversing the order when concatenating the two randomly chosen contexts. This leads to a dataset that is twice as big as the MixSQuAD dataset.
MixSQuAD2X 数据集与 MixSQuAD 数据集非常相似,但主要区别在于利用数据增强来扩展数据集。与 MixSQuAD 相比,我们在数据集中引入了两个额外的示例,通过在连接两个随机选择的上下文时反转顺序,添加了上下文 。这使得数据集的大小是 MixSQuAD 数据集的两倍。
3.3. Developing T-CQG Models for Education
3.3. 为教育开发 T-CQG 模型
With the relevant datasets created, we built multiple models to be evaluated in a series of experiments to answer the research questions outlined in section 2. All the models used in experiments are created by finetuning the T5-Small (Raffel et al., 2022) model, a small Language Model (sLM) that has also been used for educational question generation in the past (Bulathwela et al., 2023; Fawzi et al., 2024). We fine-tuned the foundational model (t5-small from HuggingFace library222https://huggingface.co/google-t5/t5-small
在创建了相关数据集后,我们构建了多个模型,用于在一系列实验中评估,以回答第 2 节中提出的研究问题。实验中使用的所有模型都是通过微调 T5-Small(Raffel 等人,2022 年)模型创建的,这是一个小型语言模型(sLM),过去也曾用于教育问题生成(Bulathwela 等人,2023 年;Fawzi 等人,2024 年)。我们对基础模型(来自 HuggingFace 库的 t5-small 2 )进行了微调。) using the Adam optimizer with a batch size of 64, the learning rate of , and epsilon of . We use a maximum sequence length of 512 for the encoder, and 128 for the decoder. We train all models for a maximum of 50 epochs with an early stopping based on the validation loss 333https://github.com/Cathgy/Topic-controllable-Question-Generator.git
使用 Adam 优化器,批处理大小为 64,学习率为 ,epsilon 为 。我们将编码器的最大序列长度设置为 512,解码器的最大序列长度设置为 128。我们使用基于验证损失 3 的早停机制,对所有模型进行最多 50 个 epoch 的训练。.
3.3.1. Baseline Model to Answer RQ2
We conducted fine-tuning for T-CQG using the same finetuning approach used by (Martin et al., 2020) for controlling complexity in simplifying texts. We used the proposed SQuAD+ dataset (described in section 3.2.1) to finetune the T5 PLM.
我们使用与 Martin 等人(2020)在简化文本中控制复杂度时采用的相同微调方法,对 T-CQG 进行了微调。我们使用了在第 3.2.1 节中描述的所提出的 SQuAD+数据集来微调 T5 PLM。
3.3.2. TopicQG to Answer RQ2
3.3.2.TopicQG 回答 RQ2
The key difference between the baseline model and the proposed TopicQG model lies in the data used for fine-tuning the T5-small model. We introduced the TopicQG model to contrastive examples using the novel dataset created, MixSQuAD (described in section 3.2.2). Such mixed contexts, which may feature sentences with vastly differing concepts, are designed to enhance the T5 model’s understanding of the semantic relationships between context , topic , and question .
基线模型与所提出的 TopicQG 模型之间的关键区别在于用于微调 T5-small 模型的数据。我们使用创建的新数据集 MixSQuAD(在第 3.2.2 节中描述)向 TopicQG 模型引入对比示例。这些混合上下文可能包含概念差异极大的句子,旨在增强 T5 模型对上下文 、主题 和问题 之间语义关系的理解。
3.3.3. TopicQGedu to Answer RQ3
3.3.3.TopicQGedu 回答 RQ3
Further refining the approach, we developed TopicQGedu, which incorporates an additional pre-training step. In this approach, the sLM model undergoes further training with scientific text documents before being fine-tuned. This step is intended to imbue the model with scientific terminology and concepts, crucial for crafting high-quality educational questions (Bulathwela et al., 2023).
进一步优化该方法,我们开发了 TopicQGedu,它包含一个额外的预训练步骤。在该方法中,sLM 模型在微调之前会使用科学文本文档进行进一步训练。这一步骤旨在使模型具备科学术语和概念,这对于制作高质量的教育问题至关重要(Bulathwela 等人,2023)。
3.3.4. Quantised TopicQG Models to Answer RQ4
3.3.4.用于回答 RQ4 的量化 TopicQG 模型
Quantisation allows reducing the memory footprint of neural models significantly to enhance their scalability. To evaluate the degree of loss due to quantising the trained models, we created the quantised versions of the TopicQG model. We used 8-bit quantisation utilising the LLM.int8 algorithm (Dettmers et al., 2022) and 4-bit precision employing the QLoRa algorithm (Dettmers et al., 2023) to create TopicQG8bit and TopicQG4bit models respectively.
量化可以显著减少神经模型的内存占用,以增强其可扩展性。为了评估因量化训练模型而造成的损失程度,我们创建了 TopicQG 模型的量化版本。我们使用了 8 位量化,采用 LLM.int8 算法(Dettmers 等人,2022 年),以及 4 位精度,采用 QLoRa 算法(Dettmers 等人,2023 年),分别创建了 TopicQG8bit 和 TopicQG4bit 模型。
3.3.5. TopicQG2X to Answer RQ5
3.3.5.用于回答 RQ5 的 TopicQG2X 模型
This model is trained similarly to the Topic QG model, but it exploits data augmentation by being finetuned on the newly proposed MixSQuAD2X dataset (described in section 3.2.3). The MixSQuAD2X dataset effectively doubles its size by changing the order of concatenation of contexts, introducing new examples to finetune the model with. This strategy has the potential to enhance the model’s robustness and generalisation abilities, improving the relevance and educational value of the generated questions to the given topics.
该模型与 Topic QG 模型类似地进行训练,但它通过在新提出的 MixSQuAD2X 数据集(如 3.2.3 节所述)上进行微调来利用数据增强。MixSQuAD2X 数据集通过改变上下文连接的顺序,使其大小翻倍,引入新的示例来微调模型。这种策略有可能增强模型的鲁棒性和泛化能力,提高生成问题与给定主题的相关性和教育价值。
3.3.6. Example Questions Generated with Models for the Experiments
3.3.6. 实验中模型生成的示例问题
Table 1 presents a random set of topic-controlled question generations based on the context text provided in five different subject areas (Computing, Economics, Chemistry, Art, and Biology).
表 1 展示了基于五种不同学科(计算机科学、经济学、化学、艺术和生物学)提供的上下文文本生成的随机主题控制问题集。
表 1. 不同学科领域中 TopicQG 模型的随机生成样本
![[Uncaptioned image]](./一种用于教育领域中可扩展和自动主题控制问题生成的新方法 --- A Novel Approach to Scalable and Automatic Topic-Controlled Question Generation in Education_files/x2.png)
3.4. Human Annotation-based Evaluation of Semantic Relatedness Metrics
3.4. 基于人工标注的语义相关性指标评估
To assess how representative BERTScore and WikiSemRel are when measuring topical relatedness (RQ1). We created a small gold-standard dataset via human annotation. The annotators (n = 4) consisted of two female and two male postgraduate students in the 20-30 age bracket from a masters degree programme at a university in the UK.
为评估 BERTScore 和 WikiSemRel 在衡量主题相关性(RQ1)时的代表性,我们通过人工标注创建了一个小型黄金标准数据集。标注者(n = 4)由来自英国某大学硕士课程的 4 名研究生组成,其中两名女性和两名男性,年龄在 20-30 岁之间。
To set up the annotation task, we randomly selected 30 questions from the MixKhanQ dataset (KhanQ dataset transformed using the method described in section 3.2.2). For each sample, we provided the participants with the reference question and two corresponding generated questions, 1) the question generated using the relevant/prescribed topic and 2) the question generated with an alternative topic. Annotators were required to independently determine which of the two generated questions or is more closely aligned with the reference question, the same tasks the SemRel metrics are going to do. The generated question annotators selected as closely relevant to the reference question is given and the other . We calculated the Mean Absolute Error (MAE) between the mean score assigned by human annotators and the respective SemRel Score as per equation 2.
为了设置标注任务,我们从 MixKhanQ 数据集(使用 3.2.2 节中描述的方法转换的 KhanQ 数据集)中随机选择了 30 个问题。对于每个样本,我们向参与者提供参考问题 以及两个相应的生成问题:1) 使用相关/指定主题生成的 问题,2) 使用替代主题生成的 问题。标注人员需要独立判断两个生成问题 或 中哪一个与参考问题 更一致,这正是 SemRel 指标将要执行的任务。标注人员选出的与参考问题 最相关的生成问题 被赋予,而另一个则被赋予 。我们根据公式 2 计算了人类标注人员分配的平均分数与相应的 SemRel 分数之间的平均绝对误差(MAE)。
| (2) |
3.5. Experimental Setup for Automated Performance Evaluations
3.5. 自动化性能评估的实验设置
Figure 2 illustrates the experimental setup designed to address RQs 2-5. A total of six models (including TopicQG’s base, 8bit, and 4bit versions) have been developed as described in detail in section 3.3 and represented as coloured boxes in figure 2. Each model is evaluated using the MixKhanQ dataset.
图 2 展示了为解决 RQ 2-5 而设计的实验设置。共开发了六个模型(包括 TopicQG 的基础版本、8bit 版本和 4bit 版本),这些模型在 3.3 节中有详细描述,并在图 2 中以彩色方框表示。每个模型都使用 MixKhanQ 数据集进行评估。
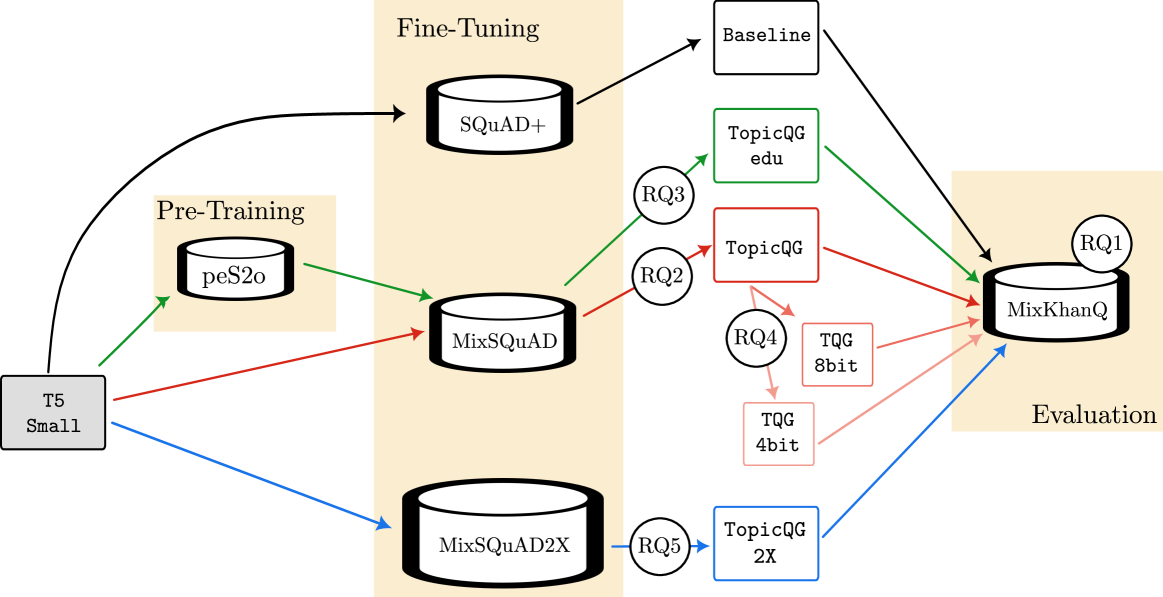
图 2. 训练和评估基线模型(黑色)、TopicQGedu 模型(绿色,RQ3)、TopicQG 模型(深红色,RQ2)、其训练后的量化版本、TopicQG8bit 模型(中红色,RQ4)、TopicQG4bit 模型(浅红色,RQ4)和 TopicQG2X 模型(蓝色,RQ5)的方法。带编号的圆圈表示不同的实验路径,用于测试不同的研究问题。阴影的灰色框表示 T5-Small 模型在实验前已预训练,而非阴影的模型包含在实验中训练的参数。
3.6. Evaluation Metrics 3.6.评估指标
When evaluating the final models, we focused on two main aspects. 1) The generated question is of high linguistic quality so it has the potential to be used in educational settings, 2) The generated question is semantically related to the prescribed topic so that it can address the AI-generated questions’ common problem of being ”too general to be useful in practice” in educational settings.
在评估最终模型时,我们关注了两个主要方面。1) 生成的题目 具有高质量的语法,因此有潜力用于教育环境,2) 生成的题目 与指定主题 具有语义相关性,以便能够解决 AI 生成的题目在教育环境中常见的“过于笼统而缺乏实用性”的问题。
3.6.1. Evaluating the quality of generations
3.6.1.评估生成质量
To assess the quality of the generated questions, the similarity between the reference question and the generated question is measured. We employed a suite of metrics, including BLEU (Papineni et al., 2002), METEOR(Banerjee and Lavie, 2005), ROUGE (Lin, 2004), F1 score, and Perplexity(Hansen et al., 2023), which have been used frequently in previous research (Bulathwela et al., 2023). These metrics provide a comprehensive evaluation of the fluency, relevance, and coherence of the generated questions, serving as scalable indicators of the automated evaluation of the generated questions’ quality.
为了评估生成题目的质量,测量参考题目与生成题目之间的相似度。我们采用了一系列指标,包括 BLEU(Papineni 等人,2002 年)、METEOR(Banerjee 和 Lavie,2005 年)、ROUGE(Lin,2004 年)、F1 分数和困惑度(Hansen 等人,2023 年),这些指标在以往研究中已被频繁使用(Bulathwela 等人,2023 年)。这些指标全面评估了生成题目的流畅性、相关性和连贯性,作为可扩展的自动化评估生成题目质量的指标。
3.6.2. Semantic relatedness between the questions generated and the topic
3.6.2.生成的问题与主题之间的语义相关性
For measuring the semantic relatedness, , we needed metrics that can quantify the relatedness between the reference question and the generated question . We used the BERTScore (Zhang et al., 2020) and the Wikipedia-based Topic Semantic Relatedness (WikiSemRel) (Ferragina and Scaiella, 2010) metrics for these evaluations.
为了衡量语义相关性, ,我们需要能够量化参考问题 和生成问题 之间相关性的指标。我们使用了 BERTScore(Zhang 等人,2020)和基于维基百科的主题语义相关性(WikiSemRel)(Ferragina 和 Scaiella,2010)指标进行这些评估。
BERTScore
leverages BERT contextual embeddings of tokens to calculate the similarity between two text extracts, improving upon the traditional exact match methods. Our early experiments showed that the BERTSCore tend to inflate the similarity between and , as there are words like ”what” and ”why” that overlap even if the generated question is not about the salient topic of the reference question. Therefore, we excluded stopwords in the reference and generated questions prior to calculating the BERTScore. BERTSCore is a score in the range (0,1) where 0 indicates no relatedness.
利用 BERT 词元上下文嵌入来计算两个文本片段之间的相似度,改进了传统的精确匹配方法。我们的早期实验表明,BERTSCore 往往会夸大 和 之间的相似度,即使生成的问句与参考问句的显著主题 无关,也会出现“what”和“why”等词语重叠的情况。因此,我们在计算 BERTScore 之前排除了参考问句和生成问句中的停用词。BERTSCore 是一个介于 0 到 1 之间的分数,其中 0 表示无关联性。
WikiSemRel
quantifies the semantic relatedness between the Wikipedia-based concepts extracted from the reference question and the generated question . We employ the WAT API (Piccinno and Ferragina, 2014) service to calculate semantic relatedness using the 1) w2v-based method, that builds embeddings for Wiki entities based on their co-occurrence in Wikipedia pages and 2) Jaccard-based measure, that uses the outward links to other Wikipedia pages to calculate similarity (Ponza et al., 2020). We Wikify the generated question to compute the WikiSemRel score which is within range (0,1) where 0 indicates no relatedness.
量化了参考问题 中从维基百科提取的概念与生成问题 之间的语义相关性。我们采用 WAT API(Piccinno and Ferragina, 2014)服务来计算语义相关性,使用 1) 基于词嵌入的方法,该方法根据维基百科页面中的共现性为维基百科实体构建嵌入,以及 2) 基于 Jaccard 的方法,该方法使用指向其他维基百科页面的外部链接来计算相似性(Ponza et al, 2020)。我们将生成问题维基化以计算 WikiSemRel 分数,该分数范围在 (0,1) 之间,其中 0 表示无相关性。
4. Results 4. 结果
In this section, we present the results from the experiments described in section 3. The results of the human evaluations answering RQ1 is presented in table 2. The offline evaluations to validate RQ 2-5 following the methodology illustrated in figure 2 are summarised in tables 3 and 4. While table 3 presents metrics relating to the linguistic quality of the generation, Table 4 presents the semantic closeness between the prescribed topic and the generated questions. The perplexity calculation in table 3 is done using the TextDescriptives python library with the en_core_web_lg language model as the reference language distribution (Hansen et al., 2023).
在本节中,我们介绍了第 3 节所述实验的结果。回答 RQ1 的人工评估结果如表 2 所示。按照图 2 所示的方法论进行的 RQ 2-5 的离线评估结果总结在表 3 和表 4 中。表 3 展示了与生成语言质量相关的指标,而表 4 则展示了规定主题与生成问题之间的语义接近度。表 3 中的困惑度计算使用 TextDescriptives python 库,并以 en_core_web_lg 语言模型作为参考语言分布(Hansen 等人,2023)。
表 2.人工标注与语义相关性(SemRel)分数之间的对齐情况。每个指标的最佳性能和次佳性能以粗体和斜体突出显示。
| BERT | WikiSemRel | WikiSemRel | |
| Score 评分 | (w2v) | (Jaccard) | |
| 0.48 | 0.36 | 0.23 |
表 3. 基于 MixKhanQ 数据集,第 3.3 节中提出的模型生成问题的质量评估指标。每个指标的最佳性能和次佳性能以粗体和斜体突出显示。
| Model/Metric 模型/指标 | BLEU1 | BLEU2 | BLEU3 | BLEU4 | F1 Score F1 得分 | METEOR | Perplexity 困惑度 | ROUGE-L |
|---|---|---|---|---|---|---|---|---|
| Baseline 基线 | 0.519 | 0.316 | 0.216 | 0.175 | 0.319 | 0.216 | 1.303 | 0.207 |
| TopicQGedu | 0.551 | 0.335 | 0.221 | 0.177 | 0.302 | 0.216 | 1.360 | 0.204 |
| TopicQG | 0.551 | 0.343 | 0.236 | 0.191 | 0.330 | 0.233 | 1.323 | 0.230 |
| 8bit | 0.546 | 0.339 | 0.231 | 0.186 | 0.319 | 0.226 | 1.327 | 0.225 |
| 4bit 4 位 | 0.543 | 0.337 | 0.231 | 0.186 | 0.318 | 0.223 | 1.334 | 0.223 |
| TopicQG2X | 0.536 | 0.328 | 0.221 | 0.177 | 0.321 | 0.220 | 1.345 | 0.216 |
表 4.生成的题目 在(i)指定主题 与(i)替代主题 以及指定主题的参考题目 之间的语义相关性。每个指标的最佳性能和次佳性能以粗体和斜体突出显示。
| BERTScore | WikiSimRel (Jaccard) | |||||
|---|---|---|---|---|---|---|
| Difference 差异 | Difference 差异 | |||||
| Baseline 基线 | 0.859 | 0.859 | 0.000 | 0.615 | 0.070 | 0.545 |
| TopicQGedu | 0.855 | 0.831 | 0.024 | 0.721 | 0.185 | 0.536 |
| TopicQG | 0.859 | 0.830 | 0.029 | 0.727 | 0.132 | 0.595 |
| 8bit 8 位 | 0.858 | 0.831 | 0.027 | 0.693 | 0.142 | 0.551 |
| 4bit 4 位 | 0.858 | 0.831 | 0.027 | 0.686 | 0.157 | 0.529 |
| TopicQG2X | 0.859 | 0.823 | 0.036 | 0.735 | 0.055 | 0.680 |
4.1. Most Representative Automated Topic Relevance Metric to Human Evaluations (RQ1)
4.1. 最具代表性的自动主题相关性指标与人工评估(RQ1)
In human evaluations of the 30 randomly selected question pairs for topical alignment, only two pairs did not reach a consensus among the participants with one outlier in each case (with the
Fleiss’ kappa (Fleiss, 1971) measure of inter-rater agreement among multiple raters being 0.933). This indicates strong inter-rater reliability in the gold-standard human evaluator data. As per table 2, the WikiSimRel metrics are more aligned with the human judgements in comparison to the BERTScore. Among the three candidates, we can observe the embedding based (BERT and w2v) methods showing inferior representativeness. This could be due to the fact that embeddings can represent many different attributes about the entities and tokens they represent (e.g. whether the text is a question or a statement). This hypothesis is further reinforced by previous observations that including stopwords like ”what”, ”why” leads to the inflation of BERTScore. However the Jaccard WikiSimRel score that relies exclusively on outward links from Wikipedia pages tends to capture a better representation of the informational and thematic content leading to better alignment.
在针对 30 对随机选择的问题对进行主题一致性评估的人类评价中,只有两对在参与者之间未达成共识,每对均有一个极端值(根据多位评价者之间评分者间一致性系数 Fleiss’ kappa(Fleiss,1971)的测量结果为 0.933)。这表明金标准人类评价数据具有极强的评分者间可靠性。根据表 2,与 BERTScore 相比,WikiSimRel 指标更符合人类判断。在三个候选方案中,我们可以观察到基于嵌入(BERT 和 w2v)的方法表现出较差的代表性。这可能是由于嵌入能够表示它们所代表实体和标记的许多不同属性(例如,文本是问题还是陈述)。这一假设得到了先前观察的进一步证实,即包含像“what”、“why”这样的停用词会导致 BERTScore 的膨胀。然而,完全依赖于维基百科页面外部链接的 Jaccard WikiSimRel 分数倾向于更好地捕捉信息内容和主题内容,从而实现更好的一致性。
4.2. Topical Relevance and the Effect of Pre-training on Generated Questions (RQ 2 and RQ 3)
4.2.主题相关性与预训练对生成问题的影响(RQ 2 和 RQ 3)
Table 3 provides us an indication of the degree to which the generated question resembles the reference question . This is a proxy for topical relevance as the reference question is implicitly aligned with the controlled topic. The results indicate that the proposed TopicQG model outperforms the baseline model in all but perplexity metric. Outperforming in terms of BLEU scores at multiple levels (BLEU1 through BLEU4), indicates enhanced linguistic precision in question generation. It also achieves higher F1, ROUGE-L, and METEOR scores, reflecting the model’s capability to generate questions that are not only relevant and accurate but also semantically aligned with reference texts. Compared with the baseline, a slight increase in perplexity suggests that the TopicQG model may generate questions that diverge from the reference language, potentially due to its ability to learn more complex educational expressions. The perplexity does not raise significant concerns over the quality of generations as the random examples in table 1 doesn’t indicate visible signs of deterioration.
It is noteworthy that the randomly selected examples in table 1 are not as good as typical questions generated using a very large language model such as ChatGPT. We hypothesise the size of our model being a main reason for the relatively low quality of generations. However, our own prior work has also shown that such generations can be improved to humanly acceptable levels by simply post-processing them through a pre-trained grammar correction model (Fawzi et al., 2024, [n. d.]) retaining the accessibility and sustainability benefits of sLMs.
表 3 为我们提供了生成问题 与参考问题 相似程度的指示。这可以作为主题相关性的代理指标,因为参考问题与控制主题隐式对齐。结果表明,所提出的 TopicQG 模型在除困惑度指标外所有指标上均优于基线模型。在多个级别的 BLEU 分数(BLEU1 至 BLEU4)上表现更优,表明问题生成中语言精确性得到提升。同时,该模型实现了更高的 F1、ROUGE-L 和 METEOR 分数,反映了其生成的问题不仅相关且准确,而且在语义上与参考文本对齐。与基线模型相比,困惑度略有上升,表明 TopicQG 模型生成的问题可能与参考语言有所偏离,这可能是由于其能够学习更复杂的教肓表达。困惑度的上升并未引起对生成质量显著问题的担忧,因为表 1 中的随机示例并未显示出明显的恶化迹象。 值得注意的是,表 1 中随机选择的示例不如使用 ChatGPT 等大型语言模型生成的典型问题好。我们假设模型的大小是生成质量相对较低的主要原因。然而,我们之前的研究也表明,通过使用预训练的语法纠错模型对生成内容进行后处理,可以将这些生成内容改进到人类可接受的水平(Fawzi 等,2024 年,[n. d.])]) 保留 sLMs 的可访问性和可持续性优势。
Table 4, the stronger indicator of topic alignment gives us evidence that the proposed TopicQG models significantly outperform the baseline. In terms of the semantic difference between the educational questions generated with the controlled topic vs. a different topic (using WikiSimRel (Jaccard), the most representative metric from table 2), all newly proposed models except the 4bit quantised TopicQG model outperforms the baseline. This can be expected as extreme quantisation can deteriorate the accuracy of the model.
表 4 中,更强的主题一致性指标为我们提供了证据,即所提出的 TopicQG 模型显著优于基线模型。在控制主题与不同主题生成的教育问题之间的语义差异方面(使用 WikiSimRel(Jaccard),表 2 中最具代表性的指标),除 4bit 量化 TopicQG 模型外,所有新提出的模型均优于基线模型。这可以预期,因为极端量化会降低模型的准确性。
In terms of the TopicQGedu model that is pre-trained on scientific text, the results are mixed and more difficult to interpret. While it surpasses the predictive performance on the Baseline in a few metrics, it performs below the TopicQG model across all metrics in table 3. While pre-training on scientific content is hypothesised to improve the topical relevance of the model, we do not observe improvements in this case. To rigorously assess whether the observed differences in performance metrics are statistically significant, we alsoconducted a paired t-test comparing the performance scores of TopicQGedu and TopicQG across the same set of questions. The results yielded a p-value of 0.083 (¿0.05), suggesting that there is no statistically significant difference that TopicQGedu underperforms compared to TopicQG. Given that the T5 model is primarily trained on web-crawled data and Wikipedia articles (Raffel et al., 2022), the absence of scientific texts in the training corpus could potentially weaken the model’s performance in scientific concepts and language. Thus pre-training strategies may need to be further explored, especially in specialized domains where deeper domain knowledge might be crucial, even if immediate improvements in conventional metrics are not evident.
对于在科学文本上预训练的 TopicQGedu 模型,结果较为复杂且更难解释。虽然它在某些指标上超越了基线模型的预测性能,但在表 3 的所有指标中,它的表现均低于 TopicQG 模型。尽管预训练科学内容被认为可以提高模型的主题相关性,但在此情况下我们并未观察到改进。为了严格评估性能指标中观察到的差异是否具有统计学意义,我们还进行了配对 t 检验,比较了 TopicQGedu 和 TopicQG 在相同问题集上的性能得分。结果得到 p 值为 0.083(<0.05),表明 TopicQGedu 与 TopicQG 相比没有表现出统计学上的显著差异。鉴于 T5 模型主要在网页爬取数据和维基百科文章上进行训练(Raffel 等,2022),训练语料库中缺乏科学文本可能会削弱模型在科学概念和语言上的性能。 因此,预训练策略可能需要进一步探索,特别是在那些需要更深层领域知识的专门领域,即使在这些传统指标上没有立即的改进。
4.3. Impact of Model Quantisation (RQ4) and Data Augmentation (RQ5)
4.3.模型量化影响(RQ4)和数据增强影响(RQ5)
We investigated the effects of 8-bit and 4-bit quantisation on the TopicQG model (the best-performing model on the MixSQuAD dataset), referred to as TopicQG8bit and TopicQG4bit respectively. In comparison to the TopicQG model, the quantised models retain best performance with respect to metrics such as BLEU, F1-Score, MATEOR and ROUGE-L with very minor decreases () according to table 3. As expected, a drop in performance in comparison to the TopicQG model (with no quantisation) is observed. Similarly in table 4), a small drop in metrics is observed although it is not a drastic difference. This can be attributed to the fact that the generations change to a very small degree with quantisation indicated by the small deviations in table 3.
我们研究了 8 位和 4 位量化对 TopicQG 模型(在 MixSQuAD 数据集上表现最佳的模型)的影响,分别称为 TopicQG8bit 和 TopicQG4bit。与 TopicQG 模型相比,量化模型在 BLEU、F1-Score、MATEOR 和 ROUGE-L 等指标上保持了最佳性能,根据表 3,这些指标仅略有下降 ( )。正如预期,与未量化的 TopicQG 模型相比,性能有所下降。同样地,如表 4 所示,指标略有下降,尽管差异并不显著。这可以归因于量化导致生成内容的变化非常微小,如表 3 中较小的偏差所示。
Regarding memory usage, the full-precision TopicQG model occupies a memory size of MB. In contrast, the TopicQG8bit model significantly reduces this footprint to MB (59%), and the TopicQG4bit model further reduces it to MB (53%). The potential of quantisation demonstrated in this study is twofold: 1) it significantly lowers the hardware requirements for running the models, and 2) it maintains a satisfactory level of performance, making it feasible to deploy educational topic-controllable question generation on platforms where computational resources are limited. This accessibility could dramatically widen the applications of such models, making them more ubiquitous in educational and other real-time interactive applications on mobile devices. The reduction in model size not only implies lower memory requirements but also suggests lower power consumption, leading to cheaper infrastructure costs and a lower carbon footprint. Such properties are crucial for deploying these models in educational contexts of resource-constrained environments such as middle and low-income countries, mobile devices and embedded systems.
关于内存使用情况,全精度的 TopicQG 模型占用内存大小为 MB。相比之下,TopicQG8bit 模型显著减小了这一占用,降至 MB(减少了 59%),而 TopicQG4bit 模型进一步将其降低至 MB(减少了 53%)。本研究中展示的量化潜力体现在两个方面:1)显著降低了运行模型的硬件要求,2)保持了令人满意的工作性能,使得在计算资源有限的平台上部署教育主题可控问题生成成为可能。这种可及性将极大地扩展此类模型的应用范围,使其在教育及其他移动设备实时交互应用中更加普及。模型尺寸的减小不仅意味着更低的内存需求,也暗示了更低的功耗,从而降低基础设施成本和碳足迹。这些特性对于在资源受限的教育环境中部署这些模型至关重要,例如中低收入国家、移动设备和嵌入式系统。
The comparisons between TopicQG and TopicQG2X models in table 4 show that the data augmentation has an obvious effect on improving the models performance on topical relevance. The greater diversity of examples where the same example is presented to the model in two different ways helps the model better understand to follow the topical theme prescribed in the instruction with the context. It surpasses all other models, including TopicQG, demonstrating superior alignment of the generated questions with the input context and topic. This highlights the effectiveness of data augmentation in enhancing the model’s capacity to generate questions with topic relevance and better contextual consideration of texts.
表 4 中 TopicQG 与 TopicQG2X 模型的对比显示,数据增强对提升模型在主题相关性方面的性能有显著效果。相同示例以两种不同方式呈现的多样性帮助模型更好地理解并遵循指令中规定的主题主题,结合上下文进行理解。它超越了包括 TopicQG 在内的所有其他模型,展示了生成问题与输入上下文和主题的更高一致性。这突显了数据增强在提升模型生成主题相关问题的能力以及更好地考虑文本上下文方面的有效性。
5. Discussion 5. 讨论
This paper tackled the challenge of topic-based educational question generation with a high degree of specificity. Due to the novelty of the task itself, we evolved our method over multiple steps to propose a method that can lead to high-quality T-CQG while validating novel approaches to evaluate the topical relevance of such generations. The results show that the novel method proposed and evaluated here is capable of generating topical educational questions while retaining coherent grammatical structure. Further experiments also showed how data augmentation increases the model’s performance in topical relevance leading to improved results. The final experiments exploring quantisation indicate that the model’s memory footprint can be halved with minimal loss of generative performance. Supported by human evaluation, the findings provide solid evidence that the questions generated by the proposed model are of high quality and meaningfully related to the educational content and topics, thereby affirming the effectiveness of our topic-controllable educational question generator.
本文解决了基于主题的教育问题生成的高度具体化挑战。由于任务本身的创新性,我们分多步演化了我们的方法,提出了一个能够生成高质量主题控制问题生成(T-CQG)的方法,同时验证了评估此类生成内容主题相关性的新方法。结果表明,本文提出并评估的新方法能够生成主题相关的教育问题,同时保持连贯的语法结构。进一步的实验还展示了数据增强如何提高模型在主题相关性方面的性能,从而获得更好的结果。最后的实验探索了量化,表明模型的内存占用可以减半,同时生成性能损失最小。在人工评估的支持下,这些发现提供了有力证据,证明所提出模型生成的问题具有高质量,且与教育内容和主题有实质性关联,从而证实了我们主题控制教育问题生成器的有效性。
Similar to trends in educational research in general (Denny et al., 2024), the interest in the use of Generative Artificial Intelligence (GenAI) in LA research community has significantly increased in recent years. Regarding content generation, LLMs are used in tackling challenges such as grammar/ code correction (Cotet et al., 2020; Do Viet and Markov, 2023), question generation (Elkins et al., 2024; Fawzi et al., 2024), explanations and hints provision (Pardos and Bhandari, 2023; Li et al., 2024), in STEM subjects such as mathematics (Amini et al., 2019; Cobbe et al., 2021) and science (Malinka et al., 2023; Elkins et al., 2024; Bulathwela et al., 2023) to non-STEM domains like law (Cui et al., 2023) and language learning (Caines et al., 2023). Nevertheless, the majority of the community resorts to in-context learning (Dong et al., 2022) within enormous LLMs such as ChatGPT (Denny et al., 2024). For instance, there are increasing numbers of attempts of topic-controlled EdQG relying on Model-as-a-Service (MaaS) products that use externally hosted LLMs like ChatGPT (e.g. (Elkins et al., 2024)). While practically valuable to varying degrees of success, these approaches introduce significant privacy, ethics, and governance challenges (Giannakos et al., 2024). The extensive costs associated with the training and deployment of these models on-premise also make them impractical for educational stakeholders from both operational and financial perspectives (Fawzi et al., 2024).
与教育研究领域的总体趋势相似(Denny 等人,2024),近年来 LA 研究界对生成式人工智能(GenAI)的应用兴趣显著增加。在内容生成方面,LLMs 被用于解决诸如语法/代码纠错(Cotet 等人,2020;Do Viet 和 Markov,2023)、问题生成(Elkins 等人,2024;Fawzi 等人,2024)、提供解释和提示(Pardos 和 Bhandari,2023;Li 等人,2024)等挑战,涉及 STEM 学科(如数学(Amini 等人,2019;Cobbe 等人,2021)和科学(Malinka 等人,2023;Elkins 等人,2024;Bulathwela 等人,2023)等非 STEM 领域(如法律(Cui 等人,2023)和语言学习(Caines 等人,2023))。然而,该领域的大多数人依赖于在大型 LLM(如 ChatGPT(Denny 等人,2024))中的情境学习(Dong 等人,2022)。例如,越来越多地尝试使用基于模型即服务(MaaS)产品进行主题控制的教育问题生成(EdQG),这些产品使用外部托管的 LLM(如 ChatGPT(例如(Elkins 等人,2024))。 虽然这些方法在实用价值上取得不同程度的成功,但它们引入了显著的隐私、伦理和治理挑战(Giannakos 等人,2024)。这些模型在本地训练和部署所涉及的巨大成本,也使得它们对教育相关方从运营和财务角度来看都不切实际(Fawzi 等人,2024)。
We argue that over-reliance on such commercial models in academic research is a threat to academic independence and encourages alternative investigations to address significant challenges of education. The novel approach proposed in this paper provides significant opportunities to enhance the applicability of language models in educational contexts for question generation without the limitations posed by approaches relying on externally hosted LLMs like ChatGPT. The model proposed here has the potential to be scaled at a minimal cost in a safe and ethical manner and can be utilised to generate questions that are closely aligned with the specific content of educational materials. The 4-bit quantisation described reduces the model size to 94.41 MB while preserving essential performance, showcasing its potential for widespread use in resource-limited educational scenarios such as mobile devices and embedded systems. Therefore, the model has the potential for decreasing teachers workload on question generation in diverse contexts as well as being utilised in LMSs and ITSs to facilitate personalised learning experiences, allowing educational questions posed to be customised to meet the unique needs and interests of each learner (such as a learner model (Qiu et al., 2024)).
我们认为,在学术研究中过度依赖此类商业模型是对学术独立性的威胁,并鼓励替代性研究以应对教育中的重大挑战。本文提出的创新方法为在教育环境中增强语言模型在问题生成方面的适用性提供了重要机遇,且不受依赖外部托管 LLM(如 ChatGPT)的方法所带来的限制。本文提出的模型具有以极低成本安全、合乎道德地进行扩展的潜力,并可用于生成与教育材料具体内容紧密相关的问题。所描述的 4 位量化将模型大小减少到 94.41 MB,同时保留了核心性能,展示了其在资源有限的教育场景(如移动设备和嵌入式系统)中广泛应用的潜力。 因此,该模型有潜力减少教师在不同情境下进行问题生成的负担,并且可以应用于学习管理系统(LMS)和智能教学系统(ITS)中,以促进个性化学习体验,使提出的教育问题能够根据每个学习者的独特需求和兴趣进行定制(例如学习者模型(Qiu 等人,2024))。
5.1. Implications of the Results for Research and Practice
5.1. 研究与实践的启示
Regarding educational practice, the proposed topic-controlled question generating model can be useful for different tasks within the education domain. Primarily, we see such a tool as a teacher assistant tool to propose questions to teachers to select from. Such a tool would keep teachers in the loop as final decision makers but help them with tasks such as generating topic-specific, relevant, and age-appropriate questions for teaching. As discussed in the introduction, these tasks have long been identified as time-intensive tasks for teachers (Giannakos et al., 2024). We envision tools where a teacher can point the system to a video, a presentation or a collection of learning resources where the system will automatically detect numerous salient topics and present them to the teacher as potential educational questions and the draft of a new quiz can be created in a matter of few clicks. This approach has the potential to change the degree of formative assessment due to decreased workload and can further stimulate well-anticipated innovation in education systems (Luckin and Cukurova, 2019). We argue that the model proposed and evaluated here has the potential to decrease teachers’ workload on such tasks.
在教育实践中,所提出的主题控制问题生成模型可用于教育领域的不同任务。主要而言,我们视此类工具为教师辅助工具,向教师提供可供选择的问题。此类工具将使教师作为最终决策者保持参与,同时帮助教师完成生成与主题相关、适用且符合年龄特点的教学问题的任务。正如引言中所述,这些任务长期以来一直被视为教师耗时的工作(Giannakos 等人,2024)。我们设想教师可以指向系统一个视频、演示文稿或学习资源集合,系统将自动检测多个显著主题,并将其呈现给教师作为潜在的教育问题,新测验的草稿可在几次点击内创建。这种做法由于减轻了工作量,有潜力改变形成性评估的程度,并进一步激发教育体系中期待已久的创新(Luckin 和 Cukurova,2019)。 我们认为,这里提出并评估的模型有潜力减少教师在这些任务上的工作量。
Second, the model can be integrated into multiple roles within the learning analytics infrastructures. The key to a precise learner state representation is having precise tests that can verify skill mastery of individuals at finer grain. The proposed method can lead to tools that can generate high-precision assessments within a personalised learning management system that can feed better data into learning analytics. While investing significant resources to create a relatively high coverage question banks is still feasible for short course and MOOC platforms that focus on narrow scopes of knowledge, as the world is gradually moving towards informal, lifelong learning such an investment would be infeasible. Models such as the one proposed here can play a critical role for continuous topic-specific, high quality and relevant question generation in educational systems.
其次,该模型可以集成到学习分析基础设施的多个角色中。精确的学员状态表示的关键在于拥有能够更精细地验证个人技能掌握程度的精确测试。所提出的方法可以导致在个性化学习管理系统中生成高精度评估的工具,从而为学习分析提供更好的数据。虽然为短期课程和专注于狭窄知识领域的 MOOC 平台投入大量资源创建相对高覆盖率的题库仍然是可行的,但随着世界逐渐向非正式、终身学习转变,这种投入将变得不可行。像这里提出的模型这样的模型,可以在教育系统中发挥关键作用,实现持续的主题特定、高质量且相关的题目生成。
Third, the model can also bring efficiencies to the implementation of question generation in mobile and resource scarce contexts. As we are dealing with very small models, systems built on these models are scalable with minimal costs and has the potential to run on mobile devices without having to connect to the Internet. These considerations are of utmost importance for more equitable use of AI in Education (Bulathwela et al., 2024).
第三,该模型也能为移动设备和资源匮乏环境中的问题生成实施带来效率。由于我们处理的是非常小的模型,基于这些模型构建的系统具有可扩展性且成本极低,并且有潜力在不连接互联网的情况下在移动设备上运行。这些考虑对于教育中 AI 的更公平使用至关重要(Bulathwela 等人,2024)。
Regarding LA and AI in Education research in general, the methodology proposed in this work can be extended to other forms of generation such as feedback, explanations, and content summaries in education. Also, aspects that that go beyond topical relevance (such as linguistic complexity and cognitive load etc.) can be controlled in future explorations to further advance learning analytics systems paving the way to re-imagining the limits of personalised learning material generation with AI. Furthermore, existing research either ignores the evaluation of whether the generated questions truly respond to the controlled conditions, or relies on extensive manual scoring by humans, which is both time-consuming and labour-intensive (Yudelson et al., 2013). Experimental studies with human participants presented here indicate that the ”relatedness score” has the potential to serve as a robust evaluation metric for assessing the semantic relatedness of generated questions to the input text, particularly in educational question generation tasks. It appears to excel in distinguishing between different concepts within the same academic field, making it particularly relevant for educational question generation tasks. As educational content generation research increases in LA literature, the importance of evaluation metrics of such content becomes even more important and the findings of this paper can help researchers consider appropriate metrics.
关于教育领域中的学习分析与人工智能研究,本工作中提出的方法可以扩展到其他形式的生成,如反馈、解释和内容摘要。此外,在未来的探索中,可以控制那些超越主题相关性的方面(如语言复杂性和认知负荷等),以进一步推进学习分析系统,为重新构想人工智能在个性化学习材料生成方面的极限铺平道路。此外,现有研究要么忽略了评估生成的题目是否真正符合控制条件,要么依赖于人工进行大量评分,这既耗时又费力(Yudelson 等人,2013)。这里展示的涉及人类参与者的实验研究表明,“相关性分数”有潜力作为评估生成题目与输入文本语义相关性的可靠指标,特别是在教育题目生成任务中。 它似乎在区分同一学术领域内的不同概念方面表现出色,因此特别适用于教育问题生成任务。随着教育内容生成研究在 LA 文献中的增加,此类内容评估指标的重要性也日益凸显,本文的研究结果可以帮助研究人员考虑合适的指标。
6. Conclusion 6.结论
This paper proposes a novel approach to fine-tuning pre-trained sLMs to effectively address the challenge of generating topic-controllable questions based on paragraph-level context within educational settings. In addition, a novel method to synthesise training data for this task is presented with a novel Wikipedia concept-based evaluation method. The results show that the model proposed here has the potential to decrease teacher workload and improve personalised learning platforms also proving the effectiveness of training data. The model can also be scaled financially and operationally at a minimal cost to decrease academic researchers’ over-reliance on commercial LLMs like ChatGPT.
本文提出了一种新颖的方法,用于微调预训练的 sLMs,以有效应对在教育环境中基于段落级上下文生成主题可控问题的挑战。此外,还提出了一种合成此任务训练数据的新方法,并采用了一种基于维基百科概念的新颖评估方法。结果表明,本文提出的模型有潜力减少教师工作量,提升个性化学习平台,同时也证明了训练数据的有效性。该模型还可以在财务和运营上进行扩展,以最低成本减少学术研究人员对 ChatGPT 等商业 LLMs 的过度依赖。
This study, while advancing topic-controllable question generation in education, acknowledges several limitations. The limited human evaluation sample size hinders the statistical power of our findings about the semantic relatedness metrics although the extremely high inter-annotator agreement improves reliability of the result. More extensive human annotations would strengthen the results further. While we demonstrate the proposed novel method that randomly pairs contexts enabling the model T-CQG performance to improve, different pairing strategies that respect the subject domain, subtopics, difficulty level etc. can also lead to more effective training sets and should be explored in future studies. Finally, while the proposed method can be used to train the pre-trained model to contextualise generations to topical relevance, it focuses on topical relevance only. However, how to incorporate multiple aspects in addition to topical relevance such as linguistic complexity and generation length (e.g. short question) together should be explored in the future.
这项研究在推进教育领域中主题可控问题生成的同时,也承认存在一些局限性。由于人工评估样本量有限,虽然极高的标注者间一致性提高了结果的可靠性,但我们的语义相关性指标研究结果统计效力受到限制。更广泛的人工标注将进一步强化结果。尽管我们展示了所提出的创新方法——通过随机配对上下文使模型 T-CQG 性能得到提升,但尊重学科领域、子主题、难度等级等的不同配对策略也能产生更有效的训练集,这些策略应在未来的研究中进行探索。最后,虽然所提出的方法可用于训练预训练模型以使生成内容与主题相关,但它仅关注主题相关性。然而,如何在主题相关性之外结合其他方面(如语言复杂性和生成长度(例如短问题))进行探索,应在未来研究中加以考虑。
Acknowledgements. 致谢。
This work is funded by the European Commission-funded projects ”Humane AI” (Grant No. 820437) and ”X5GON” (Grant No. 761758). This research is also part of the Teacher-AI Complementarity (TaiCo) project funded by the European Commission’s Horizon Program (Project ID: 101177268).这项工作得到了欧洲委员会资助的项目“仁心 AI”(资助编号 820437)和“X5GON”(资助编号 761758)的资助。这项研究也是由欧洲委员会“地平线计划”资助的教师-人工智能互补性(TaiCo)项目(项目编号 101177268)的一部分。
References
- (1)
- Adamson et al. (2013) Derek Adamson, Deepak Bhartiya, Baljeet Gujral, Ritu Kedia, Ankit Singh, and Carolyn P. Rose. 2013. Automatically Generating Discussion Questions. In Proceedings of the International Conference on Artificial Intelligence in Education (AIED).
- Amini et al. (2019) Aida Amini, Saadia Gabriel, Peter Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. 2019. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. arXiv preprint arXiv:1905.13319 (2019).
- Bahrick et al. (1993) H. P. Bahrick, L. E. Bahrick, A. S. Bahrick, and P. E. Bahrick. 1993. Maintenance of foreign language vocabulary and the spacing effect. Psychological Science 4, 5 (1993), 316–321.
- Banerjee and Lavie (2005) S. Banerjee and A. Lavie. 2005. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 65–72.
- Blobstein et al. (2023) Ariel Blobstein, Daniel Izmaylov, Tal Yifat, Michal Levy, and Avi Segal. 2023. Angel: A New Generation Tool for Learning Material based Questions and Answers. In Proc. of the NeurIPS Workshop on Generative AI for Education (GAIED).
- Brank et al. (2017) Janez Brank, Gregor Leban, and Marko Grobelnik. 2017. Annotating Documents with Relevant Wikipedia Concepts. In Proc. of Slovenian KDD Conference on Data Mining and Data Warehouses (SiKDD).
- Bulathwela et al. (2023) Sahan Bulathwela, Hamze Muse, and Emine Yilmaz. 2023. Scalable educational question generation with pre-trained language models. In International Conference on Artificial Intelligence in Education. Springer, 327–339.
- Bulathwela et al. (2024) Sahan Bulathwela, María Pérez-Ortiz, Catherine Holloway, Mutlu Cukurova, and John Shawe-Taylor. 2024. Artificial intelligence alone will not democratise education: On educational inequality, techno-solutionism and inclusive tools. Sustainability 16, 2 (2024), 781.
- Bulathwela et al. (2021) Sahan Bulathwela, María Pérez-Ortiz, Emine Yilmaz, and John Shawe-Taylor. 2021. Semantic TrueLearn: using semantic knowledge graphs in recommendation systems. arXiv preprint arXiv:2112.04368 (2021).
- Caines et al. (2023) Andrew Caines, Luca Benedetto, Shiva Taslimipoor, Christopher Davis, et al. 2023. On the application of large language models for language teaching and assessment technology. arXiv preprint arXiv:2307.08393 (2023).
- Chen et al. (2021) Feng Chen, Jiayuan Xie, Yi Cai, Tao Wang, and Qing Li. 2021. Difficulty-Controllable Visual Question Generation. In Proc. Web and Big Data: International Joint Conference. Springer-Verlag, 332–347.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021).
- Cotet et al. (2020) Teodor-Mihai Cotet, Stefan Ruseti, and Mihai Dascalu. 2020. Neural grammatical error correction for romanian. In 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI). IEEE, 625–631.
- Cui et al. (2023) Jiaxi Cui, Zongjian Li, Yang Yan, Bohua Chen, and Li Yuan. 2023. Chatlaw: Open-source legal large language model with integrated external knowledge bases. arXiv preprint arXiv:2306.16092 (2023).
- Cukurova et al. (2023) Mutlu Cukurova, Xin Miao, and Richard Brooker. 2023. Adoption of artificial intelligence in schools: unveiling factors influencing teachers’ engagement. In International conference on artificial intelligence in education. Springer, 151–163.
- Dathathri et al. (2020) Sumanth Dathathri, Andrea Madotto, Janice Lan, Jane Hung, Eric Frank, Piero Molino, Jason Yosinski, and Rosanne Liu. 2020. Plug and Play Language Models: A Simple Approach to Controlled Text Generation. In International Conference on Learning Representations. https://openreview.net/forum?id=H1edEyBKDS
- Denny et al. (2024) Paul Denny, Sumit Gulwani, Neil T. Heffernan, Tanja Käser, Steven Moore, Anna N. Rafferty, and Adish Singla. 2024. Generative AI for Education (GAIED): Advances, Opportunities, and Challenges. arXiv:2402.01580 [cs.CY] https://arxiv.org/abs/2402.01580
- Dettmers et al. (2022) Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale. arXiv preprint arXiv:2208.07339 (2022).
- Dettmers et al. (2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLora: Efficient Fine-Tuning of Quantized LLMs. arXiv preprint arXiv:2305.14314 (2023).
- Do Viet and Markov (2023) Tung Do Viet and Konstantin Markov. 2023. Using Large Language Models for Bug Localization and Fixing. In 2023 12th International Conference on Awareness Science and Technology (iCAST). IEEE, 192–197.
- Dong et al. (2022) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2022. A survey on in-context learning. arXiv preprint arXiv:2301.00234 (2022).
- Du et al. (2017) Xinya Du, Junru Shao, and Claire Cardie. 2017. Learning to Ask: Neural Question Generation for Reading Comprehension. In Proc. Annual Meeting of the Association for Computational Linguistics. 1342–1352.
- Elkins et al. (2024) Sabina Elkins, Ekaterina Kochmar, Jackie CK Cheung, and Iulian Serban. 2024. How Teachers Can Use Large Language Models and Bloom’s Taxonomy to Create Educational Quizzes. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 23084–23091.
- Faraby et al. (2024) Said Al Faraby, Ade Romadhony, and Adiwijaya. 2024. Analysis of LLMs for educational question classification and generation. Computers and Education: Artificial Intelligence 7 (2024), 100298. https://doi.org/10.1016/j.caeai.2024.100298
- Fawzi et al. ([n. d.]) Fares Fawzi, Sadie Amini, and Sahan Bulathwela. [n. d.]. Small Generative Language Models for Educational Question Generation. In Proc. of the NeurIPS Workshop on Generative AI for Education (GAIED).
- Fawzi et al. (2024) F. Fawzi, S. Balan, M. Cukurova, E. Yilmaz, and S. Bulathwela. 2024. Towards Human-Like Educational Question Generation with Small Language Models. In Artificial Intelligence in Education. Posters and Late Breaking Results, Workshops and Tutorials, Industry and Innovation Tracks, Practitioners, Doctoral Consortium and Blue Sky, Vol. 2150. Springer, Cham.
- Ferragina and Scaiella (2010) Paolo Ferragina and Ugo Scaiella. 2010. TAGME: on-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (Toronto, ON, Canada) (CIKM ’10). Association for Computing Machinery, New York, NY, USA, 1625–1628. https://doi.org/10.1145/1871437.1871689
- Fleiss (1971) Joseph L. Fleiss. 1971. Measuring nominal scale agreement among many raters. Psychological Bulletin 76, 5 (1971), 378–382.
- for Education (2024) Department for Education. 2024. Use Cases for Generative AI in Education: User Research Report. Technical Report. Department for Education, UK Government. https://www.gov.uk/government/publications/generative-ai-in-education-user-research-and-technical-report Accessed: 2024-09-21.
- Giannakos et al. (2024) Michail Giannakos, Roger Azevedo, Peter Brusilovsky, Mutlu Cukurova, Yannis Dimitriadis, Davinia Hernandez-Leo, Sanna Järvelä, Manolis Mavrikis, and Bart Rienties. 2024. The promise and challenges of generative AI in education. Behaviour & Information Technology (2024), 1–27.
- Gong and Pan (2022) Huanli Gong and Hengchang Pan, Liangming andHu. 2022. KHANQ: A Dataset for Generating Deep Questions in Education. In Proceedings of the 29th International Conference on Computational Linguistics.
- Hansen et al. (2023) Lasse Hansen, Ludvig Renbo Olsen, and Kenneth Enevoldsen. 2023. TextDescriptives: A Python package for calculating a large variety of metrics from text. Journal of Open Source Software 8, 84 (April 2023), 5153. https://doi.org/10.21105/joss.05153
- Heilman and Smith (2010) Michael Heilman and Noah A. Smith. 2010. Good question! Statistical ranking for question generation. In Proceedings of the Human Language Technology Conference and the North American Chapter of the Association for Computational Linguistics (HLT-NAACL).
- Hu et al. (2018) Wenpeng Hu, Bing Liu, Rui Yan, Dongyan Zhao, and Jinwen Ma. 2018. Topic-Based Question Generation. In International Conference on Learning Representations. ICLR 2018 Conference Blind Submission. Invite to Workshop Track.
- Khalifa et al. (2021) Muhammad Khalifa, Hady Elsahar, and Marc Dymetman. 2021. A Distributional Approach to Controlled Text Generation. In International Conference on Learning Representations. https://openreview.net/forum?id=jWkw45-9AbL
- Kuo et al. (2023) Bor-Chen Kuo, Frederic TY Chang, and Zong-En Bai. 2023. Leveraging LLMs for Adaptive Testing and Learning in Taiwan Adaptive Learning Platform (TALP).. In Workshop on Empowering Education with LLMs at AIED. 101–110.
- Li et al. (2024) Hai Li, Chenglu Li, Wanli Xing, Sami Baral, and Neil Heffernan. 2024. Automated Feedback for Student Math Responses Based on Multi-Modality and Fine-Tuning. In Proceedings of the 14th Learning Analytics and Knowledge Conference. 763–770.
- Lin (2004) C. Y. Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Workshop on Text Summarization Branches Out.
- Lopez et al. (2021) L. E. Lopez, D. K. Cruz, J. C. B. Cruz, and C. Cheng. 2021. Simplifying Paragraph-level Question Generation via Transformer Language Models. In Proceedings of the PRICAI 2021: Trends in Artificial Intelligence (8–12 November 2021). Hanoi, Vietnam.
- Luckin and Cukurova (2019) Rosemary Luckin and Mutlu Cukurova. 2019. Designing educational technologies in the age of AI: A learning sciences-driven approach. British Journal of Educational Technology 50, 6 (2019), 2824–2838.
- Malinka et al. (2023) Kamil Malinka, Martin Peresíni, Anton Firc, Ondrej Hujnák, and Filip Janus. 2023. On the educational impact of chatgpt: Is artificial intelligence ready to obtain a university degree?. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education, Vol. 1. 47–53.
- Martin et al. (2020) Louis Martin, Éric Villemonte de La Clergerie, Benoît Sagot, and Antoine Bordes. 2020. Controllable Sentence Simplification. In LREC 2020 - 12th Language Resources and Evaluation Conference. Marseille, France. https://inria.hal.science/hal-02678214
- Papineni et al. (2002) K. Papineni, S. Roukos, T. Ward, and W.J. Zhu. 2002. BLEU: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting on association for computational linguistics. Association for Computational Linguistics, 311–318.
- Pardos and Bhandari (2023) Zachary A Pardos and Shreya Bhandari. 2023. Learning gain differences between ChatGPT and human tutor generated algebra hints. arXiv preprint arXiv:2302.06871 (2023).
- Piccinno and Ferragina (2014) Francesco Piccinno and Paolo Ferragina. 2014. From TagME to WAT: a new entity annotator. In Proceedings of the First International Workshop on Entity Recognition & Disambiguation (ERD ’14). Association for Computing Machinery, 55–62. https://doi.org/10.1145/2633211.2634350
- Pinto et al. (2023) Gustavo Pinto, Isadora Cardoso-Pereira, Danilo Monteiro, Danilo Lucena, Alberto Souza, and Kiev Gama. 2023. Large language models for education: Grading open-ended questions using chatgpt. In Proceedings of the XXXVII Brazilian Symposium on Software Engineering. 293–302.
- Ponza et al. (2020) Marco Ponza, Paolo Ferragina, and Soumen Chakrabarti. 2020. On Computing Entity Relatedness in Wikipedia, with Applications. Knowledge-Based Systems 188 (2020).
- Qiu et al. (2024) Yuxiang Qiu, Karim Djemili, Denis Elezi, Aaneel Shalman Srazali, María Pérez-Ortiz, Emine Yilmaz, John Shawe-Taylor, and Sahan Bulathwela. 2024. A Toolbox for Modelling Engagement with Educational Videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 23128–23136.
- Raffel et al. (2022) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2022. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. The Journal of Machine Learning Research 21, 1 (2022), 5485–5551.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv:1606.05250 [cs.CL] https://arxiv.org/abs/1606.05250
- Soldaini and Lo (2023) Luca Soldaini and Kyle Lo. 2023. peS2o (Pretraining Efficiently on S2ORC) Dataset. Technical Report. Allen Institute for AI. ODC-By, https://github.com/allenai/pes2o.
- UNESCO and International Task Force on Teachers for Education 2030 (2024) UNESCO and International Task Force on Teachers for Education 2030. 2024. Global Report on Teachers: Addressing Teacher Shortages and Transforming the Profession. UNESCO, Paris. 187 pages. https://doi.org/10.54675/FIGU8035 CC BY-SA 3.0 IGO.
- Vachev et al. (2022) Kristiyan Vachev, Momchil Hardalov, Georgi Karadzhov, Georgi Georgiev, Ivan Koychev, and Preslav Nakov. 2022. Leaf: Multiple-choice question generation. In Proc. of the European Conf. on Information Retrieval.
- Wang et al. (2024) Shen Wang, Tianlong Xu, Hang Li, Chaoli Zhang, Joleen Liang, Jiliang Tang, Philip S. Yu, and Qingsong Wen. 2024. Large Language Models for Education: A Survey and Outlook. arXiv:2403.18105 [cs.CL] https://arxiv.org/abs/2403.18105
- Wang et al. (2018) Z. Wang, A. S. Lan, W. Nie, A. E. Waters, P. J. Grimaldi, and R. G. Baraniuk. 2018. QG-Net: A Data-Driven Question Generation Model for Educational Content. In Proceedings of the Fifth Annual ACM Conference on Learning at Scale (26–28 June 2018). London, UK.
- Yadav et al. (2023) Gautam Yadav, Ying-Jui Tseng, and Xiaolin Ni. 2023. Contextualizing problems to student interests at scale in intelligent tutoring system using large language models. arXiv preprint arXiv:2306.00190 (2023).
- Yudelson et al. (2013) Michael V. Yudelson, Kenneth R. Koedinger, and Geoffrey J. Gordon. 2013. Individualized Bayesian Knowledge Tracing Models. In Proc. of Artificial Intelligence in Education, H. Chad Lane, Kalina Yacef, Jack Mostow, and Philip Pavlik (Eds.).
- Zhang and Rettinger (2014) L. Zhang and A. Rettinger. 2014. Final Ontological Word-Sense Disambiguation Prototype. Deliverable D3.2.3. xLike Project.
- Zhang et al. (2021) Ruqing Zhang, Jiafeng Guo, Lu Chen, Yixing Fan, and Xueqi Cheng. 2021. A Review on Question Generation from Natural Language Text. ACM Trans. Inf. Syst. 40, 1, Article 14 (sep 2021), 43 pages. https://doi.org/10.1145/3468889
- Zhang et al. (2020) Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. arXiv:1904.09675 [cs.CL] https://arxiv.org/abs/1904.09675